




Das Simple (einfache) API für XML (SAX) ist ein öffentlich entwickelter Standard für Event-basiertes Parsing von XML-Dokumenten. Anders als der Ansatz mit dem Document Object Model (DOM), den Sie am 12. Tag untersucht haben und der eine Darstellung für die Informationen in Ihrem XML-Dokument auf Grundlage eines Baums erstellt, gibt es bei SAX kein standardmäßiges Objektmodell. SAX definiert eine abstrakte programmatische Schnittstelle, die die XML-Dokument-Instanz durch eine lineare Sequenz methodischer Aufrufe modelliert. Sie werden heute lernen:
SAX 1.0 (das einfache API für XML) wurde am 11. Mai 1998 veröffentlicht. SAX ist ein allgemeines, Event-basiertes API zum Parsen von XML-Dokumenten. Es wurde in Zusammenarbeit der Mitglieder der Internet-Diskussionsgruppe XML-DEV entwickelt. SAX 2.0 ist eine neuere Version, die eine Unterstützung für Namensräume und komplexere Abfrage-Strings aufgenommen hat. Heute werden Sie mit SAX 1.0 arbeiten und es verwenden, um XML-Dokumente zu parsen. Weitere Details zur Geschichte dieses Projekts finden Sie unter http://www.megginson.com/SAX/.
Wie das DOM stellt SAX einen Standardsatz von Methoden bereit, die implementiert werden können, um die Daten und den strukturellen Inhalt bei XML-Dokument- Instanzen programmatisch zu manipulieren. SAX ist eine weitere Methode zum Parsen und für den Zugriff auf Teile von XML-Dokumenten. Während der Dokumentverarbeitung wird jeder Teil identifiziert und ein entsprechender Event gestartet. Das unterscheidet SAX vom DOM-API. Sie haben gestern gelernt, dass das DOM eine komplette Dokument-Instanz auf einmal in den Speicher einliest. SAX bearbeitet jede Auszeichnungskomponente, auf die es trifft, als eigenen Event, ohne dass die ganze Dokument-Instanz sofort in den Speicher eingelesen werden muss. Das ist nicht der einzige Unterschied zwischen SAX und dem DOM-API. Das DOM hat zum Beispiel die Fähigkeit, Knoten hinzuzufügen und zu löschen. Mit dem DOM kann man eine ganze XML-Instanz von Grund auf neu erzeugen. Das geht mit SAX nicht. Sie werden heute noch weitere Unterschiede kennen lernen.
SAX-Parser gibt es für eine Reihe verschiedener Programmiersprachen wie Java, Python, PERL und Visual Basic, von denen jede eine Möglichkeit bietet, die allgemeinen Methoden zu implementieren, die das API charakterisieren. Mehr zu diesen Methoden erfahren Sie in Kürze. Die ursprüngliche Arbeit an SAX erfolgte voll und ganz in Java und die Mehrheit der Lösungen sind als Java-API-Verteilungen implementiert. Einige beliebte Parser für SAX sind in Tabelle 13.1 aufgelistet.
Tabelle 13.1: Populäre SAX-Parser
Sie werden sich erinnern, dass der DOM-API-Ansatz ein Modell auf der Grundlage eines Baums erstellt, das alle Daten eines XML-Dokuments in einer Knotenhierarchie speichert. Die gesamte Dokument-Instanz wird auf einmal in den Speicher geladen, was Ihnen eine effiziente Methode bietet, beliebige Zugriffsmöglichkeiten zu erhalten und jeden Knoten im Dokumentbaum exponieren zu können. Das DOM verfügt über die Fähigkeit, Knoten hinzuzufügen oder zu entfernen, sodass Sie das Dokument mittels der Steuerung durch ein Programm modifizieren können.
Normalerweise bauen Sie Funktionen ein, die durch vom Anwender generierte Events oder -Transaktionen ausgelöst werden, wenn Sie eine Event-basierte Anwendung erzeugen. Ein Script kann zum Beispiel auf den OnClick-Event warten, um eine bestimmte Sub-Routine auszuführen. Wenn Sie eine Anwendung zur Instanzierung eines Event-basierten SAX- Parsers schreiben, enthält diese einen ähnlichen Ansatz; es ist jedoch der Parser, nicht der Anwender, der die Events erzeugt. SAX-Parser rufen Methoden auf, wenn sie beim Parsen eines Dokuments Markup-Events antreffen. Teile Ihres XML-Dokuments wie der Anfang oder das Ende der Dokument-Instanz, Start- und Schluss-Tags, Attribute und Zeichendaten lösen Events aus, die ein SAX-Parser während der Verarbeitung des Dokuments erkennt.
Der Parser soll eindeutige Markup-Zeichen lesen und erkennen, wenn er sie im Datenstrom antrifft, der ein XML-Dokument ausmacht. Betrachten Sie das einfache XML- Dokument, das in Listing 13.1 gezeigt wird, als Quelle, die einem SAX-Parser präsentiert wird.
Listing 13.1: Ein einfaches XML-Dokument - nachricht01_13.xml
1: <?xml version = "1.0"?>
2: <!-- listing 13.1 - nachricht01_13.xml -->
3: <notiz>
4: <nachricht von="Kathy Shepherd">
5: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
6: </nachricht>
7: </notiz>
Einige der Events, die SAX in Objekte verwandeln kann, sind:
1: Dokumentanfang
2: Elementanfang ( notiz )
3: Elementanfang ( nachricht )
4: Attributsnamen-Wertepaar ( von="Kathy Shepherd" )
5: Zeichendaten (Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen )
6: Elementende ( nachricht )
7: Elementende ( notiz )
8: Dokumentende
![]()
Zeile 1 ist ein Event, der dem Anfang der Dokument-Instanz entspricht, die während der Verarbeitung dieses Dokuments durch den SAX-Parser generiert wird. Zeile 2 repräsentiert den Event, der den Beginn des notiz-Elements markiert. Das Schluss-Tag des notiz-Elements generiert den Element beendenden Event, der in Zeile 7 angegeben wird. Die Zeilen 3-6 entsprechen dem Anfang und dem Ende des nachricht-Elements. Zeile 4 zeigt den Event, der dem von-Event im nachricht-Element entspricht. Das Event, der den geparsten Zeichendaten des nachricht-Elements zugeordnet wird, steht in Zeile 5.
In Wirklichkeit werden der Beispiel-Instanz aus Listing 13.1 noch weitere potenzielle Events zugeordnet, die nicht identifiziert wurden. Zum einen behandelt SAX die Leerzeichen in einem XML-Dokument anders als das DOM. Mehr dazu erfahren Sie später.
