




Das Document Object Model (DOM) für XML ist eine allgemeine Spezifikation des W3C zur Applikationsprogrammier-Schnittstelle (API). Das XML-DOM ist eine standardisierte Methode, auf Informationen, die in XML-Dokumenten gespeichert sind, zuzugreifen und sie zu verändern. Man beschreibt dazu Standardeigenschaften, Events und Methoden zur Verbindung von Anwendungscode und XML-Dokumenten. Heute erfahren Sie:
Das XML-DOM ist ein Objektmodell, das den Inhalt eines XML-Dokuments exponiert. Das impliziert, dass der Inhalt dann abgefragt und in einem gewissen Grad auch manipuliert werden kann. Die aktuelle Spezifikation des W3C zum Document Objekt Model definiert, welche Eigenschaften, Methoden und Events das DOM exponieren sollte. Die W3C-Spezifikation finden Sie unter http://www.w3.org/DOM/.
![]()
Ein Ausschnitt aus http://www.w3.org/DOM/ sagt zum DOM Folgendes: »Das Document Object Model ist eine plattform- und sprachunabhängige Schnittstelle, die es Programmen und Scripts erlaubt, auf Inhalt, Struktur und Stil von Dokumenten dynamisch zuzugreifen und sie zu aktualisieren. Das Dokument kann weiterverarbeitet und das Resultat dieser Verarbeitung wieder in die präsentierte Seite eingebaut werden.«
Dieses Kapitel wird Ihnen Gelegenheit geben, Scripts zu erstellen, die das DOM verwenden, auch wenn nicht beabsichtigt ist, Sie in JavaScript zu unterrichten. Wenn Sie mehr über die Sprache JavaScript wissen wollen, empfehlen wir Ralph Steyers Buch, JavaScript in 21 Tagen, erschienen bei Markt+Technik, ISBN: 3-8272-5884-7.
Die Struktur eines XML-Dokuments wird häufig mit einem Baum verglichen, der verschiedene Knoten hat. Beide Strukturen setzen sich aus einer Reihe von Formen zusammen, bei denen jeder passend ausgewählte Teil einem vorgegebenen größeren oder kleineren Teil ähnelt. Anders gesagt, die Konstrukte der strukturellen Komponenten und Beziehungen können sich wiederholen. In der Botanik entsprechen die Knoten eines Baums den einzelnen Zweigen, der Wurzel und dem Stumpf und am Ende stehen das Laub, die Frucht oder die Nuss. Die End-Knoten haben keine abgeleiteten Knoten mehr. Zweige können dagegen abgeleitete Zweige haben, von denen sich wiederum weitere Zweige ableiten können. Das kann sich ständig so fortsetzen. Sie wissen aus Ihren Studien der vergangenen Tage, dass dieses Modell eine nützliche Parallele zur Dokumentstruktur bei XML hat, die sich aus Elementknoten, Attributsknoten, Textknoten, Kommentarknoten und den Knoten der Verarbeitungsanweisungen zusammensetzt. Stellen Sie sich Laub, Nuss und Frucht - die Terminatoren beim Baum, die keine abgeleiteten Knoten haben können - als Parallelkonstrukte zu Attributsknoten und Textdatenknoten in einem XML-Dokument vor, die ebenfalls keine abgeleiteten Knoten haben. Wenn Sie eine Referenz auf die Ableitung oder den Stamm eines beliebigen Knotens einrichten, können Sie den Baum rekursiv hinaufklettern und einen beliebigen Dokumentteil erreichen. Das DOM erweitert diese relative Struktur und stellt jeden Knotentyp als Objekt mit einem eigenen Satz an Eigenschaften und Methoden heraus. Das DOM definiert eine Objekthierarchie. Jeder Knoten des Dokumentbaums kann eine beliebige Anzahl abgeleiteter Knoten haben und alle Knoten außer dem Wurzelknoten haben einen Stammknoten. Jeder Knoten ist sequenziell nummeriert und kann benannt werden. Die DOM-Spezifikation stellt einem Entwickler eine Reihe von Möglichkeiten zur Verfügung, wie er diesen generischen Dokumentbaum verwenden kann.
Der Knoten ist also die kleinste Einheit in der hierarchischen Dokumentstruktur von XML. Das Knotenobjekt ist ein einzelner Knoten im Dokumentbaum und das Dokumentobjekt ist der Wurzelknoten des Dokumentbaums.
Tabelle 12.1 fasst die Liste der Knoten zusammen, die für das XML-DOM zur Verfügung stehen.
Tabelle 12.1: Knoten im XML-DOM
Das W3C hat verschiedene Ebenen für das DOM festgelegt. Die erste Ebene konzentriert sich auf die primären oder Kern-Dokumentmodelle für die HTML- und XML- Programmierung von Dokumenten. Auf dieser Ebene gibt es genügend Funktionalität für die Dokument-Navigation und -Manipulation. Heute werden Sie fast ausschließlich mit dem DOM der ersten Ebene zu tun haben.
Die Ebene 2 des DOM enthält ein Modell für Stylesheet-Objekte. Wenn Sie dem Dokument Style-Informationen anfügen, können Sie die Informationen zur Präsentation manipulieren, die einem Dokument zugeordnet sind. Ebene 2 stellt eine Methode bereit, wie man das Dokument mittels eines Eventmodells durchquert und bietet eine Unterstützung für die XML-Namensräume. Sie werden morgen das einfache API für XML als Eventmodell für die Dokumentdurchquerung kennen lernen.
Das W3C erwartet eine dritte Ebene des DOM, die sich an das Laden und Speichern von Dokumenten wendet, denen Informationen zum Inhaltsmodell zugewiesen wurden, wie etwa DTDs oder andere Schemata. Ebene 3, die noch nicht vollständig vorliegt, soll die Validierung unterstützen, ebenso wie die Dokumentformatierung, Schlüsselevents und Eventgruppen. Weitere Informationen finden Sie im öffentlichen Arbeitsentwurf unter http://www.w3.org/DOM/.
