




Die XML Pointer Language (XPointer) bietet Ihnen eine Methode, wie Sie Informationen in einem anderen XML-Dokument adressieren und lokalisieren können. XPointer verwendet die XML Path Language (XPath), die Sie am 9. Tag untersucht haben und erweitert sie. XPointer kombiniert Ausdrücke von XPath mit URIs. Sie haben beide Technologien bereits im Detail kennen gelernt, also werden wir uns heute darauf konzentrieren, wie die beiden in einen XPointer-Ausdruck eingebaut werden können. Sie lernen heute
Die Spezifikation zu XPointer, ein Arbeitsentwurf des W3C vom 9. Juli 1999, beschreibt stringbasierte Ausdrücke, die die direkte Adressierung interner Strukturen bei XML- Dokumenten unterstützen. XPointer-Strings bieten eine spezifische Referenz auf Elemente, Zeichenstrings und andere Teile von XML-Dokumenten, weil sie auf der ausdrucksstarken und auswählenden Sprache XPath beruhen. Das ist eines der Merkmale, die XPointer von einem Anker-Link-Lokator bei HTML unterscheiden.
![]()
Sie sollten die Unterlagen zu XPath (Tag 9) und XLink (Tag 10) noch einmal durchlesen, bevor Sie sich dem heutigen Unterrichtsstoff zuwenden. Der heutige Stoff bietet einen Rückblick und erweitert einige der Features dieser Technologien, aber er sollte im Zusammenhang mit diesen Kapiteln gelesen werden.
Als Ausgangspunkt wollen wir uns noch einmal ansehen, wie grundlegende Verweise bei HTML funktionieren. Um die Teilmenge einer HTML-Seite, etwa ein Fragment, lokalisieren zu können, muss ein name an einer bestimmten Stelle eingerichtet werden, bevor der Link abgefragt werden kann, und das aufrufende Dokument muss den benannten Link ausdrücklich ansprechen. Das funktioniert bei HTML, um benannte Fragmente im gleichen oder in einem anderen Dokument zu lokalisieren. Die Syntax für die benannte Zielkennzeichnung lautet:
<a name="target_name">Zieltext oder Objekt</a>
Das richtet einen Flag an der Stelle auf der HTML-Seite ein, wo der Anker abgelegt ist. Dieser Flag kann sich am Seitenanfang oder auch an einer beliebigen Stelle in der Seitenauszeichnung befinden. Der Wert des Attributs name wird dem Fragment mit diesem Flag auf der HTML-Seite zugeordnet und liefert seine Adresse. Ein anderes Anker-Tag, das sich ausdrücklich auf den benannten Wert des Attributs bezieht, kann die Adresse auflösen. Die Syntax für das aufrufende Anker-Tag lautet:
<a href="URI#target_name">Linktext oder Objekt</a>
Der Hypertext-Link, der mit diesem Anker-Tag erzeugt wird, zeigt auf das benannte Fragment auf der Seite, die die URI anzeigt. Wenn der Anwender den Link aktiviert, indem er mit der Maus auf den Linktext oder das Objekt klickt, die im Browserfenster angezeigt werden, lädt der Browser den Inhalt des Fragments am benannten Zielort herunter und zeigt ihn anstelle der aktuellen Seite an. Abbildung 11.1 zeigt diese HTML- Funktion.
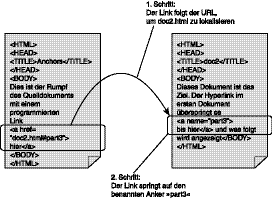
Abbildung 11.1: Ein HTML-Hypertext-Link aus einem Dokument auf ein benanntes Ziel in einem anderen Dokument
Es gibt einige Beschränkungen beim beschriebenen HTML-Ansatz. Erstens müssen Sie die Namen aller verfügbaren Ziele kennen. Wenn Sie die Seite selbst gestaltet haben, ist das relativ einfach. Wenn Sie aber auf eine externe Seite zugreifen, die Sie nicht erstellt haben, können die Zielnamen zu einem großen Problem werden. Zunächst einmal müssen die Ziele natürlich überhaupt existieren, damit dieser Ansatz funktionieren kann. Wenn es sie nicht gibt, können Sie auf keinen benannten Anker verweisen, um ein Seitenfragment zu lokalisieren. Das bedeutet, dass ein HTML-Programmierer von vorneherein darauf achten muss, nützliche benannte Anker auf die Seite zu setzen.