Die SAX- und DOM-Ansätze unterscheiden sich offensichtlich darin, wie sie das XML- Instanzdokument in programmatischen Typen wiedergeben. Bei dem Event-basierten Modell, das SAX abbildet, wird für die XML-Instanz im Speicher keine Baumstruktur erzeugt. Statt dessen werden die Daten Zeichen für Zeichen in Richtung der Dokumentanordnung an eine Anwendung weitergegeben. Da SAX keine Ressourcen für eine Repräsentation des Dokuments im Speicher erfordert, ist es unter bestimmten Umständen eine gute Alternative zum DOM. Mit SAX können Sie zum Beispiel große Dokument-Instanzen systematisch durchsuchen, um kleine Informationsteile zu extrahieren. Zusätzlich können Sie mit SAX die Verarbeitung nach der Darlegung der gewünschten Informationen anhalten und es ist nicht erforderlich, das gesamte Dokument für die Dokumentverarbeitung in den Speicher zu laden. Man kann mit SAX DOM- Bäume konstruieren. Zum Teil sind viele DOM-Parser auf interner Ebene so konstruiert. Umgekehrt können Sie DOM-Bäume durchqueren und SAX-Ströme ausgeben; diese komplexen Operationen sprengen aber den Rahmen der heutigen Lektion.
Da die Daten aus der XML-Dokument-Instanz an die SAX-Anwendung so weitergegeben werden, wie sie aufgefunden werden, kann man konsequenterweise eine höhere Leistung und einen geringeren Speicherbedarf oder Aufwand erwarten. Die Vorteile dieses Ansatzes hinsichtlich der Leistungsfähigkeit werden jedoch durch komplexere Verarbeitungsstrukturen wieder zunichte gemacht. Das fortgeschrittene Abfragen eines Dokuments mit vielen Ebenen eingebetteter abgeleiteter Elementen und mit komplexen Beziehungen der Elemente untereinander kann wegen der Komplexität, die dem Verwalten des Event-Kontextes während der Verarbeitung inhärent ist, sehr mühsam werden. Die Folge ist, dass viele Programmierer den DOM-Ansatz bei Dokumenten bevorzugen, die modifiziert oder manipuliert werden müssen und einen SAX-Parser wählen, um übermäßig umfangreiche XML-Dokumente auszulesen, die nicht verändert werden müssen. Ein wachsender Trend bei der XML-Programmiergemeinde geht in Richtung einer Kombination der DOM- mit den SAX-Lösungen, um besondere Bedürfnisse zu befriedigen.
Da Event-basierte Parser Dokumente auf eine serielle Weise verarbeiten, ist das Simple API für XML (SAX) häufig eine exzellente Alternative zum Document Object Model (DOM).
Einer der bedeutendsten Vorteile des SAX-Ansatzes ist, dass er deutlich weniger Speicherplatz für die Verarbeitung eines XML-Dokuments erfordert als ein DOM-Parser. Bei SAX wächst der Speicherbedarf nicht mit der Größe der Datei. Ein Dokument von 100 KB kann bei Verwendung eines DOM-Prozessors bis zu 1 MB Speicherplatz belegen. Wenn es von einem Event-getriebenen SAX-Prozessor geparst wird, braucht das gleiche Dokument deutlich weniger Speicherplatz. Wenn Sie umfangreiche Dokumente verarbeiten müssen, ist SAX vielleicht die bessere Alternative, vor allem, wenn Sie den Inhalt des Dokuments nicht verändern müssen.
Mit SAX können Sie die Verarbeitung jederzeit anhalten, deshalb können Sie es verwenden, um Anwendungen zu erzeugen, die bestimmte Daten lokalisieren und ermitteln. Sie können zum Beispiel eine Anwendung erzeugen, die nach einem Punkt in einem Katalog oder Bestandssystem sucht. Wenn die Anwendung den gewünschten Punkt findet, kann sie die Daten, die sich auf ihn beziehen, zurückgeben, etwa die Bestandsnummer und die Verfügbarkeit, und anschließend die Verarbeitung beenden, ohne das restliche Dokument abzufragen.
Viele Lösungen, die auf XML gründen, müssen nicht das gesamte Dokument lesen, um die gewünschten Resultate zu erzielen. Man kann sich zum Beispiel eine Anwendung für Online-Nachrichten vorstellen, die die Daten eines Nachrichtenkanals nach relevanten Meldungen zu einem bestimmten Thema absucht; es ist wenig effizient, alle unnötigen Daten in den Speicher einzulesen. Mit SAX kann Ihre Anwendung die Daten nach Nachrichtenartikeln absuchen, die sich ausschließlich auf das Thema beziehen, das Sie angeben, und dann eine Untermenge zur Dokumentstruktur erzeugen, die an Ihre Anwendung zum Auslesen von Nachrichten, Ihren Browser oder vielleicht an ein drahtloses Gerät weitergegeben wird. Es spart bedeutende Systemressourcen, wenn nur ein kleiner Prozentsatz eines Dokuments untersucht wird.
Manchmal wird der DOM-Ansatz für Ihre Bedürfnisse die bessere Lösung bieten.
SAX bietet keine Methode, das gesamte Dokument auf einmal in den Speicher zu laden. Sie müssen die Daten in der Reihenfolge handhaben, in der sie verarbeitet werden. Wenn Sie beliebigen Zugriff auf Knoten benötigen, die komplexe Beziehungen zueinander haben, ist das DOM die bessere Wahl. SAX kann schwierig anzuwenden sein, wenn ein Dokument viele interne Querverweise wie ID- und IDREF-Attribute enthält.
Verwenden Sie DOM, wenn Sie komplexe Filterfunktionen mit XML Path Language (XPath) durchführen und komplexe Datenstrukturen festhalten wollen, die Informationen zum Kontext enthalten. Die Baumstruktur des DOM hält Kontextinformationen automatisch fest. Mit SAX müssen Sie die Kontextinformationen selbst speichern.
Wie bereits erwähnt, hat SAX keine Möglichkeit, eine neue XML-Dokument-Instanz zu erzeugen, wie dies das DOM-API kann. Das DOM ist in der Lage, XML-Dokumente zu erzeugen. SAX kann Events abfragen und eine Meldung dazu machen, aber es kann nicht dafür verwendet werden, eine XML-Dokument-Instanz zur weiteren Verarbeitung, Speicherung oder Übermittlung aufzubauen. Mit dem DOM können Sie auch ein gespeichertes Dokument modifizieren und ein Dokument aus einer XML-Quelldatei lesen. SAX ist dazu gedacht, XML-Dokumente zu lesen, nicht sie zu schreiben. Das DOM ist die bessere Wahl, wenn Sie ein XML-Dokument modifizieren und das geänderte Dokument im Speicher ablegen wollen.
Auch wenn es bestimmte allgemeine Methoden gibt, die zum Ansatz der SAX- Verarbeitung gehören, können verschiedene Implementierungen zusätzliche Methoden und Events aufrufen. Eine Zusammenfassung des beliebten Minimalsets von Methoden finden Sie in Tabelle 13.2. Diese Methoden werden als Teil der DocumentHandler- Schnittstelle implementiert, die das API charakterisiert.