Über die dritte Ebene hinaus ist beabsichtigt, dass das DOM generische Fenster für Systemaufrufe der Betriebssysteme von Microsoft, Unix und Macintosh enthalten soll. Außerdem werden zusätzliche Funktionsmerkmale diskutiert, darunter befinden sich:
Andere DOMs, die sich auf bestimmte Auszeichnungssprachen oder Dialekte konzentrieren, werden zunehmend populär. Bei Scalable Vector Graphics (SVG) etwa - damit werden zweidimensionale, mathematisch erzeugte Vektorgrafiken für das XML- Vokabular beschrieben -, steht dem Programmierer ein SVG-DOM zur Verfügung. Das W3C hat SVG als Auszeichnungssprache eingeführt, die drei Typen von grafischen Objekten zulässt: Vektorgrafik-Formen (Pfade, die aus geraden Linien und Kurven bestehen), Bilder und Text. Die grafischen Objekte können gruppiert, formatiert, umgewandelt und mit vorher gerenderten Objekten zusammengesetzt werden.
Das DOM gibt Entwicklern eine Methode zur Hand, wie sie einen Informationskörper, der als Text gespeichert ist, kontaktieren und mit ihm kommunizieren können. Das hat für die Entwicklung des Webs eine besondere Bedeutung, wo sich bislang statische Dokumente zu Anwendungen entwickeln. Auf diese Weise wird das Dokument zu einer Oberfläche für Anwenderinformationen, ähnlich einer Zeitung oder Zeitschrift, aber mit der zusätzlichen Möglichkeit, die Datenübertragung modifizieren und anwenderspezifisch definieren zu können. HTML ist in seiner Grundform nichts weiter als eine Methode, wie man statische Informationen in einem Browserfenster darstellt. Funktionalität und Design der Präsentationsoberfläche sind dem Browser eingebaut und lassen wenig Spielraum für den Entwickler, die Dinge zu steuern. Dynamisches HTML (DHTML) bietet Entwicklern eine Methode, die Präsentation und Datenübermittlung im Web zu steuern, normalerweise mit Hilfe von Scriptsprachen wie JavaScript oder VBScript in Verbindung mit Cascading Stylesheets (CSS). DHTML muss man sich als Webinhalt vorstellen, der mit Scripts und zusätzlichen Stylesheets implementiert wird.
Allgemein gesagt bietet ein Objektmodell eine Oberstruktur, die dynamische Verhaltensweisen unterstützt, indem sie Methoden für Objekte herausstellt, die das Modell repräsentieren. Wenn Sie JavaScript oder VBScript kennen, wissen Sie wahrscheinlich bereits über Methoden, Events und Objekte Bescheid. Bis zur Generation der 4.0-Browser, die Dynamisches HTML einführten, konnte JavaScript keine Dokumentinhalte aufrufen und manipulieren - jedenfalls nicht im allgemeinen Sinn. Netscape und Microsoft haben bei der Veröffentlichung ihrer Browser der 4.0-Version ihre jeweils eigenen Objektmodelle für Dokumente eingeführt. Leider waren die Implementierungen der beiden Hersteller nicht identisch. Der Gedanke hinter der Entwicklung der Spezifikation für die erste Ebene beim W3C war, dass das DOM-API plattformunabhängig sein sollte und von jeder gewöhnlichen Objektfamilie implementiert werden könnte. Mit dem Fortschreiten der Browsertechnik wird dies immer selbstverständlicher, aber man sollte wissen, dass es bei den DOM-Implementierungen immer noch Unterschiede zwischen Netscape und Microsoft gibt. Microsoft etwa erweitert den DOM-Standard des W3C mit Methoden, die Netscape-Browser nicht umsetzen können.
Das DOM liefert und exponiert eine organisierte Struktur für Objekte und Scripts, die man verwenden kann, um auf die Knoten dieser Struktur zuzugreifen und sie zu manipulieren. Ein Script kann auf einen Knoten in seiner absoluten oder relativen Position verweisen, etwa auf den ersten Knoten in der Dokumentstruktur. Ein Script kann einen Knoten auch einfügen oder entfernen. Damit kann der Inhalt, den jeder Knoten repräsentiert, dargelegt oder als Teil einer Anwendung aktualisiert werden. Das macht aus DOM-Objekten strukturierte und eindeutig identifizierbare Container. Die Verhaltensweisen, die von Scripts erzwungen werden, bieten Ihnen daher ein Mittel zur Manipulation dieser Container-Objekte und ihres Inhalts.
Das Dokumentobjekt ist der Wurzelknoten-Container für alle anderen Objekte, die im XML-Dokument definiert werden. Das Dokumentobjekt bietet einen Zugriff auf die Dokumenttyp-Definition (DTD) und exponiert die abgeleiteten Elemente innerhalb der Dokumentstruktur. Auf der Wurzelebene des Dokuments liegt der Wurzelelementknoten, der sich vom echten Wurzelknoten des Dokuments unterscheidet. Der Dokumentbaum ist eine geordnete Ansammlung von Knoten, die man adressieren kann - das haben Sie am 9., 10. und 11. Tag gelernt. Da man die Objekte im Baum identifizieren kann, kann man auf sie und ihren Inhalt auch verweisen. Mit JavaScript etwa können Sie folgendermaßen auf den Text verweisen, den der erste abgeleitete Knoten des Dokuments enthält:
meinedinge.dokumentElement.childNodes.punkt(0).text
Das sieht auf den ersten Blick ziemlich komplex aus, ist aber in Wahrheit absolut logisch. Das Dokument meinedinge enthält ein dokumentElement mit childNodes. Diese Reihe verweist auf den ersten dieser abgeleiteten Knoten (punkt(0)) und der Text, den dieser Knoten enthält, ist das Ziel aller folgenden Script-Aktionen oder -Verhaltensweisen. Sie erkennen sicher, dass die Zählung der Punktanzahl mit Null beginnt; das ist typisch für Scriptsprachen.
Wie Sie wissen ist eine der Stärken von XML, dass Sie Ihren eigenen Elementsatz erstellen können. Auf diese Weise können Sie Objekte auf Grundlage der Semantik einer Applikation erzeugen und dann unter Verwendung von Scripts auf diese Objekte zugreifen. Normalerweise werden Sie mehr wissen wollen als die numerische Anordnung des Objekts oder seinen Namen. Sie wollen wahrscheinlich wissen, in welchem Kontext im Dokument sich das Objekt befindet. Deshalb sucht ein Script nach den Objektbeziehungen und ermittelt den Kontext für das Objekt im Dokument.
