




Immer mehr traditionelle Computer-Applikationen in Unternehmen setzen heute auch ganz allgemein XML-Technologien ein. Eine Vielzahl von Enterprise-Systemen, die darauf ausgelegt sind, Informationen zu verbreiten, Daten und Applikationen zu integrieren oder einen maximalen Wissensfluss zu gewährleisten, sind bestens für XML- Lösungen geeignet. Die Verwendung von XML als Möglichkeit, Geschäftsprozesse zu verbessern und neue Gelegenheiten zu schaffen, ist zu einem strategischen Ziel für viele Organisationen geworden. Heute lernen Sie die folgenden Dinge kennen:
Dieses Buch hat Ihnen viele verschiedene Technologien vorgestellt, die XML einsetzen, und wie sie helfen, strukturierte Informationen auszutauschen. Sie kennen die Standards und Vorschläge, die XML charakterisieren. Sie haben die Mechanismen hinter XML kennen gelernt und Sie haben verschiedene Ansätze zur Manipulation der Anzeige von XML-Daten angewendet. Heute werden Sie erfahren, wie XML für die Bereitstellung integrierter Geschäftsapplikationen genutzt werden kann. Dazu werden verschiedene Applikationsszenarien gezeigt ebenso wie die Aufgaben, die aus der Perspektive der Unternehmen zu erfüllen sind, die Vorteile von XML, Betrachtungen zur Architektur sowie eine Diskussion, wie Sie Lösungen schaffen können, die auf XML-Technologien basieren. Später werden Sie Gelegenheit erhalten, mithilfe von serverseitigem Scripting - wie beispielsweise Active Server Pages (ASP) - eine funktionierende Lösung für den Datenaustausch zu schaffen. Dabei extrahieren Sie die in einer Datenbank gespeicherten Daten und zeigen sie als XML-Datenmenge an. Anschließend schreiben Sie serverseitige Scripts, um Daten von der Datenbank in eine virtuelle XML-Struktur zu verschieben, die zu den Tabellenelementen auf einer HTML-Seite gebunden werden kann, um die Darstellung im Browser vorzunehmen.
Einer der typischen Schritte bei der Erstellung von XML-Applikationen ist die Analyse von Dokumenten, um festzustellen, wie sie am besten mit Markup versehen werden. Möglicherweise wollen Sie ein gedrucktes Dokument oder vielmehr eine ganze Klasse von Dokumenten - beispielsweise Bedienungsanleitungen, Memos, Rechtsgrundlagen, Verträge oder Speisekarten - in XML-Instanzen umwandeln. Manchmal wird für eine solche Umwandlung ein existierendes Schema verwendet, das die Struktur eines Dokuments definiert, aber manchmal muss man auch ganz von vorne beginnen, ohne dass man vordefinierte Elementtypen hat, die man anwenden kann. Egal wie Sie vorgehen, Sie müssen in jedem Fall Beispiele aus Ihrer Dokumentklasse sorgfältig analysieren, um ihre Struktur und ihren Aufbau zu verstehen.
Die Dokumentanalyse ist der Prozess, die Komponenten, Aufgaben und Anforderungen einer Dokumentklasse zu untersuchen, um eine detaillierte und definitive Beschreibung dafür entwerfen zu können. In der Praxis wird diese Beschreibung häufig als Dokumentanalysebericht bezeichnet, mit einer entsprechenden Menge an Schema- Anweisungen, die dazu dienen, die Struktur der Dokumente zu definieren. Sie könnten ein Public Domain-Schema oder ein kommerziell verfügbares Schema für die Definition einer bestimmten Dokumentklasse anwenden, aber dennoch ist weiterhin eine Analyse erforderlich, um sicherzustellen, dass es sich um eine ideale Lösung handelt. Ist dies nicht der Fall, erlaubt Ihnen die Natur der XML-Schemata, sie nach Bedarf zu erweitern.