Ein weiteres Problem ist die Sicherheit. Angenommen, Sie wollen auf Fragmente einer HTML-Seite zugreifen, die noch nicht benannt sind. Wenn Sie die passenden benannten Anker selbst erstellen wollen, müssen Sie die vollen Zugriffsrechte auf diese Seite haben, damit Sie sie auf dem Server, der als Host fungiert, aufrufen und modifizieren können. Statische Webseiten sind schreibgeschützte Dokumente; ohne Zugriffsrechte auf den Host können Sie sie nicht verändern. Sie können die Quelle einer Webseite, für die Sie nur Lesezugriff haben, in der Regel anschauen und ermitteln, ob es bereits benannte Anker dort gibt, aber ohne die eigentlichen Zugriffsrechte können Sie eine schreibgeschützte HTML-Seite nicht modifizieren. XPointer bietet XML-Autoren eine Methode, wie man auf Fragmente in schreibgeschützten XML-Dokumenten zugreifen kann.
XPointer verwendet die gebräuchliche Sprache für Ausdrücke, die Sie am 9. Tag kennen gelernt haben, und erweitert sie beträchtlich: XPath. XPointer ist eigentlich die Kombination aus XPath-Ausdrücken und qualifizierten URIs, die Ihnen erlaubt:
Mit der umfangreichen Ausdruckssprache XPointer können Sie Informationen lokalisieren, indem Sie durch die Dokumentstruktur navigieren. Auf diese Weise können Sie Fragmente auf Grund ihrer Eigenschaften auswählen, also etwa des Elementtyps, der Attributswerte, des Zeichengehalts und der relativen Position und Anordnung. Das bietet eine sehr leistungsfähige Lokalisierungsmöglichkeit, deren Granularität1 weit über das hinausgeht, was mit XPath alleine möglich ist. XPath kann Knoten in einem Dokument lokalisieren, wogegen XPointer Knoten und Muster im Elementinhalt lokalisieren und sogar die Adresse eines einzelnen Zeichens im Dokument angeben kann.
XPointer verwendet ein erweitertes URI-Adressierschema, ähnlich dem von HTML-Anker- Tags genutzten. Die Syntax für einen XPointer-Ausdruck lautet:
URI#scheme(expression)
Wenn Sie XPointer erzeugen, lassen Sie der URI unmittelbar das Gitter- (#) oder Pfundzeichen und einen XPointer-Fragmentteil folgen, der aus einem scheme und einer expression besteht. Die URI in diesem String ist vom Fragmentteil (also dem Schema plus dem Ausdruck) durch das Gitterzeichen getrennt. Die URI ist für die Lokalisierung einer Ressource zuständig - üblicherweise ein Dokument - und der XPointer-Ausdruck stellt die Adresse auf ein spezifisches Fragment innerhalb des lokalisierten Dokuments bereit.
Sie können mehr als einen Fragmentteil in einen XPointer-Ausdruck einfügen, in diesem Fall lautet die Syntax dann:
URI#scheme(expression)scheme(expression)scheme(expression)...
Das einzige aktuell definierte Schema ist xpointer, das den Prozessor davon in Kenntnis setzt, dass die Sprache XPath als Ausdruckssprache für die Adressierung verwendet wird. Vielleicht wird es in Zukunft weitere Ausdruckssprachen geben und die Syntax über XPointer hinausgehen, dann kann das Schema vielleicht auf andere Weise programmiert werden.
Normalerweise fügen Sie nur dann mehrere Fragmentteile zusammen, wenn die Struktur, die Gültigkeit oder die Natur des Zieldokuments fraglich ist. Da bei XPointer der Ausdrucksstring bei der Auflösung von links nach rechts gelesen wird, hört ein Prozessor auf, weiterzulesen, sobald er einen Pfadausdruck für das Fragment erkennt. Das ist in XPath anders: dort wird auf jeden Fall der gesamte Ausdruck interpretiert. Verwendet man XPointer, kann man Fragmentteile ein- und einen alternativen Ausdruck angeben, für den Fall, dass der erste kein Ergebnis bringt.