Mit dem DOM ist es möglich, die Objekthierarchie zu durchqueren. Anders gesagt, wenn Sie ein Objekt als Ausgangspunkt haben, können Sie folgende Dinge bestimmen:
Sie haben gesehen, dass die DOM-Spezifikation darauf abzielt, eine allgemeine Schnittstelle (API) für Entwickler bereitzustellen, die Sie bei der Manipulation von Dokumentobjekten verwenden können. Das API bietet den Angriffspunkt, den ein Entwickler verwenden kann, um auf Objekte und Methoden zu verweisen. Die bedeutendsten Herstellerfirmen für Anwendungssoftware haben Implementierungen des DOM für bestimmte Sprachen bereitgestellt. Das dahinterstehende Konzept besagt, dass das DOM-API unabhängig von der Sprache abgelegt sein soll, mit der es implementiert wird. Das heißt, dass die Implementierungen bei Java, C, C++, C#, JavaScript, Visual Basic, VBScript, Perl usw. sich stark ähneln sollten.
Damit dieser plattformunabhängige Ansatz Wirklichkeit wird, muss das DOM mit einer relativen generischen Beschreibungssprache spezifiziert werden. Die DOM-Spezifikation des W3C verwendet eine Sprache, die als Interface Definition Language (IDL) bekannt ist, um die Natur der Schnittstelle zu beschreiben, die von einer DOM-Implementierung zu erwarten ist. IDL ist ein Standard (ISO-Standard 14750), den eine Arbeitsgruppe namens Object Management Group entwickelt hat. Mehr Informationen über IDL finden Sie unter http://www.omg.org/.
Sie haben vorhin von all den Knoten erfahren, die das DOM exponiert; die meisten Programmierer benutzen aber zunächst hauptsächlich drei primäre API-Typen. Diese primären APIs sind der Knoten-Knoten, der Dokument-Knoten und der Element-Knoten. Da man diese Knoten am häufigsten antrifft, können Sie die meisten Programmieraufgaben auch mit diesen drei API-Typen vollbringen. Sie erinnern sich bestimmt, dass der Knoten-Knoten der Basistyp für die meisten Objekte beim DOM ist. Er kann eine beliebige Anzahl abgeleiteter Knoten und einen Stammknoten haben. Tatsächlich ist es die Regel, dass er einen Stammknoten hat, außer in den Fällen, wo er den Wurzelknoten in der Dokumenthierarchie beschreibt. Der Wurzelknoten hat keinen Stamm.
Das Element-Knotenobjekt wird verwendet, um Elemente im XML-Dokument zu repräsentieren. Sie wissen, dass Elemente einen Textinhalt haben können (zum Beispiel den Zeichenstring zwischen Start- und Schluss-Tag des Elements), weiteren Elementinhalt und Attribute, die das Element modifizieren. Elementobjekte haben eine Liste von Attributsobjekten, die eine Kombination der Attribute darstellen, die in der Dokument-Instanz ausgedrückt werden, und derjenigen, denen ein zugeordnetes Schema Standardwerte zuweist, ob diese nun in der XML-Instanz programmiert sind oder nicht.
Das Dokument-Objekt repräsentiert den Wurzelknoten eines Dokuments. Somit hat es keinen Stamm. Deshalb gibt ein Aufruf mit der Script-Methode (z.B. getParentNode()), der über das API durchgeführt wird, um den Stammknoten für einen Dokumentknoten zu erhalten, einen Nullwert zurück.
Das DOM kann auf verschiedene Art und Weise über Parser, die die DOM-Verarbeitung unterstützen, instanziert werden. Für die Übungen, die Sie heute durchführen werden, werden der MSXML-Parser und JavaScript verwendet. Die heutigen Beispiele verwenden einen Ansatz, der sich auf die Implementierung im Microsoft Internet Explorer beschränkt. Auch wenn der Internet Explorer für eine Reihe von Plattformen und Betriebssysteme zur Verfügung steht, werden nicht alle Besucher einer Website diese Software haben. Deshalb sollten Sie einige der Techniken, die Sie heute kennen lernen, als lehrreich für den DOM- Zugriff betrachten, aber nicht notwendigerweise als durchführbar für die Webimplementierung. Sie können den Microsoft Internet Explorer für die Betriebssysteme Unix, DOS, Macintosh und Windows kostenlos unter http://www.microsoft.com herunterladen. Die Prinzipien, die Sie heute kennen lernen, lassen sich auch auf andere DOM-Implementierungen anwenden.
Um diesen Nachteil auszugleichen, gibt es viele Implementierungen des DOM für eine Reihe von Prozessoren und Scripting-Methoden. Wenn Sie andere Scripting- oder Applikations-Entwicklungssprachen kennen, finden Sie Methoden zum Zugriff auf DOM- Objekte im Web oder als Link auf der Informationsseite zum W3C-DOM (http:// www.w3.org/DOM/). Sie finden Links auf die DOM-Implementierungen von PERL, Java, Python und verschiedenen anderen beliebten Sprachen, die eine Reihe von Plattformen unterstützen.
Die meisten DOM-Implementierungen haben gemeinsame funktionale Merkmale. Das DOM bietet Ihnen eine Schnittstelle zum Laden, für den Zugriff und für die Manipulation von XML-Dokumenten. Morgen werden Sie das einfache API für XML (SAX) kennen lernen, ein eventgetriebenes Modell. Der Hauptunterschied zwischen diesen beiden Ansätzen ist, dass das DOM eine gesamte Dokument-Instanz auf einmal in den Speicher lädt, während SAX einen einzelnen Event verarbeitet, etwa einen Knoten, und dann zum nächsten Event in der Dokumentanordnung weitergeht.
Wenn ein Parser, der das DOM unterstützt, ein Dokument parst, wird eine Baumstruktur aufgebaut und zum Lese- und Schreibzugriff für Scripts oder Applikationssprachen bereitgestellt. Wenn der Objektbaum erzeugt ist, bearbeitet der Parser ihn und erlaubt damit einem Programmierer, die Methoden zu verwenden, die in den Parser eingebaut sind, statt eine einmalige Logik erzeugen zu müssen. Wenn der gesamte Dokumentbaum auf einmal gespeichert wird, ist ein willkürlicher Zugriff auf alle Knoteninhalte möglich. Abbildung 12.1 zeigt die Beziehung zwischen dem XML-Dokument, dem XML-Parser, dem DOM-Baum, den der Parser erzeugt, und der Applikation oder dem Script, die Lese- und Schreibzugriff auf die exponierten Objekte haben. Wenn der Parser ein XML- Dokument in ein DOM lädt, liest er es in seiner Gesamtheit und erzeugt einen Knotenbaum, der dann als Ganzes oder in Teilen für die Methoden zur Verfügung steht, die die diversen Applikationsentwicklungssprachen und Scriptsprachen implementieren. Das Dokument wird als einzelner Knoten betrachtet, der alle anderen Knoten und ihren jeweiligen Inhalt enthält.