Tabelle 13.2: Ausgewählte Methoden für den SAX-Parser
Im Dezember 1997 hat Peter Murray-Rust erstmals in Java die erste Version dessen implementiert, woraus sich später SAX entwickeln sollte. Murray-Rust ist der Autor des kostenlosen, Java-basierten XML-Browsers JUMBO. Murray-Rust begann mit dem Versuch, drei verschiedene XML-Parser mit ihren jeweils proprietären APIs mit dem JUMBO-Browser zu unterstützen. Nachdem er erkannt hatte, dass dies eine unnötige Komplikation darstellte, bestand er darauf, dass die ursprünglich implementierten Parser ein gemeinsames Event-basiertes API in Java unterstützen sollten, das er YAXPAPI (für Yet Another XML Parser API = Noch ein anderes XML-Parser-API) nannte. Die Mitglieder der XML-DEV-Mailing-List waren u.a. Tim Bray, Autor des XML-Parsers Lark und einer der Herausgeber der XML-Spezifikation, David Megginson, Autor von Microstars XML-Parser Ælfred, Jon Bosak, den Erfinder von XML und viele andere, die an der Entwicklung des Einfachen API für XML teilhatten.
Ein großer Teil der Design-Gemeinde für SAX bestand aus erfahrenen Java- Programmierern, sodass es ganz natürlich war, dass Java verwendet wurde, um die vorgeschlagenen Event-basierten Methoden zu implementieren. In jüngerer Zeit wurde SAX auch in Perl, Python, Visual Basic und andere Sprachen implementiert. Im nächsten Abschnitt werden Sie sehen, wie man einen SAX-Parser instanziert und mit Java Methoden für die XML-Event-Verarbeitung aufruft. Sie werden eine einfache Java-Anwendung erzeugen und kompilieren, die einige der Events identifiziert, die beim Parsen des XML- Dokuments angetroffen werden. Beachten Sie bitte, dass dieses Buch Ihnen weder die Programmiersprache Java noch die grundlegenden objektorientierten Programmiertechniken beibringen soll. Wenn Sie Ihr Java auffrischen wollen, können Sie das z.B. mit Jetzt lerne ich Java (ISBN-Nr.: 3-8272-5688-7) oder mit Java2 in 21 Tagen, beides beim Markt+Technik Verlag erschienen, tun. Sie können auch die kostenlose Java- Dokumentation von der Sun Microsystems-Website unter http://java.sun.com/j2se/1.3 herunterladen.
Java bietet prozedurale, objektbasierte (durch Klassen, Kapselung und Objekte gekennzeichnete) und objektorientierte (unterstützt mit Vererbung und Polymorphismus) Paradigmen. In diesem Abschnitt erhalten Sie Gelegenheit, ein Java-Programm zu schreiben, das SAX-Events als Objekte handhabt und die wiederverwendbaren Software- Komponenten der Standard-Klassenbibliotheken von SAX einschließt, die Sie in Ihr Programm importieren können.
Sie müssen mehrere Softwarepakete herunterladen und installieren, wenn Sie die heutigen Übungen mitmachen wollen. Wenn die Standardausgabe Java 2 nicht schon auf Ihrem Computer installiert ist, können Sie bei Sun Microsystems unter http://java.sun.com/ j2se eine kostenlose Ausgabe erhalten. Installieren Sie die Software nach den Anweisungen auf der Website.
Sie müssen auch Dateien aus dem Archiv für Ihr SAX-API herunterladen und extrahieren. Es gibt viele gute Optionen, aber in den heutigen Beispielen wird der JAXP-Parser von Sun Microsystems verwendet. Eine kostenlose Ausgabe finden Sie unter http://java.sun.com/ xml/download.html. Entpacken oder extrahieren Sie die Software auf Ihrer Festplatte und merken Sie sich das Unterverzeichnis, in dem sie abgelegt wird. Sie müssen die Umgebungsvariable classpath setzen oder die Compiler-Option classpath verwenden, um auf dieses Unterverzeichnis zu verweisen, wenn Sie Ihr Java-Programm kompilieren. Die Dokumentation zur JAXP-Software und ihrem Setup, die bei sun.com veröffentlicht ist, ist äußerst umfangreich.
Java-Anwendungen zu schreiben ist so ähnlich wie Strukturen aus Holzblöcken zu erzeugen. Die Blöcke haben vielleicht unterschiedliche Formen und Farben, die in das Gesamtbild der Struktur eingehen. Sie können gewollte und vorhersehbare Resultate erzielen, wenn Sie die Qualität der individuellen Komponenten miteinander kombinieren. Java funktioniert so ähnlich, weil Sie die Methoden und Schnittstellen jeder Klasse, die Sie importiert oder eingeschlossen haben, verwenden können, um eine Struktur von Objekten zu erzeugen, die sich auf vorhersagbare Weise verhalten. Sie werden für die Anwendung, die Sie in dieser Übung schreiben, Klassen und Schnittstellen aus verschiedenen Paketen, die mit der vorher genannten Software verteilt werden, importieren. Sie werden außerdem Methodenaufrufe für SAX-Parser-Methoden wie den in Tabelle 13.2 aufgeführten erzeugen. Abbildung 13.1 zeigt die Methoden, die die Anwendung charakterisieren, die Sie schreiben werden.
Sie können einen Texteditor verwenden und dieses Programm aufbauen, während Sie den Rest dieses Abschnitts lesen und alle Teile der Anwendung kennen lernen. Am Ende dieses Abschnitts wird eine vollständige Liste der EList-Klasse aufgezeigt, zusammen mit Kommentaren, die Ihnen dabei helfen, die jeweils aufgerufene Methode zu identifizieren.
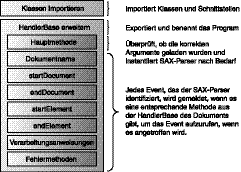
Abbildung 13.1: Die Struktur der Java-EList-Anwendung
Sie müssen das Java-Eingabe/Ausgabe (I/O)-Paket importieren, um Ihr Programm für die Verwaltung von Daten über Ein- und Ausgabeströme zu aktivieren. Das erreichen Sie, indem Sie das java.io-Paket der Standardausgabe Java-2 von Sun Microsystems importieren. Die Klassen in diesem Paket können Sie bei der Dateiverarbeitung und beim Networking verwenden, und um einen Standardsatz von Schnittstellen für andere I/O- Typen bereitzustellen. Die Syntax für das Schlüsselwort zum Importieren lautet:
import [Paket];
Wie alle reservierten Schlüsselwörter in Java muss import kleingeschrieben werden. Zusätzlich zum java.io-Paket brauchen Sie das Paket, das die Klassen und programmatischen Schnittstellen für SAX-Parser enthält, org.xml.sax. Dort ist die HandlerBase-Klasse enthalten, die Sie erweitern, wenn Sie Ihre Anwendung erzeugen.