XPointer ist gegenwärtig das einzige Schema, das in der Spezifikation beschrieben wird, daher ist eine Kurzform für die Syntax zulässig. Sie sieht so aus:
URI#expression
Eine Möglichkeit, XPointer zu verwenden, besteht darin, ein id-Attribut für das Element zu setzen, auf das Sie verweisen möchten. Das entspricht dem Ansatz mit dem benannten Anker bei HTML; Voraussetzung ist, dass Sie Ihre XPointer vorausplanen. Ein einfacher String nach dem Gitterzeichen, der nicht weiter qualifiziert wird, wird als Referenz auf ein Element mit dieser ID interpretiert. Nehmen wir zum Beispiel an, Sie wollen in dem Nachrichtenverarbeitungssystem, mit dem Sie an den vergangenen Tagen gearbeitet haben, eine Nachricht finden, die mit einer bestimmten ID-Nummer ausgezeichnet ist. Angenommen, im XML-Dokument befinden sich derzeit drei Nachrichten und Sie wollen die erste davon, die für das nachricht-Element ein ID-Attribut mit dem Wert m1 hat, mit einem XPointer-Ausdruck lokalisieren. Listing 11.1 ist dieses XML-Instanzdokument.
Listing 11.1: Eine XML-Instanz mit ID-Attributen für das Nachrichtelement - nachricht01_11.xml
1: <?xml version = "1.0"?>
2: <!-- listing 11.1 - nachricht01_11.xml -->
3:
4: <notiz>
5: <nachricht id="m1" from="Kathy Shepherd">
6: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
7: </nachricht>
8: <nachricht id="m2" von="Greg Shepherd">
9: Ich brauche ein wenig Hilfe bei den Hausaufgaben
10: </nachricht>
11: <nachricht id="m3" von="Kristen Shepherd">
12: Bitte spiele heute Abend Scribble mit mir
13: </nachricht>
14: </notiz>
In den Zeilen 5, 8 und 11 wurden den nachricht-Elementen id-Attribute hinzugefügt.
Um das nachricht-Element mit dem Attribut id="m1" zu lokalisieren, können Sie die Kurzform der XPointer-Ausdrücke verwenden:
nachricht01.xml#m1
Dieser Ausdruck lokalisiert das nachricht-Element in Zeile 5 von Listing 11.1. Die umfangreichere Variante für diesen Ausdruck lautet:
nachricht01.xml#ID(m1)
Beide Formen des XPointer-Ausdrucks haben die gleiche Auswirkung. Sie finden beide Formen und können beides eingeben. Die wortreichere Variante ähnelt der Syntax anderer XPointer-Ausdrücke mehr, bei denen normalerweise irgendein Schlüsselwort angegeben wird, dem in Klammern ein Wert oder Argument folgt.
Im vorangehenden Beispiel kann der Standort-Begriff id() ein bestimmtes Element ohne weitere Adressangaben lokalisieren. Das ist ein Beispiel für einen absoluten Standort- Begriff. Es gibt bei XPointer vier dieser speziellen Begriffe. Sie folgen auf das Gitterzeichen in einem Ausdrucksstring, können aber nicht kombiniert werden. Anders gesagt, es ist nur einer dieser speziellen Begriffe für jede Ausdrucksphrase zulässig. Tabelle 11.1 fasst diese Begriffe zusammen.
Tabelle 11.1: Absolute Standort-Begriffe bei XPointer
Beziehungs-Ausdrücke oder relative Standort-Begriffe adressieren den Standort eines Elements auf der Grundlage des Kontextknotens. Anders gesagt, der Ausdruck kann unterschiedliche Resultate erzielen, je nachdem, wo die Durchquerung anfängt. Sie haben die Beziehungen und XPath-Achsen am 9. Tag kennen gelernt. Wenn Sie sie in Kombination mit einer URI einsetzen, die durch das Gitterzeichen abgetrennt ist, haben Sie einen relativen XPointer-Ausdruck. Beziehungs-Ausdrücke funktionieren bei XPointer genauso wie bei XPath, aber sehen Sie sich diese Ausdrücke des 9. Tags zur Erinnerung am besten noch einmal an. Sie erinnern sich bestimmt, dass es eine Vielzahl von Beziehungsachsen gibt; aber nicht alle haben eine Bedeutung für XPointer. Die relevanten Beziehungen sind:
Sie fragen sich vielleicht, warum einige XPath-Achsen in der obigen Auflistung fehlen wie Stamm und Nachfahre-oder-Selbst. Das ist deshalb so, weil XPointer Ihnen erlaubt, an die relativen Standort-Begriffe in obiger Liste Argumente anzufügen, was ein effizientes Mittel ist, eine beliebige XPath-Standardachse auszuwählen. Wenn Sie zum Beispiel den ersten Vorfahren relativ zum Kontextpunkt auswählen, dann wählen Sie damit eigentlich den Stamm für diesen Kontext aus.