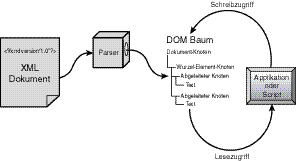
Abbildung 12.1: Das von einem Parser implementierte DOM exponiert Objektknoten für ein Script oder eine Applikation.
Um mit dem Scripting für einen DOM-Baum anfangen zu können, müssen Sie zunächst das Dokumentobjekt erstellen. Wenn Sie das mit JavaScript und dem MSXML-DOM- Parser tun, müssen Sie auch ein neues ActiveXObject erzeugen, das die Component Object Model (COM)-Komponente instanziert, die Teil der Verteilerbibliothek ist, die auf dem Microsoft Internet Explorer 5.0 oder höher installiert ist. Das ActiveXObject heißt in der COM-Bibliothek XMLDOM. Der JavaScript-Code sieht so aus:
Var oMeinedinge=New ActiveXObject("Microsoft.XMLDOM")
Dieses Script erzeugt ein neues ActiveXObject für das Dokument, das auf der COM- Komponente des Microsoft XMLDOM basiert, das wiederum Teil der MSXML-Parser-Suite ist. Das Dokumentobjekt wird in einer Variablen mit dem Namen oMeinedinge platziert. Per Konvention wird ein kleingeschriebenes o verwendet, um eine Variable anzuzeigen, die ein Objekt repräsentiert.
Sie wissen vielleicht, vor allem wenn Sie Visual Basic-, Java- oder Visual C++-Entwickler sind, dass das Component Object Model (COM) das Erstellen integraler Softwarekomponenten ermöglicht, die unabhängig von der Programmiersprache sind und einen offen gelegten Standort haben. Das heißt Sie können mit jeder Sprache auf den MSXML-Parser zugreifen, die eine COM-Komponente instanzieren kann. Auch wenn Sie heute für die meisten Scripting-Übungen JavaScript verwenden, können Sie die Übungen für die Verwendung von VBScript umschreiben, indem Sie das DOM instanzieren und ein Dokumentobjekt mit der VBScript-Methode CreateObject erstellen. Das sieht so aus:
Set oMeinedinge=CreateObject("Microsoft.XMLDOM")
Dieser VBScript-Code ist dem JavaScript-Code funktional äquivalent. Er erzeugt ebenfalls ein Dokumentobjekt auf Grundlage der gleichen COM-Komponente im MSXML-Parser- Paket. Das Dokumentobjekt wird in der Variablen namens oMeinedinge platziert.
Beide Beispiele erzeugen Objekte, die für das clientseitige Scripting verwendet werden. Die meisten der heutigen Übungen beinhalten clientseitiges DOM-Scripting; Sie können aber mit dem gleichen Ansatz auch ein Objekt auf einer Active Server Page (ASP) für das serverseitige Scripting erzeugen. Das VBScript auf einer ASP-Seite, das ein Dokumentobjekt für das serverseitige Scripting erzeugt, sieht wie folgt aus:
Set oMeinedinge=Server.CreateObject("Microsoft.XMLDOM")
Dieser VBScript-Code funktioniert genauso wie die vorherigen Beispiele. Er erzeugt ein serverseitiges ASP-Dokument (Server.CreateObject) auf Grundlage der COM- Komponente im MSXML-Parser-Paket. Das Dokumentobjekt wird in der Variablen namens oMeinedinge abgelegt.
Das Microsoft XML-DOM besteht hauptsächlich aus vier Objekten: XMLDOMDocument, XMLDOMNode, XMLDOMNodeList und XMLDOMNameNodeMap. Andere Implementierungen des XML-DOM, die über den Bereich der heutigen Besprechung hinausgehen, verwenden andere Objekte, die von der Sprache abhängig sind, die sie implementiert. Jedes Objekt hat seine eigenen Eigenschaften, Methoden und Events. Wenn Sie die Grundlagen der objektorientierten Programmiermodelle (OOP) nicht kennen oder die Einteilung in Eigenschaften, Methoden und Events verwirrend finden, können Sie etwas darüber im Online-Tutorial von Sun Microcomputers unter http://java.sun.com/docs/books/ tutorial/java/concepts/object.html nachlesen.
Heute werden wir das XMLDOMDocument-Objekt verwenden. Einige der üblicherweise verwendeten Eigenschaften, Methoden und Events für dieses Objekt werden in den Tabellen 12.2 bis 12.4 aufgelistet. Dieser Satz wird durch die Microsoft-Implementierung des DOM-Objekts verfügbar gemacht. Andere Implementierungen können diverse hier nicht aufgelistete Bestandteile haben oder einige derjenigen ausschließen, die Microsoft als Erweiterung zum DOM bereitstellt.
Tabelle 12.2: Allgemein verwendete Eigenschaften von XMLDOMDocument
Tabelle 12.3: Methoden von XMLDOMDocument
Sie wissen aus Tabelle 12.2, dass man die load()-Methode verwenden kann, um ein XML- Dokument in ein DOM-Dokumentobjekt zu laden, wobei die Knoten des XML- Dokuments für das Scripting exponiert werden. Die JavaScript-Methode für die Programmierung hat folgende Syntax:
oMeinedinge.load('dateiname.xml')
Das Objekt oMeinedinge, das in einem vorhergehenden Schritt erzeugt wurde, wird jetzt mit dem Inhalt von dateiname.xml geladen.
Normalerweise werden Sie sicherstellen wollen, dass der Parser anhält, während das Dokument vom DOM-Parser in das Objekt geladen wird. Dazu müssen Sie die Eigenschaft async mit dem Wert false für das Objekt eingeben, das erzeugt wird. Die JavaScript-Syntax für diese Eigenschaft lautet:
oMeinedinge.async="false"
Die Eigenschaft async wird auf false gesetzt, um einen asynchronen Download zu verhindern, wodurch der Prozessor angehalten wird, bis die gesamte Instanz in den Speicher geladen ist.