Um alle Klassen für einen SAX-Parser zu instanzieren, müssen Sie auch das JAXP-Paket javax.xml.parsers importieren. Dieses Paket enthält eigentlich sowohl die Klassen für SAX- als auch für DOM-Parser, die nach Bedarf für Ihre Anwendung instanziert werden können.
Außerdem brauchen Sie javax.xml.parsers.SAXParserFactory für die Instanzierung eines SAX-basierten Parsers, der fähig ist, eine Instanz mit einer DTD zu validieren; des Weiteren javax.xml.parsers.ParserConfigurationException um einen Fehler für den Fall aufzuwerfen, dass ein Parser nicht korrekt instanziert werden kann; und schließlich javax.xml.parsers.SAXParser für die Instanzierung eines SAX-Parser-Objekts. Der vollständige Importblock in Ihrer Anwendung sieht so aus:
import java.io.*;
import org.xml.sax.*;
import javax.xml.parsers.SAXParserFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
Das Java-Programm, das Sie schreiben, wird die HandlerBase-Klasse aus dem Paket org.xml.sax der SAX-1-Implementierung erweitern. In der SAX-2-Implementierung wird diese Klasse HandlerBase durch DefaultHandler ersetzt. Der Zugriff auf DefaultHandler setzt den Import von org.xml.sax.helpers.DefaultHandler voraus; ansonsten sind beide Implementierungen identisch. Für die Zwecke dieser Übung importieren wir die Klassen und erweitern die ursprüngliche HandlerBase-Klasse. In dieser Übung kompilieren Sie eine Klasse und nennen sie EList (Event-Liste), um eine Auflistung von SAX-Events für den Ausgangsstrom hervorzubringen. Wie Sie Ihre eigene Klasse nennen, spielt keine Rolle, aber Sie müssen das ganze Java-Programm hindurch konsequent sein und sicherstellen, dass Sie den Code mit dem Klassennamen abspeichern, gefolgt von der Erweiterung .java, um sicherzugehen, dass die Kompilierung erfolgreich verläuft. Per Konvention beginnen alle Klassennamen - also die Bezeichner für Java-Klassen - mit einem großgeschriebenen alphabetischen Zeichen und haben am Anfang eines jeden einzelnen Worts im Klassennamen einen Großbuchstaben (zum Beispiel MeinEigenerPersoenlicherKlassenName). Die anwenderdefinierte primäre Anweisung zur Klassenerweiterung sieht folgendermaßen aus:
public class EList extends HandlerBase
{
[... die Methoden der definierten Klasse]
}
Alle Methoden der anwenderdefinierten Klasse werden in geschweifte Klammern eingeschlossen ({...}) und folgen auf die Deklaration der EList-Klasse. Die HandlerBase- Klasse implementiert vier Schnittstellen aus dem org.xml.sax-Paket. Wenn Sie den in SAX2 implementierten DefaultHandler verwenden, werden mehrere verschiedene Schnittstellen importiert. Tabelle 13.3 fasst diese Schnittstellen zusammen.
Tabelle 13.3: Einige Schnittstellen, die in der HandlerBase-Klasse des org.xml.sax-Pakets implementiert sind
Die erste Methode, die in einer Java-Anwendung ausgeführt wird, ist die main-Methode, eine in Java obligatorische Methode. Die main-Methode Ihrer Anwendung führt mehrere obligatorische Funktionen aus. Zunächst legt sie die Anforderung fest, dass der Anwender einen Dateinamen für die XML-Dokument-Instanz angibt; sie hält die Anwendung an und gibt eine Fehlermeldung auf dem Bildschirm des Anwenders aus, wenn kein Name angegeben wird. Als Nächstes erzeugen Sie eine Methode, die ein Argument in Form eines Strings erfordert, das in der Befehlszeile bereitgestellt werden muss, wenn das Programm aufgerufen wird. Der Code für diesen Teil der main-Methode sieht so aus:
1: public static void main( String fname[] )
2: {
3: if ( fname.length != 1 ) {
4: System.err.println( "Erwartete Syntax: java EList [filename]\ n" );
5: System.exit( 1 );
6: }
![]()
Zeile 1 deklariert die main-Methode, die ein String-Argument namens fname erfordert. Das Schlüsselwort static deklariert, dass es sich bei der main-Methode um eine Klassenmethode handelt. Das Schlüsselwort void zeigt an, dass diese Methode Aufgaben erfüllt, aber keine Informationen an die Klasse zurückgibt, wenn die Aufgabe erledigt ist. Alle Anforderungen der main-Methode folgen der Java-Syntax. Die Zeilen 3-4 stellen mit einem Test sicher, dass genau ein Argument in die Befehlszeile eingefügt wird, wenn die EList-Klasse aufgerufen wird. Wird diese Syntax nicht befolgt, schreibt das Programm eine Meldung auf den Bildschirm (zum Beispiel "Erwartete Syntax: java EList[filename]\n"), hält dann die Verarbeitung an und beendet Java.
Um mit dem Parsen eines XML-Instanzdokuments zu beginnen, müssen Sie zunächst das SAXParseFactory-Objekt aus dem Paket javax.xml.parsers instanzieren, um einen SAX- basierten Parser zu erhalten. Sie geben dann die XML-Dokument-Instanz, die unter der URL zu erhalten ist, die der Anwender beim Aufruf angibt, zusammen mit Ihrer EList- Klasse an das SAX-Parser-Objekt weiter, indem Sie die Methode newSAXParser aufrufen. Der Parser wiederum liest das XML-Dokument Zeichen für Zeichen und ruft die SAX- Methode auf, die Sie in Ihrer EList-Klasse programmiert haben. Sie werden gleich sehen, wie man die einzelnen Parser-Methoden eingibt. Alle Fehler oder Ausnahmen, die der Parser aufwirft, müssen von Ihrer Anwendung aufgefangen und dem Anwender gemeldet werden. Ein Fehler in Ihrer EList-Klasse sorgt dafür, dass der Prozessor anhält und dem Anwender über den Bildschirm-Ausgabestrom sofort eine Meldung macht.