Jeder relative Standort-Begriff akzeptiert bis zu vier Argumente, die den Ausdruck näher definieren. Mit diesen Argumenten können Sie die Empfindlichkeit eines XPointer- Ausdrucks erhöhen. Das Gleiche bewirken Argumente für die Genauigkeit all dieser Beziehungen und sie werden durch ihre absolute Position zwischen den Klammern charakterisiert, die an den Beziehungs-Ausdruck angehängt werden. Im nächsten Abschnitt werden die Argumente kurz beschrieben. Es handelt sich dabei um XPath-Ausdrücke, deren Verwendung typisch für XPointer ist; deshalb sollten Ihnen einige der Ähnlichkeiten zwischen diesen Beispielen und den Ausdruckstypen, die Sie am 9. Tag erstellt haben, auffallen. Dennoch zeigen wir anders geartete Beispiele, um die gemeinsame Logik bei XPath und XPointer zu unterstreichen und Ihnen die Gelegenheit zu geben, mehr Erfahrung beim Lesen und Nachdenken über Ausdrücke zu bekommen.
Das erste Argument gibt die Zahl der gewünschten Auswahl aus einem Satz potenziell zu wählender Beziehungen an. Das Argument kann ein positiver oder negativer Integer oder das Wort all sein. Das all-Argument wählt alle qualifizierten Elemente aus einem Beziehungssatz aus. Mit einer Zahl wird das angegebene Element ausgewählt. Dabei wird in Richtung der Dokumentanordnung gezählt, wenn es sich um einen positiven Integer handelt, und in umgekehrter Richtung, wenn eine negative Zahl angezeigt wird. Angenommen, Sie befinden sich gegenwärtig im Kontext des notiz-Elements und wollen alle nachricht-Elemente aus Listing 11.1 auswählen. In Beziehungsbegriffen ausgedrückt heißt das, Sie wollen alle abgeleiteten Elemente relativ zum Kontextknoten auswählen. Sie können das mit folgendem Ausdruck erreichen:
child(all,nachricht)
Dieser Ausdruck wählt alle abgeleiteten nachricht-Elementknoten aus, die das aktuelle Element enthält. In Listing 11.1 würde dies in der Auswahl aller nachricht-Elemente resultieren, vorausgesetzt, der Ausdruck wird relativ zum notiz-Element aufgelöst. Wenn der Kontext im Dokument ein anderer ist, gibt dieser Ausdruck nicht das gewünschte Resultat zurück. Im Fall von nachricht01_11.xml (Listing 11.1) würde dieser Ausdruck für jeden anderen Kontext als das notiz-Element fehlschlagen.
Vorausgesetzt, der Kontext ist tatsächlich das notiz-Element, wie kann man dann mit einem XPointer-Ausdruck das dritte abgeleitete nachricht-Element auswählen? Der korrekte Ausdruck lautet:
child(3,nachricht)
Der numerische Wert (3) wählt ein bestimmtes Element aus, wenn dieser Ausdruck aufgelöst wird. In diesem Fall wird das Stammelement ausgewählt, also das dritte abgeleitete nachricht-Element im notiz-Kontext.
Das zweite Argument gibt den Knotentyp an, der von XPointer durchquert wird. Meistens handelt es sich dabei um den Namen eines Elementtyps. Sie haben im letzten Abschnitt Beispiele für dieses zweite Argument sehen können. Hier kommen sie noch einmal:
child(all,nachricht)
child(3,nachricht)
In beiden beispielhaften XPointer-Ausdrücken wird als Knotentyp der Elementtyp nachricht angezeigt. Das erste Beispiel wählt alle abgeleiteten nachricht-Elemente aus, das zweite wählt nur die dritte Ableitung im potenziellen Auswahlset aus.
Das Knotentyp-Argument stellt auch eine Wildcard-Option zur Verfügung, die die Auswahl über einen spezifizierten Typ hinaus erweitert. Es handelt sich dabei um den Argumentwert #element. Wenn Sie alle abgeleiteten Elemente relativ zum Kontextelement unabhängig vom jeweiligen Elementtyp auswählen wollen, können Sie folgenden XPointer eingeben:
child(all,#element)
Dieser Ausdruck wählt alle abgeleiteten Elemente unabhängig von ihren Namen aus.