Jetzt wissen Sie genug, um die passende Objekterzeugung, die Methoden und Eigenschaften zusammenzufügen, mit denen ein XML-Dokument in das DOM geladen werden kann. Wenn Sie JavaScript verwenden, müssen Sie ein ActiveXObject für den Dokumentknoten erzeugen und der Eigenschaft async den Wert false zuweisen. Dann laden Sie das Dokument aus der URL. Die Syntax für diese Eingabe lautet:
1: var oMeinedinge = new ActiveXObject("Microsoft.XMLDOM")
2: oMeinedinge.async="false"
3: oMeinedinge.load("nachricht01_12.xml")
![]()
Das neue Objekt wird in Zeile 1 als Instanz des Microsoft XML-Parsers erzeugt und oMeinedinge genannt. Zeile 2 stellt sicher, dass der Parser die Ausführung anhält, bis das gesamte XML-Dokument in den Speicher für das Objekt geladen wurde. Zeile 3 liefert die load-Methode mit einer gültigen URL für das Dokument, das geladen werden soll.
Um dieses Scripting auszutesten, erzeugen Sie zunächst eine einfache XML-Instanz. Listing 12.1 zeigt dieses Dokument, das als nachricht01_12.xml gespeichert ist; Sie können es kopieren, wenn Sie das Dokument der früheren Tage nicht mehr griffbereit haben. Der einzige Unterschied zwischen diesem Listing und dem Listing vom 11. Tag ist der Kommentar in Zeile 2, der anzeigt, das dieses Listing am 12. Tag als Listing 12.1 angezeigt wird:
Listing 12.1: Ein einfaches XML-Dokument - nachricht01_12.xml
1: <?xml version = "1.0"?>
2: <!-- listing 12.1 - nachricht01_12.xml -->
3:
4: <notiz>
5: <nachricht ID="m1" von="Kathy Shepherd">
6: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
7: </nachricht>
8: <nachricht ID="m2" von="Greg Shepherd">
9: Ich brauche ein wenig Hilfe bei den Hausaufgaben
10: </nachricht>
11: <nachricht ID="m3" von="Kristen Shepherd">
12: Bitte spiele heute Abend Scribble mit mir
13: </nachricht>
14: </notiz>
Das notiz-Element enthält mehrere abgeleitete nachricht-Elemente, die nur Textinhalt haben. Jedes nachricht-Element hat ID- und von-Attribute.
Als Nächstes platzieren Sie die vorher beschriebenen Scripts in einer HTML- Dokumentstruktur, um die Datei nachricht01_12.xml zur weiteren Verarbeitung in ein DOM-Objekt laden zu können. Für die Datei nachricht01_12.xml sieht das so aus:
1: </head>
2: <script language="javascript">
3: <!-Script vor alten Browsern verbergen
4: var oMeinedinge = new ActiveXObject("Microsoft.XMLDOM")
5: oMeinedinge.async="false"
6: oMeinedinge.load("nachricht01_12.xml")
7: -->
8: </script>
9: </head>
![]()
Dieser Codeausschnitt enthält ein Script, das in Zeile 2 beginnt und in den <head>-Abschnitt (Zeilen 1-9) der HTML-Seite eingefügt ist. Zeile 2 deklariert die Scriptsprache (language="javascript") mit dem language-Attribut für das script-Element. Zeile 3 beginnt einen Kommentar, der bewirkt, dass das gesamte Script vor älteren Browsern, die kein JavaScript unterstützen, verborgen wird. Die Zeilen 4-6 erzeugen das Dokumentobjekt und die Schritte zum Laden von XML, die wir bereits ausführlich besprochen haben. Die Zeilen 7, 8 und 9 beenden jeweils den Kommentar, das Script und den Head-Abschnitt.
Damit wird nur das Dokument geladen und die Knoten zur weiteren Verarbeitung exponiert. Angenommen, Sie wollen den Textinhalt des XML-Dokuments an den Bildschirm zurückgeben, wozu Sie den JavaScript-Befehl alert verwenden. Sie können dies ganz einfach tun, indem Sie dem Script-Abschnitt des Dokuments ein alert hinzufügen. Um sicherzustellen, dass der Dateirumpf-Abschnitt Ihrer HTML-Seite nicht ganz leer ist, können Sie jetzt auch einen kurzen Text eingeben. Listing 12.2 zeigt eine fertige HTML-Seite, die sich auf die beschriebene Weise verhält, wenn sie in den Microsoft Internet Explorer 5.0 oder höher geladen wird. Erstellen Sie diese Seite und speichern Sie sie unter DOM01.html; dann laden Sie sie in den IE.
Listing 12.2: Ein Beispiel für das DOM-Scripting - DOM01.html
1: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
2: <!-- listing 12.2 - DOM01.html -->
3:
4: <html>
5: <head>
6: <title>DOM Scripting</title>
7: </head>
8: <script language="javascript">
9: <!--Script vor alten Browsern verbergen
10: var oMeinedinge = new ActiveXObject("Microsoft.XMLDOM")
11: oMeinedinge.async="false"
12: oMeinedinge.load("nachricht01_12.xml")
13: alert(oMeinedinge.text);
14: -->
15: </script>
16: </head>
17: <body>
18: Fertig!
19: </body>
20: </html>
![]()
Sie kennen bereits die meisten Bestandteile dieses Listings. Die Zeilen 8-15 enthalten das Script, das das DOM-Objekt erzeugt (Zeile 10) und das XML-Dokument lädt (Zeile 12). Zeile 13 enthält den JavaScript-alert. Bei der Ausführung hält alert das Parsen der HTML-Seite an und gibt eine Meldung auf den Bildschirm aus, die den gesamten Textinhalt des Objekts Meinedinge enthält. Das Objekt enthält in diesem Fall die gesamte Dokument-Instanz, also wird der ganze Textinhalt des Dokumentknotens und all seiner abgeleiteten Knoten (zum Beispiel Unterbäume) eingeschlossen. Zeile 18 enthält den Text Fertig!, der angezeigt wird, wenn das Script beendet ist und der Anwender die alert-Meldung gelöscht hat.
Wenn Sie diese HTML-Seite im IE austesten, müsste sie eine alert-Meldung erzeugen, die so aussieht wie in Abbildung 12.2. Diese Meldung listet den Textinhalt des XML- Dokuments auf, was den Zeilen 6, 9 und 12 von Listing 12.1 entspricht.