Der Code, der die main-Methode vervollständigt, sieht wie der hier gezeigte Ausschnitt aus:
1: SAXParserFactory saxFactory = SAXParserFactory.newInstance();
2:
3: saxFactory.setValidating( false );
4:
5: try {
6: SAXParser saxParser = saxFactory.newSAXParser();
7: saxParser.parse( new File( fname[ 0 ] ), new EList() );
8: }
9: catch ( SAXParseException spe ) {
10: System.err.println( "Parse-Fehler:" + spe.getMessage() );
11: }
12: catch ( SAXException se ) {
13: se.printStackTrace();
14: }
15: catch ( ParserConfigurationException pce ) {
16: pce.printStackTrace();
17: }
18: catch ( IOException ioe ) {
19: ioe.printStackTrace();
20: }
21:
22: System.exit( 0 );
23: }
![]()
Die Zeile 1 instanziert das SAXParserFactory-Objekt aus dem zuvor importierten Paket javax.xml.parsers. Dort wird ein Programm mit einem SAX-Parser für die Event-basierte Verarbeitung bereitgestellt. Zeile 3 ist eine besondere Anweisung, die das SAXParserFactory-Objekt als nicht validierenden Parser konfiguriert. Sie können den Wert auf true abändern, wenn Sie wollen, dass der SAX-Parser Ihre XML-Dokument-Instanz mit einer korrekt zugeordneten Document Type Definition (DTD) validiert. Die Zeilen 6 und 7 instanzieren das SAX-Parser-Objekt, indem sie die newSAXParser-Methode aufrufen und das vom Anwender benannte Dokument dann zusammen mit einer Instanz der EList-Klasse an den Parser weitergeben. Die Zeilen 9-19 fangen alle Ausnahmefehler beim Parsen auf (wie zum Beispiel schwerwiegende XML-Syntaxfehler), ebenso die SAX-Ausnahmefehler (wie zum Beispiel eine Unterklasse von Ausnahmen, die aufgeworfen wird, wenn Parsing-Fehler auftreten), Fehler bei der Parser-Konfiguration (wie zum Beispiel Fehler, die vom Fehlschlagen der Instanzierung des Parser-Objekts verursacht werden) oder I/O-Ausnahmefehler (wie zum Beispiel Probleme, die auftreten, wenn eine XML-Dokument-Instanz unter der angegebenen URL nicht erreicht werden kann oder wenn die Umgebung für den Klassenpfad nicht korrekt definiert ist). All diese Fehler werden vom SAX-Parser aufgeworfen. Zeile 22 veranlasst, dass die Anwendung anhält und zum Betriebssystem wechselt, wenn einer der bemerkten Fehler aufgefangen wird.
Die erste Methode im nächsten Abschnitt Ihrer Anwendung überschreibt die HandlerBase- Methode setDocumentLocator, die die URL des Dokuments angibt, das gerade vom SAX- Parser verarbeitet wird. Dabei handelt es sich um das Dokument, das der Anwender als Argument in die Befehlszeile eingibt, wenn die Anwendung aufgerufen wird. Erzeugen Sie eine Referenz auf den Dateinamen und die URL, genannt fname, und geben Sie sie an die getSystemId-Methode weiter. Sie verwenden das Standard-Ausgabeobjekt System.output. printlin, um den Prozessor anzuweisen, den String Name des Dokuments: zu drucken, der zum URL-String verkettet ist, den fname.getSystemId() enthält. Um dies zu erreichen, müssen Sie die folgende Methode erzeugen:
public void setDocumentLocator( Locator fname )
{
System.out.println( "Name des Dokuments:" + fname.getSystemId() );
}
Als Nächstes weisen Sie den SAX-Parser an, eine Meldung zu machen, wenn er auf den Dokumentanfang oder den Wurzelknoten des Dokuments trifft. Sie überschreiben die HandlerBase-Methode startDocument. Dieser Event kommt in jeder Dokument-Instanz nur einmal vor. Sie rufen das Standard-Ausgabeobjekt auf, um die Tatsache zu melden, dass der SAX-Parser auf den Wurzelknoten des Dokuments getroffen ist. Die Meldung erfolgt in Form eines Strings - SAX Event - Start des Dokuments - der auf dem Bildschirm des Anwenders ausgegeben wird. Bei allen SAX-Methoden, die Sie erzeugen, schließen Sie throws SAXException ein, um den Parser anzuweisen, alle angetroffenen Fehler aufzuwerfen. Sie erinnern sich gewiss, dass die main-Methode Anweisungen enthält, Fehler aufzufangen, an den Anwender zu melden und die Verarbeitung des Dokuments anzuhalten. Die vollständige Methode sieht so aus:
public void startDocument()
throws SAXException
{
System.out.println( "SAX Event - Start des Dokuments" );
}
Das Ende des XML-Dokuments wird vom SAX-Parser als Event betrachtet und es kann eine Methode eingefügt werden, die das Auftreten dieses Events meldet. Das ähnelt dem Event am Dokumentanfang, der bereits programmiert wurde, nur dass die endDocument- Methode der HandlerBase-Klasse in diesem Fall überschrieben wird. Die Methode sieht so aus:
public void endDocument()
throws SAXException
{
System.out.println( "SAX Event - Ende des Dokuments" );
}
Als Nächstes überschreiben Sie die HandlerBase-Methode startElement, um zu markie- ren, wenn der Parser in der XML-Instanz auf das Start-Tag für ein Element trifft. Die startElement-Methode nimmt zwei Argumente auf, jedes mit einer anwenderdefinierten Referenz. Das erste Argument enthält den Namen des Elements, das zweite eine Attributsliste für dieses Element. Da Sie in jedem Element null oder mehr Attribute antreffen können, müssen Sie einen Mechanismus bereitstellen, der entweder kein Attribut oder eine beliebige Anzahl an Attributen für ein Element meldet. Dann schreiben Sie eine kurze Schleife, die jedes Attribut durchläuft und alle mit dem entsprechenden Wert über das Standard-Ausgabeobjekt auf den Bildschirm schickt.