Der wichtigste Faktor für die Erstellung einer genauen und sinnvollen Beschreibung aller Dokumentklassen ist das Sammeln exakter und sinnvoller Informationen über die Dokumente, aus denen sich die Klasse zusammensetzt. Die beste Quelle für diese Information ist nicht immer die Auswertung der Dokumente, sondern die Befragung von Personen, die für das Erstellen und die Wartung der Dokumente verantwortlich sind. Wenn Sie die Aufgaben und Anforderungen für die Dokumente nicht kennen, könnten die von Ihnen abgeleiteten Strukturen zufällig und ungenau sein.
Mit anderen Worten, nur die Eigentümer von Dokumenten wissen, was für diese sinnvoll und wichtig ist. Wenn Sie die Rolle des Dokumentanalytikers übernehmen, werden Sie feststellen, dass Sie Informationen einzelner Anwender sammeln und weniger aus realen Beispielen für die Klasse. Eine Stichprobe aus den Dokumenten ist häufig unvollständig und lässt keine Schlüsse zu. Darüber hinaus bietet die Analyse von Dokumenten allein selten alle Informationen, die Sie benötigen. Es ist unabdingbar, dass Sie die Datenkomponenten oder die Dateneinheiten und ihre Zusammenhänge verstehen, um ein System entwerfen zu können, in dem diese Daten verwendet werden.
Mit oder ohne die Hilfe der Dokumenteigentümer umfasst die Analyse die Identifikation und Definition der Komponententeile einer Dokumentenklasse mit ausreichender Genauigkeit, um die darzustellenden Daten durch die Anwendung strukturierter Tag- Mengen zu kodieren. Welche Genauigkeit Sie dafür wählen, kann eine der schwierigsten Entscheidungen in den frühen Phasen der Dokumentanalyse sein. Zu wenige Details führen zu einem zweifelhaften Ergebnis und zu viele können einen Aufwand bedeuten, der jeden Nutzen zunichte macht. Wie bei jedem Projekt der Softwareentwicklung sind die Analysephasen kritisch für den Erfolg, die Rechtzeitigkeit und die Kosteneffizienz der Arbeit.
Das Ergebnis einer sorgfältigen Analyse führt zur Übernahme oder Erstellung eines Markup-Vokabulars, um eine Dokumentklasse zu beschreiben. Weil XML durch die von Autoren erzeugten Elementtypen charakterisiert ist, sollten alle gemeinschaftlichen Bemühungen, ein Markup-Vokabular zu erstellen, sorgfältig überwacht werden. Angenommen, Sie arbeiten in einem Team an der Entwicklung einer Markup-Sprache für das Buchhaltungssystem des Unternehmens. Wenn jedes Teammitglied ein eigenes Tag für Bestellauftragsnummern einführt - wie beispielsweise BA-Num, Bestell_Auftrags_Nummer, BA_Nummer, BAN oder B_A_Num -, und womöglich auch unterschiedliche Elementtyp-Namen für andere Komponenten Ihres Buchhaltungssystem entwirft, ist der Aufwand, das System irgendwann unter einem gemeinsamen Vokabular zu vereinheitlichen, möglicherweise nicht mehr zu rechtfertigen. Die vollständige Analyse sollte also abgeschlossen sein, bevor der Markup-Prozess beginnt, und das Vokabular sollte gemeinsam definiert (oder übernommen) und beschrieben werden, bevor Dokumente umgewandelt werden.
Um ein effektives Markup sicherzustellen, müssen Sie viel über die Ziele des Systems wissen, das Sie entwickeln. Ist ein Ziel beispielsweise, Informationen effizient abzurufen, wiederzuverwenden und auszutauschen, müssen Sie die Elementnamen, die Elementdaten-Zusammensetzung sowie die Definition von Auswertungsfehlern für Elementtypen äußerst exakt festlegen.