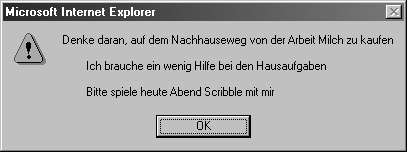
Abbildung 12.2: Eine JavaScript-alert-Meldung gibt den Textinhalt eines XML-Dokuments zurück
Nehmen wir an, Sie wollen die Resultate an die HTML-Seite zurückgeben, anstatt die alert-Meldung von JavaScript anzuzeigen. Sie können dies auf unterschiedliche Weise tun. Sie können zum Beispiel alert entfernen und mit der JavaScript-Methode document. write in einem eigenen Script auf das Objekt im Rumpf der HTML-Seite verweisen. Wenn Sie diese Methode verwenden, können Sie ein zweites Script im Rumpf der HTML- Seite erzeugen, das das Objekt oMeinedinge aufruft und den Textinhalt des Dokumentknotens und aller Unterbaumknoten zurückgibt. Listing 12.3 zeigt ein Mittel, um dies zu erreichen. Der Ansatz funktioniert, aber Sie werden sehen, dass er nicht völlig effizient oder praktisch ist. Modifizieren Sie die HTML-Seite, die Sie vorhin erzeugt haben, und speichern Sie sie unter DOM02.html, sodass sie aussieht wie das Listing.
Listing 12.3: Der Textinhalt eines XML-Dokuments wird an die HTML-Seite zurückgegeben - DOM02.html.
1: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
2: <!-- listing 12.3 - DOM02.html -->
3:
4: <html>
5: <head>
6: <title>DOM Scripting</title>
7: <script language="javascript">
8: <!--Script vor alten Browsern verbergen
9: var oMeinedinge = new ActiveXObject("Microsoft.XMLDOM")
10: oMeinedinge.async="false"
11: oMeinedinge.load("nachricht01_12.xml")
12: -->
13: </script>
14: </head>
15: <body>
16: <script language="javascript">
17: <!--Script vor alten Browsern verbergen
18: document.write
19: ("<h2>Der Textinhalt der XML-Datei enthaelt:</h2>")
20:
21: document.write
22: (oMeinedinge.text)
23:
24: document.write
25: ("<hr />")
26: -->
27: </script>
28: </body>
29: </html>
![]()
Das erste Script in diesem Listing (Zeilen 7-13) ähnelt dem in Listing 12.2, nur dass JavaScript-alert ausgelassen wurde. Ein zweites Script wird im Rumpf der HTML-Datei in den Zeilen 16-27 erzeugt. Die Zeilen 18-19 schreiben den String <h2>Der Textinhalt dieser XML-Datei enthaelt</h2> auf die Seite. Da der String eine HTML-Auszeichnung enthält (H2), wird er entsprechend ausgegeben, wie ein Überschrift-String der Ebene 2. Die Zeilen 21-22 schreiben das Resultat für das Einfügen der text-Eigenschaft in das Objekt oMeinedinge (zum Beispiel den ganzen Textinhalt des Dokumentknotens und seiner jeweiligen Unterbaumknoten). Die Zeilen 24-25 ergeben einfach eine horizontale Linie, die so breit ist wie das Browserfenster in der Browseranzeige. Zeile 27 schließt das zweite Script.
Die letzte Übung gab einen zusammenhängenden String zurück, der den ganzen Textinhalt für das gesamte Dokument umfasst. Nehmen wir an, Sie wollen nur den Textinhalt des zweiten abgeleiteten Knotens im Dokument anzeigen. Ein kurzer Blick auf das XML-Dokument (Listing 12.1) zeigt, dass der zweite Text enthaltende Knoten das zweite nachricht-Element ist. Das zweite nachricht-Element hat den Inhalt Ich brauche ein wenig Hilfe bei den Hausaufgaben. Um einen Knoten durch seinen Ordinalwert zu identifizieren und auszuwählen, müssen Sie Eigenschaften verwenden, die numerische Sub-Eigenschaften zulassen. In dieser Übung sollen Sie den Text zurückgeben, den der zweite abgeleitete Elementknoten vom Stamm des Dokumentelements enthält. Dies kann in JavaScript mit dem folgenden Ausdruck erfolgen:
oMeinedinge.documentElement.childNodes.item(1).text
Beachten Sie, dass Sie die item-Eigenschaft mit dem Wert 1 eingeben müssen, um den zweiten abgeleiteten Knoten auszuwählen. Das ist deshalb nötig, weil Aufzählungen in den Eigenschaftswerten von JavaScript immer bei Null als der ersten gezählten Instanz beginnen, gefolgt von Eins, Zwei usw. Deshalb müssen Sie die item-Eigenschaft auf den Wert 1 setzen, um den zweiten abgeleiteten Knoten auswählen zu können.
In diesem Beispiel verbessern Sie die Programmierung außerdem, indem Sie die beiden vorherigen Scripts zu einem zusammenfügen. Platzieren Sie das kombinierte Script zur Erleichterung der Implementierung im Rumpfabschnitt der HTML-Seite. Listing 12.4 zeigt die fertige HTML-Seite, gespeichert unter DOM03.html.
Listing 12.4: Der Textinhalt des Knotens wird durch seine Ordinalposition ausgewählt - DOM03.html
1: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
2: <!-- listing 12.4 - DOM03.html -->
3:
4: <html>
5: <head>
6: <title>DOM Scripting</title>
7: </head>
8: <body>
9: <script language="javascript">
10: <!--
11:
12: var oMeinedinge = new ActiveXObject("Microsoft.XMLDOM")
13: oMeinedinge.async="false"
14: oMeinedinge.load("nachricht01_12.xml")
15:
16: document.write
17: ("<h2>Das ausgewaehlte XML-Element in der Datei enthaelt:</h2>")
18:
19: document.write
20: (oMeinedinge.documentElement.childNodes.item(1).text)
21:
22: document.write
23: ("<hr />")
24:
25: -->
26: </script>
27:
28: </body>
29: </html>
![]()
Das eine Script, das verwendet wird, um das XML-Dokument zu laden und zu verarbeiten, findet sich in den Zeilen 9-26 dieses Listings. Die Zeilen 12-14 enthalten die Objekt-Instanzierung und das Laden des XML-Dokuments. Die Zeilen 19-20 enthalten die Auswahl des Textinhalts aus dem zweiten abgeleiteten Knoten des Dokumentelements.