Wenn mehrere Attribute auf ein Element kommen, iterieren Sie sie, bis alle gemeldet wurden und keines mehr übrig bleibt. Außerdem formatieren Sie die Ausgabe des Attributsnamen-/Attributswerte-Paars mit Gleichheitszeichen und doppelten Anführungszeichen, die es erforderlich machen, dass Sie für die korrekte Wiedergabe Escape-Sequenzen verwenden. Um zum Beispiel ein doppeltes Anführungszeichen auszudrucken, müssen Sie die Escape-Sequenz (\") verwenden. Das Backslash-Zeichen in einem Java-String ist ein Escape-Zeichen, das verursacht, dass das Zeichen, das unmittelbar auf den Slash folgt, vom Java-Interpreten ignoriert und als Teil des Stroms weitergegeben wird, der erzeugt wird, um den String zu repräsentieren. In Java wird dies eine Escape-Sequenz im C-Stil genannt. Die vollständige startElement-Methode sieht so aus:
1: public void startElement( String el_name, AttributeList attr )
2: throws SAXException
3: {
4: System.out.println( "SAX Event - Element Start:" + el_name );
5: if ( attr != null )
6: for ( int i = 0; i < attr.getLength(); i++ )
7: System.out.println( "SAX Event - Attribute:"
8: + attr.getName( i )
9: + "=\ "" + attr.getValue( i )
10: + "\ "" );
11: }
![]()
Die Zeile 1 überschreibt die HandlerBase-Methode startElement, wenn der SAX-Parser auf ein Element trifft. el_name verweist auf den Namen des Elements, der das erste Argument dieser Methode ist, und attr verweist auf die Attributsliste für das Element. Zeile 2 verursacht, dass ein Fehler aufgeworfen wird, der an anderer Stelle aufgefangen wird, wenn ein Parsing-Fehler auftritt. Die Zeilen 3 und 11 zeigen jeweils Anfang und Ende der Methode mit geschweiften Klammern an. Das Standard-Ausgabegerät wird aufgerufen (Zeile 4), um das Auftreten eines SAX-Events zu melden, wenn die Methode aufgerufen wird. Die Zeilen 5-10 bestimmen, ob das Element Attribute hat. Wenn keine Attribute vorhanden sind, erhält attr den Wert Null und die for-Schleife wird nicht ausgeführt. Während der Ausführung werden alle Attributsnamen (getname) und ihre entsprechenden Werte (getValue) gemeldet, wobei jedes Paar in einer eigenen Zeile steht. Die AttributeList-Methode getLength liefert Ihnen die Anzahl der Attribute pro Element, sodass Sie eine Schleife erzeugen können, um alle möglichen Attribute der Reihe nach zu durchlaufen.
Das Schluss-Tag eines Elements wird von einem SAX-Parser ebenfalls als Event betrachtet, also schreiben Sie eine kurze Methode, die die angetroffenen Schluss-Tags meldet. Das entspricht den Methoden zum Dokumentanfang und -ende, nur dass Sie die endElement- Methode der HandlerBase-Klasse mit einem String überschreiben, der den Namen des angetroffenen End-Tags für das Element enthält.
public void endElement( String el_name )
throws SAXException
{
System.out.println("SAX Event - Element Ende:" + el_name );
}
Auch das Parsen der Zeichendaten in einem XML-Instanzdokument wird von SAX als Event angesehen. Die characters-Methode hat Variablen für Puffer sowie für die Offset- Werte und die Stringlänge der Zeichen. Sie deklarieren buf, offset und len jeweils als char[], int und int-Datentypen. Der voll qualifizierte String wird in die Variable namens stuff gesetzt und wie üblich über System.out.println gemeldet. Die Methode sieht folgendermaßen aus:
public void characters( char buf [], int offset, int len )
throws SAXException
{
if ( len > 0 ) {
String stuff = new String( buf, offset, len );
System.out.println( "SAX Event - Zeichen: " + stuff );
}
}
SAX kann auch Verarbeitungsanweisungen als Events melden. Die Methode processing Instruction nimmt zwei Argumente auf, die dem Systemnamen und dem Systemwert entsprechen, die von der Verarbeitungsanweisung an die Anwendung weitergegeben werden. Eine Verarbeitungsanweisung in einer XML-Dokument-Instanz sieht so aus:
<?message_reader incoming transactions?>
Sie setzt sich aus dem Systemnamen (message_reader) und einem Wert (incoming transactions) zusammen. Die vollständige Methode lautet:
public void processingInstruction( String part1,String part2 )
throws SAXException
{
System.out.println( "SAX Event - Verarbeitungsanweisung:"
+ part1 + " " + part2 );
}
Das ist die letzte Methode, die Sie in Ihr einfaches Java-Programm einschließen. Sie müssen die main-Methode schließen, indem Sie eine abschließende geschweifte Klammer (}) an das Ende des Listings setzen. Das komplette Programm sehen Sie in Listing 13.2. Speichern Sie Ihr Programm unter EList.java.
Listing 13.2: Das komplette Java-Programm EList-Klasse - EList.java
1: // Listing 13.2 - EList.java
2:
3: /*
4: mit javac kompilieren, sicherstellen, dass CLASSPATH die passenden
5: JAXP-Pakete enthält
6: */
7:
8: import java.io.*;
9: import org.xml.sax.*;
10: import javax.xml.parsers.SAXParserFactory;
11: import javax.xml.parsers.ParserConfigurationException;
12: import javax.xml.parsers.SAXParser;
13:
14: public class EList extends HandlerBase
15: {
16: public static void main( String fname[] )
17: {
18: if ( fname.length != 1 ) {
19: System.err.println( "Erwartete Syntax: java EList [filename]\ n" );
20: System.exit( 1 );
21: }
22:
23: SAXParserFactory saxFactory = SAXParserFactory.newInstance();
24:
25: /*Wenn Sie wollen, dass SAX ein XML-Dokument mit einer
26: DTD validiert, ändern Sie den Wert auf true*/
27: saxFactory.setValidating( false );
28:
29: try {
30: SAXParser saxParser = saxFactory.newSAXParser();
31: saxParser.parse( new File( fname[ 0 ] ), new EList() );
32: }
33: catch ( SAXParseException spe ) {
34: System.err.println( "Parser-Fehler:" + spe.getMessage() );
35: }
36: catch ( SAXException se ) {
37: se.printStackTrace();
38: }
39: catch ( ParserConfigurationException pce ) {
40: pce.printStackTrace();
41: }
42: catch ( IOException ioe ) {
43: ioe.printStackTrace();
44: }
45:
46: System.exit( 0 );
47: }
48:
49:
50: // URL-Pfad und Namen des Dokuments drucken
51: public void setDocumentLocator( Locator fname )
52: {
53: System.out.println( "Name des Dokuments:" +
fname.getSystemId() );
54: }
55:
56: // SAX Event - Start des Dokuments
57: public void startDocument()
58: throws SAXException
59: {
60: System.out.println( "SAX Event - Start des Dokuments" );
61: }
62:
63: // SAX Event - Ende des Dokuments
64: public void endDocument()
65: throws SAXException
66: {
67: System.out.println( "SAX Event - Ende des Dokuments" );
68: }
69:
70: // SAX-Events für Elemente und Attribute
71: public void startElement( String el_name, AttributeList attr )
72: throws SAXException
73: {
74: System.out.println( "SAX Event - Element Start:" +
el_name );
75: if ( attr != null )
76: for ( int i = 0; i < attr.getLength(); i++ )
77: System.out.println( "SAX Event - Attribute:"
78: + attr.getName( i )
79: + "=\ "" + attr.getValue( i )
80: + "\ "" );
81:
82: }
83:
84: // SAX Event - Element Ende
85: public void endElement( String el_name )
86: throws SAXException
87: {
88: System.out.println("SAX Event - Element Ende:" + el_name );
89: }
90:
91: // SAX-Event - Zeichendaten und Leerzeichen
92: public void characters( char buf [], int offset, int len ) >
93: throws SAXException
94: {
95: if ( len > 0 ) {
96: String stuff = new String( buf, offset, len );
97:
98: System.out.println( "SAX Event - Zeichen:" + stuff );
99: }
100: }
101:
102: // SAX-Event - Verarbeitungsanweisung
103: public void processingInstruction( String part1,String part2 )
104: throws SAXException
105: {
106: System.out.println( "SAX Event - Verarbeitungsanweisung:"
107: + part1 + " " + part2 );
108: }
109: }
Wenn Sie EList kompilieren wollen, müssen Sie die Umgebungsvariable CLASSPATH setzen oder die CLASSPATH-Option in die Compiler-Anweisung der Befehlszeile einfügen, um sicherzustellen, dass das erforderliche JAXP-Paket eingeschlossen wird. Die JAXP- Dokumentation hat vollständige Anweisungen dazu, wie dies erreicht wird. In Kürze gesagt: Sie können die Umgebungsvariable CLASSPATH in Windows mit der Befehlszeile setzen:
Set CLASSPATH=[dir]\ jaxp.jar;[dir]\ parser.jar;
[dir]\ crimson.jar;[dir]\ xalan.jar;.