Vielleicht sind Sie der Meinung, ein Gruppenansatz sei für die meisten Analyseprojekte von XML-Dokumenten am effektivsten, aber achten Sie auch hier darauf, dass nicht mehrere verschiedene Elementtypen angelegt werden, die alle dieselben Daten beschreiben. Im Fall einer Interessensgruppe oder eines Unternehmens könnte das Ziel sein, ein einziges gültiges Vokabular für den Datenaustausch außerhalb des Bereichs Ihrer unmittelbaren Kontrolle anzulegen. Wenn Sie in einem Industriezweig arbeiten, der diesen Prozess bereits durchlaufen hat, können Sie möglicherweise ein existierendes Schema verwenden. Im Internet gibt es mehrere Quellen für industriespezifische Schemata:
Wenn Sie keines dieser Industrieschemata übernehmen können, macht es Ihnen möglicherweise keine größeren Probleme, abhängig von der Dokumentstruktur ein neues Schema zu erstellen. Natürlich müssen Sie die Tag-Menge kennen, die in den Elementen enthaltene Information sowie die Beziehung der Elemente zueinander, was das Auftreten, die Reihenfolge usw. betrifft.
Es gibt verschiedene formale Ansätze für die Analyse und einige proprietäre Systeme bieten eine Anleitung für diesen Prozess. Die meisten dieser Ansätze haben bestimmte Qualitäten gemeinsam und wollen ähnliche Bedürfnisse abdecken. Die Analyse hilft, die Sammlung relevanter und sinnvoller Daten für die Modellierung zu formalisieren. Durch die Formulierung eines Schema- oder Analyseberichts legen Sie ein Grundgerüst oder eine grundlegende Infrastruktur für die Hierarchie der Datenkomponenten und die Möglichkeiten des Datenaustauschs fest.
Vielleicht stellen Sie einen nützlichen Nebeneffekt dieses Aufwands fest, nämlich dass äußerst detaillierte Metadaten erstellt werden, die die Suchvorgänge in Hinblick auf den Kontext oder auf exakte Übereinstimmungen in Ihren Dokumenten wesentlich verbessern können. Wenn Sie die Information in Strukturen ablegen - wie beispielsweise Schlussfolgerungen, Komponentenlisten, Prozeduren, Autoren, Zweck und Position - können Sie Kontext-Datenverweise erstellen.
Die Anforderungsdefinition ist einer der wichtigsten Schritte beim Analyseprozess. Anforderungen steuern Entscheidungen in Hinblick auf die Architektur, die Analyse und den Entwurf von Systemen. Ein klares Verständnis für die Anforderungen ermöglicht Ihnen, eine geeignete Granularität für die Elementdefinition festzulegen. Anforderungen ermöglichen Ihnen, gegebenenfalls akzeptable Abwägungen zu treffen, falls zwischen Entwurf und Implementierungsaufwand ein Konflikt besteht. Bei der Formulierung der Anforderungen können Sie die folgenden Aussagen treffen:
Von ähnlich wichtiger Bedeutung für die Definition der Anforderungen ist die Festlegung des Gültigkeitsbereichs. Er hilft Ihnen, das »Informationsuniversum« einzurichten, das die Grenzen Ihres Markups definiert. Häufig soll ein Projekt einen existierenden Gültigkeitsbereich vergrößern oder verkleinern. Sie sollten verstehen, welchen Einfluss diese Änderungen haben. Beispielsweise könnte die Frage lauten, ob eine Klasse von Marketingdokumenten erweitert werden muss, um neu entwickelte Produkte abzudecken. Und falls das so ist, welche Auswirkungen hat dieser Geschäftsplan auf Ihre Applikation? Bietet Ihr Entwurf Platz für erwartete Erweiterungen?
Die Einrichtung der Elementmenge kann relativ schwierig sein. Vielleicht müssen Sie dabei berücksichtigen, ob existierende Dokumenttypen für Ihre vorgeschlagenen Elemente geeignet sind. Manchmal werden gedruckte Dokumente so angelegt, wie es am bequemsten ist, und nicht einer optimalen Struktur entsprechend. Vielleicht gelangen Sie ja auf diese Weise auch zu einer XML-Instanz, die mehrere gedruckte Dokumente beinhaltet, ebenso wie die Routing-Information, die den Benutzern der Daten bekannt ist.