Die Argumente drei und vier sind Paare von Attributswerten, die man verwenden kann, um die Auswahl der Elemente auf der Grundlage der für sie spezifizierten Attribute zu filtern. Angenommen, Sie wollen das Dokument nachricht01_11.xml (Listing 11.1) nach dem Standort des nachricht-Elements mit dem Wert Kathy Shepherd für das from-Attribut befragen. Sie können diesen Ausdruck unterschiedlich gestalten, aber ein einfacher Ansatz ist der folgende:
child(all,#element,from,"Kathy Shepherd")
Dieser Ausdruck wählt alle Elemente aus, unabhängig vom Namen des Elementtyps, vorausgesetzt sie haben ein from-Attribut mit dem Wert "Kathy Shepherd".
Anstelle des Attributsnamens an der dritten Position im Argumentstring können Sie ein Sternchen einsetzen (*). Das bedeutet, dass alle Attribute mit dem angegebenen Wert die Auswahlkriterien erfüllen.
Bei der vierten Position im Argumentstring können Sie entweder ein Sternchen (*) als Wildcard für alle Werte eingeben oder #IMPLIED. #IMPLIED stammt aus der DTD-Logik und zeigt an, dass kein Wert für das Attribut angegeben wurde. Wenn für das Attribut ein Wert angegeben wird, dann kann diese Instanz nicht durch ein #IMPLIED-Argument ausgewählt werden.
XPointer ist eine Technologie, die URIs mit XPath-Ausdrücken kombiniert, um die Auswahl von Knoten oder Verweisen auf ein Zieldokument fein einzustellen. XPointer erweitert XPath durch das Bereitstellen einiger Features, die dort nicht vorkommen. Das hat zur Folge, dass XPointer eine höhere Granularität bietet, wenn es darauf ankommt. Das Resultat ist eine Technologie, die reich an Features ist, die nicht nur leistungsstark, sondern auch hoch selektiv sind.
Frage:
Warum kann man keine HTML-Anker-Tags verwenden, um auf Fragmente in einer
schreibgeschützten Dokumentstruktur zuzugreifen?
Antwort:
In einigen Fällen ist das möglich; man muss aber die Ankernamen kennen, die im
HTML-Dokument am Anfang vorher bestimmter Fragmente stehen. Wenn man
auf Fragmente zugreifen will, denen keine Anker-Tags zugeordnet sind oder wenn
man die Namen dieser Anker-Tags nicht kennt, dann ist der HTML-Ansatz nicht
hilfreich. Mit XPointer kann man eine Auswahl auf der Grundlage von Kriterien
treffen, die nicht durch Namen beschränkt wird, die man kennen muss. Diese
Kriterien sind Muster-, Element- und Attributsanordnungen und andere Produkte
von XPath-Ausdrücken.
Frage:
Welche Beziehung besteht zwischen XPointer und XPath?
Antwort:
XPointer ist ein Produkt von XPath, das mit URIs kombiniert wird. Mit XPath
werden die Dokumentfragmente ausgewählt, nachdem das Dokument auf Grund
der aufgelösten URI lokalisiert wurde.
Frage:
Warum stellt die XPointer-Syntax mehrere Fragmentteile zur Verfügung?
Antwort:
Ein Fragmentteil besteht aus einem Schema und einem Ausdruck. Gegenwärtig
ist XPointer das einzige Schema. Man kann mehrere Fragmentteile
zusammenfügen, sodass für die XML-Dokument-Instanz Auswahltests stattfinden
können. Wird ein XPointer-Ausdruck durchquert, dann wird der erste
Fragmentteil ausgetestet. Wenn dieser Fragmentteil aufgelöst wird, endet der
Prozess. Wird er nicht aufgelöst, geht der Prozess weiter zum nächsten
Fragmentteil, wenn ein solcher vorhanden ist. Auf diese Weise können
Programmierer alternative Muster angeben.

Die Beschreibung der Aktivität bzw. einer Funktion (z.B. Suchen und Sortieren, Bildschirmauflösung oder Zuordnung von Zeitscheiben) in Bezug auf die entsprechenden Einheiten (Zeitscheiben, Pixel oder Datensätze) eines Computers. Aus: Winkler, P.: M+T Computerlexikon, Markt+Technik Verlag