In diesem Fall ersetzen Sie [dir] durch den Pfad, der auf die JAXP-Verteilung zeigt, die Sie vorher installiert haben. Nachdem die Umgebungsvariable gesetzt ist, kompilieren Sie das Java-Programm mit folgender Befehlszeilenanweisung:
javac EList.java
Damit das funktioniert, muss classpath korrekt eingerichtet werden, die Software Java 2- Standardausgabe (J2SE) korrekt installiert sein und das Unterverzeichnis bin im Pfad für die auszuführenden Dateien Ihres Betriebssystems liegen. Vollständige Anweisungen zum Setzen des Pfads und der classpath-Umgebungsvariablen stehen in der Dokumentation, die mit der J2SE und der JAXP-Software ausgeliefert wird.
Sie können auch die -classpath-Option in die Compile-Anweisung der Befehlszeile einfügen. Das geschieht in Windows durch Eingeben von
javac -classpath [dir]\ jaxp.jar;[dir]\ parser.jar;
[dir]\ crimson.jar;[dir]\ xalan.jar;. EList.java.
Da Java auf mehreren Plattformen läuft, können Sie diesen Code auch auf einem anderen Betriebssystem wie UNIX laufen lassen. Im UNIX-System sieht die Compile-Anweisung so aus:
javac -classpath ${ XML_HOME} /jaxp.jar:${ XML_HOME} /parser.jar:
${ XML_HOME} /crimson.jar:${ XML_HOME} /xalan.jar:. EList.java
In diesem Fall ist {XML_HOME} das UNIX-Verzeichnis, das die verteilten JAXP-Dateien enthält, die von der Anwendung gefordert werden.
Wenn die Anwendung kompiliert ist, können Sie sie ausführen, indem Sie folgende Befehlszeile einsetzen:
Java EList [file_name.xml]
Wenn Sie Ihre Anwendung erfolgreich kompiliert haben, führen Sie sie mit der nachricht01_13.xml-Datei aus, die in Listing 13.1 angegeben wird. Die Ausgabe sollte so aussehen:
Name des Dokuments: file:C:/SAX/nachricht01.xml
SAX Event - Anfang des Dokuments
SAX Event - Element Start: notiz
SAX Event - Zeichen:
SAX Event - Zeichen:
SAX Event - Element Start: nachricht
SAX Event - Attribute: von="Kathy Shepherd"
SAX Event - Zeichen:
SAX Event - Zeichen: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
SAX Event - Zeichen:
SAX Event - Zeichen:
SAX Event - Element Ende: nachricht
SAX Event - Zeichen:
SAX Event - Element Ende: notiz
SAX Event - Ende des Dokuments
In der vorangegangenen Übung haben Sie ein XML-Dokument geparst, das recht einfach aussah. Das XML-Dokument hatte zwei Elemente - eines mit einem Attribut, einigen Zeichendaten, einem Kommentar und einer XML-Deklaration. Die XML-Dokument- Instanz sah so aus:
<?xml version = "1.0"?>
<!-- listing 13.1 - nachricht01_13.xml -->
<notiz>
<nachricht von="Kathy Shepherd">
Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
</nachricht>
</notiz>
Neben anderen Events haben Sie sich entschieden, eine SAX-Parsermeldung für alle Events, Attribute und Zeichendaten einzusetzen. Die Ausgabe schien jedoch mehr Zeichenmeldungen zu enthalten, als Zeichendaten-Strings in der Dokument-Instanz vorhanden waren. Das Dokument schließt nur einen offensichtlichen Zeichendaten-String ein (Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen). Sie fragen sich vielleicht, warum es mehr Zeichen-Event-Meldungen in der Ausgabe gibt, die Ihre Java-Anwendung EList generiert. Das ist deshalb der Fall, weil SAX die Leerzeichen, die es antrifft, als Zeichen mitzählt und sie nicht normiert. Ohne DTD kann der Parser nicht entscheiden, ob ein Element zum Beispiel einen gemischten Inhalt hat. Da unser Dokument nicht durch eine DTD beschränkt wird, die Inhaltsmodelle für die Elemente in der Instanz deklariert und definiert, werden alle Leerzeichen von SAX als signifikant betrachtet; das hat zur Folge, dass alle Leerzeichen, die angetroffen werden, einen Event auslösen, den der Parser korrekterweise an den Anwender zurückgibt.
Testen Sie dies aus, indem Sie die Leerzeichen zwischen den Elementen in nachricht01_13.xml entfernen und parsen Sie die resultierende Datei erneut mit Ihrer EList-Anwendung. Speichern Sie das modifizierte XML-Dokument als nachricht02_13.xml, was wie die fortlaufende Dokument-Instanz aussieht, die Listing 13.3 zeigt.
Listing 13.3: Alle Leerzeichen wurden aus einem einfachen XML-Dokument entfernt - nachricht02_13.xml.
<?xml version = "1.0"?><!-- listing 13.3 - nachricht02_13.xml --><notiz><nachricht von
="Kathy Shepherd"> Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen </nachricht></notiz>
Wenn Sie das Dokument nach dem Entfernen der Leerzeichen parsen, ist das Resultat von EList um einiges kürzer.
Name des Dokuments: file:C:/SAX/nachricht02_13.xml
SAX Event - Anfang des Dokuments
SAX Event - Element Start: notiz
SAX Event - Element Start: nachricht
SAX Event - Attribute: von="Kathy Shepherd"
SAX Event - Zeichen: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
SAX Event - Element Ende: nachricht
SAX Event - Element Ende: notiz
SAX Event - Ende des Dokuments
Beachten Sie, dass die Zeichen-Events, die zuvor Leerzeichen enthielten, nicht länger in der Parsermeldung auftreten.