Angenommen, Sie wollen etwas über die Struktur des XML-Dokuments wissen, das Sie mit dem DOM exponiert haben, und Sie wollen den Textinhalt eines bestimmten Elements auswählen. Dieser Text kann das zweite nachricht-Element in Ihrem Dokument nachricht01.xml sein, der zufälligerweise das gleiche Resultat zurückgibt wie die Übungen, die Sie bereits fertig gestellt haben. Sie können dies erreichen, wenn Sie die Methode getElementsByTagName anwenden. Für das beschriebene Szenario sieht das so aus:
oMeinedinge.getElementsByTagName("nachricht").item(1).text
Dieser Ausdruck gibt den Textinhalt des zweiten (item(1)) nachricht-Elements zurück, das im oMeinedinge-Objekt enthalten ist.
Mit der document.write-Methode fügen Sie dies Ihrer HTML-Seite hinzu und speichern das Resultat unter DOM04.html. Listing 12.5 zeigt eine funktionierende Lösung.
Listing 12.5: Ein XML-Element wird nach seinem Namen ausgewählt - DOM04.html
1: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
2: <!-- listing 12.5 - DOM04.html -->
3:
4: <html>
5: <head>
6: <title>DOM Scripting</title>
7: </head>
8: <body>
9: <script language="javascript">
10: <!--
11:
12: var oMeinedinge = new ActiveXObject("Microsoft.XMLDOM")
13: oMeinedinge.async="false"
14: oMeinedinge.load("nachricht01_12.xml")
15:
16: document.write
17: ("<h2>Das ausgewaehlte XML-Element der Datei enthaelt:</h2>")
18:
19: document.write
20: (oMeinedinge.documentElement.childNodes.item(1).text)
21:
22: document.write
23: ("<br/><br/> Resultat durch Tag Namen:<br/>")
24:
25: document.write
26: (oMeinedinge.getElementsByTagName("nachricht").item(1).text)
27:
28: document.write
29: ("<hr />")
30:
31: -->
32: </script>
33:
34: </body>
35: </html>
![]()
Die Zeilen 25-26 fügen dem Script die neue Methode hinzu. Der Code gibt den Text zurück, den das zweite nachricht-Element im Dokumentobjekt enthält. Die Zeilen 22-23 wurden nur hinzugefügt, um die Resultate zu trennen und die zweite Rückgabe als Resultat durch Tag Namen zu identifizieren.
Eine besondere Eigenschaft beim DOM (parseError) enthält ein Objekt, das die Details über den letzten Parsing-Fehler dokumentiert, der während der Verarbeitung aufgetreten ist, und gibt es zurück. Wenn man ausgewählte Eigenschaften dieses Objekts eingibt, kann man eine effiziente Fehlerroutine erstellen, um XML-Dokumente mit DOM-Scripts auszutesten. Tabelle 12.5 listet die Eigenschaften des XMLDOMParseError-Objekts auf, das in der parseError-Eigenschaft des XMLDOMDocument-Objekts enthalten ist.
Tabelle 12.5: Eigenschaften des XMLDOMParseError-Objekts
Nehmen wir an, Sie wollen eine JavaScript-Routine schreiben, um ein XML-Dokument auszutesten. Wenn ein Fehler gefunden wurde, sollen der Code für den Grund, die fehlerhafte Zeilennummer, eine Beschreibung des angetroffenen Fehlers in englischer Sprache sowie die URL des fehlerhaften Dokuments zurückgegeben werden. Bei JavaScript können Sie die Eigenschaft parseError für Ihr Dokumentobjekt eingeben und die passenden XMLDOMParseError-Eigenschaften anhängen. Der Code sieht so aus:
1: document.write
2: ("<br>Fehler Grund Code: ")
3: document.write
4: (oMeinedinge.parseError.errorCode)
5:
6: document.write
7: ("<br>Fehler Zeile Nummer: ")
8: document.write
9: (oMeinedinge.parseError.line)
10:
11: document.write
12: ("<br>Fehler Grund Beschreibung: ")
13: document.write
14: (oMeinedinge.parseError.reason)
15:
16: document.write
17: ("<br>URL der Datei mit dem Fehler: ")
18: document.write
19: (oMeinedinge.parseError.url)
![]()
Die Zeilen 3-4 geben den errorCode zurück, wenn ein Parsing-Fehler beim Laden des XML-Dokuments in den Speicher auftritt. Die Zeilen 8-9 geben die Zeilenzahl zurück, die Zeilen 13-14 die URL des fehlerhaften XML-Dokuments.
Bei der nächsten Übung fügen wir diese Eigenschaften einem Script hinzu, um es auf Parsing-Fehler zu überprüfen. Ändern Sie die Lademethode für das Dokument in Ihrem Script so, dass Sie nach einer nicht existenten XML-Datei suchen, um einen Fehler zu erzwingen. Wenn das Script ausgeführt wird, sucht es nach der Datei und meldet einen Fehler, wenn die Datei nicht lokalisiert und geparst werden kann.
Listing 12.6 zeigt die HTML-Seite mit dem vollständigen Script. Erzeugen Sie Ihr Script nach dem angegebenen Beispiel und speichern Sie es unter DOMfehler01.html.
Listing 12.6: Ein Fehler-Script - DOMfehler01.html
1: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
2: <!-- listing 12.6 - DOMfehler01.html -->
3:
4: <html>
5: <head>
6: <title>DOM Scripting</title>
7: </head>
8: <body>
9: <script language="javascript">
10: <!--
11:
12: var oMeinedinge = new ActiveXObject("Microsoft.XMLDOM")
13: oMeinedinge.async="false"
14: oMeinedinge.load("falscher_dateiname.xml")
15:
16: document.write
17: ("<br>Fehler Grund Code: ")
18: document.write
19: (oMeinedinge.parseError.errorCode)
20:
21: document.write
22: ("<br>Fehler Zeilen Nummer: ")
23: document.write
24: (oMeinedinge.parseError.line)
25:
26: document.write
27: ("<br>Fehler Grund Beschreibung: ")
28: document.write
29: (oMeinedinge.parseError.reason)
30:
31: document.write
32: ("<br>URL der Datei mit dem Fehler: ")
33: document.write
34: (oMeinedinge.parseError.url)
35:
36: -->
37: </script>
38: </body>
39: </html>
![]()
Die Fehlerroutine wurde bereits detailliert beschrieben; in diesem Listing liegt sie in den Zeilen 16-34. Die Zeile 14 (oMeinedinge.load("falscher_dateiname. xml")) versucht, ein XML-Dokument zu laden, das nicht existiert. Das erzeugt einen Parsing-Fehler und gibt folgende Informationen an das Browserfenster zurück:
Fehler Grund Code: -2146697210
Fehler Zeilen Nummer: 0
Fehler Grund Beschreibung: Das angegebene Objekt konnte nicht gefunden werden.