In der nächsten Übung machen Sie absichtlich einen Syntaxfehler im Dokument nachricht01_13.xml. Ändern Sie eines der Zeichen im Schluss-Tag des notiz-Elements hinsichtlich der Groß-/Kleinschreibung. Das Resultat wird interessanter, wenn Sie die Modifikation nahe am Ende der Dokument-Instanz vornehmen. Sie erinnern sich bestimmt, dass der SAX-Parser ein Event-basierter Prozessor ist. Deshalb ist zu erwarten, dass das Dokument korrekt verarbeitet wird und die erwarteten Meldungen ergibt, bis ein Fehler-Event aufgeworfen und in Ihrer main-Methode aufgefangen wird. Wenn Sie im Schluss-Tag des letzten Elements einen Syntaxfehler einfügen, wird alles bis zu diesem Element noch korrekt verarbeitet, aber das Schluss-Tag löst einen Fehler aus und der Dokumentende-Event kann nicht verarbeitet werden. Listing 13.4 zeigt das Nachricht- Dokument mit einem Fehler beim Schluss-Tag von notiz. Erzeugen Sie einen ähnlichen Fehler und speichern Ihr Dokument unter nachricht03_13.xml.
Listing 13.4: Eine schlecht geformte XML-Instanz zur Verwendung für Ihren
SAX-Prozessor - nachricht03_13.xml
1: <?xml version = "1.0"?>
2: <!-- listing 13.4 - nachricht03.xml -->
3: <notiz>
4: <nachricht von="Kathy Shepherd">
5: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
6: </nachricht>
7: </Notiz>
Wenn Sie dieses Dokument mit EList verarbeiten, sieht das zu erwartende Resultat so aus:
Name des Dokuments: datei:C:/SAX/nachricht03_13.xml
SAX Event - Anfang des Dokuments
SAX Event - Element Start: notiz
SAX Event - Zeichen:
SAX Event - Zeichen:
SAX Event - Element Start: nachricht
SAX Event - Attribute: von="Kathy Shepherd"
SAX Event - Zeichen:
SAX Event - Zeichen: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
SAX Event - Zeichen:
SAX Event - Zeichen:
SAX Event - Element Ende: nachricht
SAX Event - Zeichen:
Parser-Fehler: Erwartet "</notiz>" um das Element zu beenden, das in Zeile 3 beginnt.
Das Dokument wurde nach Art des Event-basierten Prozessors korrekt verarbeitet, bis der Fehler angetroffen wurde; dann wurde das Programm gemäß Ihrer Programmanweisungen angehalten und eine Fehlermeldung generiert. In diesem Fall war das Schluss-Tag </notiz> zu erwarten; statt dessen steht am Ende des Dokuments das Schluss-Tag </Notiz> (Zeile 7 von Listing 13.4).
Der JAXP-Parser kann verwendet werden, um eine XML-Instanz mit einem Schema zu validieren. Wenn Sie die Eigenschaft setValidating für das saxFactory-Objekt auf true setzen, können Sie JAXP anweisen, zu validieren.
saxFactory.setValidating( true );
Wenn Sie JAXP anweisen, zu validieren, können Sie neue Fehler auffangen (catch), die für Validierprobleme typisch sind. Sie können zum Beispiel Warnungen oder kleinere Validierprobleme, die der Parser ausgibt, auffangen, indem Sie minor- und warn-Methoden für das SAXParseException-Objekt aufrufen. Der Code, mit dem die minor- und warn- Methoden erzeugt werden, sieht so aus:
public void error( SAXParseException minor )
throws SAXParseException
{
throw minor;
}
public void warning( SAXParseException warn )
throws SAXParseException
{
System.err.println( "Warnung:" + warn.getMessage() );
}
Weitere Informationen über Fehlertypen, die SAX-Parser melden, finden Sie unter http:// www.java.sun.com/xml/download.html. Die Übung am Ende des heutigen Kapitels verwendet Fehlermeldungen, sodass Sie Ihr XML-Dokument mit einem zugeordneten Schema auf Gültigkeit austesten können.
Heute haben Sie das Simple API für XML (SAX) untersucht, ein XML-API, das Entwicklern gestattet, die Vorteile des Event-getriebenen XML-Parsings zu nutzen. Anders als die DOM-Spezifikation erfordert SAX nicht, dass die gesamte XML-Dokument-Instanz in den Speicher geladen wird. SAX benachrichtigt Sie, wenn bestimmte Events stattfinden, während es Ihr Dokument parst. Wenn Ihr Dokument umfangreich ist, spart die Verwendung von SAX im Vergleich zum DOM eine bedeutende Menge an Speicherplatz. Das trifft besonders dann zu, wenn Sie nur wenige Elemente für ein umfangreiches Dokument benötigen.
Frage:
Nach welchen Kriterien wählt ein Programmierer zwischen SAX- und DOM-API?
Antwort:
Das DOM ist für eine Reihe von Verarbeitungszwecken hervorragend geeignet.
Sie sollten DOM den Vorzug geben, wenn Sie willkürlichen Zugriff auf Ihr
Dokument haben wollen, um komplexe Suchvorgänge zu implementieren. In
Fällen, wo Sie komplexe XPath-Filterungen auflösen und XML-Dokumente
modifizieren und speichern müssen, bietet DOM mehr Möglichkeiten.
Antwort:
SAX erbringt eine bessere Leistung, wenn Ihre XML-Dokumente umfangreich
sind. In Fällen, in denen ein Prozessor abbrechen soll, wenn ein Fehler auftritt,
jedoch ansonsten eine normale Verarbeitung stattfindet, kann SAX mit
Programmsteuerung implementiert werden. Wenn Sie kleine
Informationsmengen aus umfangreichen Instanzen ermitteln und den Aufwand
für die Instanzierung des DOM umgehen wollen, heißt die Antwort SAX.
Frage:
Wie verwendet ein Programmierer SAX?
Antwort:
Sie erzeugen eine Instanz des XML-Parsers, indem Sie das SAX-Objekt
instanzieren. Sie müssen ein Programm schreiben, das als SAX-Reader fungiert,
das Events auffangen und melden kann, die er während der Ausführung antrifft.
Ändern Sie Ihre SAX-basierte EList-Anwendung, sodass sie XML-Instanzen mit deklarierten DTDs validiert. Speichern Sie die modifizierte Anwendung als EList2 und kompilieren Sie sie erneut. Verwenden Sie die Version Ihrer CD.xml-Datei, die der CD.dtd- Datei zugeordnet ist, die Sie am 4. Tag erstellt haben.
Wenn alles so funktioniert wie es soll, machen Sie einen absichtlichen -Validierungsfehler, keinen Syntaxfehler, indem Sie ein neues leeres Element einfügen, das nicht in der DTD deklariert wird. Sehen Sie sich die Resultate an, die SAX zurückgibt.