URL der Datei mit dem Fehler: falscher_dateiname.xml
Meldungen zu Parsing-Fehlern vom XMLDOMParseError-Objekt sind in der Regel recht informativ. Um eine andere Meldung ansehen zu können, modifizieren Sie Ihr Dokument nachricht01.xml indem Sie die Groß- und Kleinschreibung in einem der nachricht- Element-Tags durcheinander bringen, und speichern das Dokument unter schlechte_ nachricht.xml. Listing 12.7 zeigt eine schlecht geformte XML-Instanz mit fehlerhafter Groß- und Kleinschreibung bei den Tags für ein nachricht-Element.
Listing 12.7: Eine schlecht geformte XML-Instanz - schlechte_nachricht.xml
1: <?xml version = "1.0"?>
2: <!-- listing 12.7 - schlechte_nachricht.xml -->
3:
4: <notiz>
5: <nachricht ID="m1" von="Kathy Shepherd">
6: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
7: </nachricht>
8: <nachricht ID="m2" von="Greg Shepherd">
9: Ich brauche ein wenig Hilfe bei den Hausaufgaben
10: </nachricht>
11: <Nachricht ID="m3" von="Kristen Shepherd">
12: Bitte spiele heute Abend Scribble mit mir
13: </nachricht>
14: </notiz>
![]()
Das dritte Nachricht-Element (Zeilen 11-13) hat ein Start-Tag mit einem großgeschriebenen N und ein Schluss-Tag mit kleingeschriebenem m. Das führt zu einem Parsing-Fehler, wenn das Dokument in das DOM-Dokumentobjekt geladen wird.
Um sich das Ergebnis eines Parsing-Fehlers wie in Listing 12.7 ansehen zu können, ändern Sie Zeile 14 Ihres DOMfehler01.html-Dokuments, um schlechte_nachricht.xml zu laden. Die Zeile, mit der Sie das tun können, sieht folgendermaßen aus:
14: oMeinedinge.load("falscher_dateiname.xml")
Wenn das Script ausgeführt wird, müssen Sie eine Fehlermeldung im Browserfenster erhalten, die etwa so aussieht:
Fehler Grund Code: -1072896659
Fehler Zeilen Nummer: 13
Fehler Grund Beschreibung: Schluss-Tag 'nachricht passt nicht
zum Start-Tag 'Nachricht.
URL der Datei mit dem Fehler: schlechte_nachricht.xml
Auf Grund dieser Fehlermeldung wissen Sie jetzt, wie man das XML-Dokument korrigieren kann, damit es wieder wohl geformt ist. Diese Art der Fehlerüberprüfung kann relativ leicht in fast alle XML-Verarbeitungsanwendungen eingebaut werden.
Heute haben Sie das Document Object Model (DOM) für XML untersucht. Sie haben gelernt, dass es Ihnen ein allgemeines API bereitstellt, das von einer Reihe von Script- und Applikations-Entwicklungssprachen verwendet werden kann. Sie haben gesehen, wie das DOM die Inhalte eines XML-Dokuments als hierarchische Struktur aufeinander bezogener Knoten exponiert. Schließlich haben Sie einige Scripts geschrieben, die verschiedene Eigenschaften und Methoden von Dokumentobjekten zur Lokalisierung der Knoten in einem XML-Dokument und zur Meldung von Parsing-Fehlern verwenden. Morgen werden Sie eine Alternative zum DOM kennen lernen, die sich Simple API for XML (SAX) nennt und ein eventgesteuertes Modell zur XML-Verarbeitung ist.
Frage:
Was ist ein Objektmodell?
Antwort:
In der Computerprogrammierung ist ein Objektmodell wie das DOM eine
Gruppe von aufeinander bezogenen Objekten, die zusammenarbeiten, um eine
Reihe verwandter Aufgaben zu erfüllen. Man kann Applikationsprogrammier-
Schnittstellen (API) genannte Schnittstellen entwickeln, wenn man den Objekten
bekannte Methoden, Eigenschaften und Events zuordnet. Das Document Object
Model (DOM) stellt ein API bereit, das unabhängig von Plattformen und den
Sprachen ist, mit denen es implementiert wird.
Frage:
Wie verwendet ein Programmierer das DOM?
Antwort:
Sie erzeugen eine Instanz eines XML-Parsers, wenn Sie das DOM-Objekt
instanzieren. Der Microsoft-Ansatz, der für die Übungen in diesem Kapitel
eingesetzt wurde, exponiert das XML-DOM mittels einer Reihe von Standard-
COM-Komponenten der MSXML-Parser-Programmfolge, die im Paket zum
Internet Explorer 5.0 oder höher enthalten sind.
Frage:
Wie entscheiden Sie, wann Sie clientseitiges und wann Sie serverseitiges Scripting beim
DOM verwenden?
Antwort:
Clientseitige DOM-Anwendungen sind vor allem nützlich für das Testen und
Validieren. Es gibt jedoch verschiedene Gelegenheiten für »upstream«-DOM-
Implementierungen. Serverseitiges DOM-Parsing ist besonders geeignet in Fällen,
in denen es zu unbeaufsichtigten Server-zu-Server-Ausführungen kommt.
Serverseitige DOM-Programme können auch unter der Steuerung eines Scripts
ausgeführt werden. Deshalb können Sie eine Website bauen, die die serverseitige
DOM-Programmierung verwendet, um XML-Dokument-Instanzen zu
manipulieren.
Schreiben Sie ein Script, das das DOM instanziert. Laden Sie Ihr Dokument cd.xml in das Objekt und schreiben Sie den Inhalt der titel- und kuenstler-Elemente für die erste CD in Ihrer Sammlung in das Browserfenster.
Verwenden Sie die Methode getElementsByTagName() und fügen Sie die passende item()- Methode und die text-Eigenschaft hinzu, damit die gewünschten Werte zurückgegeben werden.
Modifizieren Sie Ihren Code so, dass er den Inhalt der Elemente titel und künstler für die zweite CD in Ihrer Sammlung zurückgibt.