Nachdem Sie die Granularität der Informationsmenge eingerichtet haben, können Sie die Elemente abhängig davon festlegen, was sinnvoll, wiederverwendbar, durchsuchbar usw. ist. Das kann eine sehr komplexe Aufgabenstellung sein. Wie entscheiden Sie, wie viel Details zu viel sind? Für ein bestimmtes Markup-Problem gibt es möglicherweise überhaupt keine ideale Lösung; das Speichern und Verwalten von Daten, die Sie nie nutzen werden, ist jedoch aufwändig und teuer.
Die Identifizierung von Elementen bedingt, dass Sie Selektivität und Sensitivität für die Daten und Ihre Struktur entwickeln. Beispielsweise könnte ein Memo vom rein strukturellen Standpunkt her gesehen Abschnitte, Überschriften, Absätze, Wörter und Interpunk-tionszeichen enthalten. Bei der inhaltsabhängigen Analyse kann dasselbe Dokument aber auch so beschrieben werden, dass es die Komponenten »An«, »Von«, »Thema«, »Datum«, »Betreff« und »Rumpf« enthält.
Für den Teil der Analysephase ist es erforderlich, dass Sie die Beziehungen zwischen den Informationskomponenten verstehen. Beispielsweise könnte es wichtig sein zu wissen, ob Ihre Elemente hierarchische Tendenzen haben. Elemente sind Container, Sie sollten also wissen, was sich in diesen Containern befindet. Angenommen, Sie erzeugen eine XML- Datei, die Daten aufnimmt, die in einer Applikation für Buchführungsberichte übergeben werden. Ein Container für Buchhaltungstransaktionen kann beispielsweise einen Bezeichner enthalten, wie etwa eine Journal-Nummer oder eine oder mehrere Aktionen. Eine Aktion wiederum kann eine Kontonummer, einen Betrag und ein Attribut enthalten, das angibt, ob es sich um eine Kreditoren- oder Debitoren-Aktion handelt.
Aus Ihrer Arbeit mit Schemata wissen Sie, dass auch die Elementreihenfolge, die Nummerierung von Attributwerten und die Festlegung, ob Element oder Attribute zwingend erforderlich sind, eine wichtige Bedeutung haben. Durch die Analyse werden Abhängigkeiten deutlich. Durch die Kenntnis dieser Beziehungen können Sie das System besser definieren.
Sie haben bereits einige Techniken kennen gelernt, die helfen, statische Informationen zu analysieren, wie beispielsweise gedruckte Dokumentationen. Wenn Sie XML auf Grundlage einer existierenden Datenbank erstellen, sollten Sie nicht vergessen, das Daten- Dictionary als Quelle für strukturelle Details zu verwenden. In den nachfolgenden Abschnitten werden Sie mehrere typische Geschäftsprobleme kennen lernen, für die die XML-Technologien eine Lösung darstellen können. In den meisten Fällen sind diese Systeme durch eine oder mehrere Datenbanken charakterisiert, die Informationen enthalten, die als XML-Dokumente ausgetauscht werden können.
Die Verwendung von XML-Technologien für Enterprise-Applikationen wird immer beliebter. Die leistungsfähige Kombination von Schemata für die Auswertung, XSL für die Stilzuordnung und XML für das intelligente Speichern eignet sich bestens für das Erstellen effizienter Enterprise-Lösungen, die wichtige Vorteile für die Unternehmen darstellen können. Die Einführung dieser Technologien führt häufig zu einer verbesserten Effizienz der Geschäftsprozesse, zu Verbesserungen bei der Ausführung Transaktions-basierter Prozeduren sowie einer Einrichtung neuer Geschäfts-Paradigmen. Mit diesen Zielen im Hinterkopf stellt die Verwendung von XML-Technolgien für viele Unternehmen ein strategisches Ziel dar. Im nachfolgenden Abschnitt erhalten Sie die Gelegenheit, die geschäftlichen Einflüsse und Vorteile einzusehen, die durch XML in verschiedenen Szenarien erzielt werden können. Dabei handelt es sich nur um Beispiele von Applikationen, die mit XML möglich sind. Lesen Sie sich diese Beispiele durch und überlegen Sie, wie XML und die Technologien, die Sie kennen gelernt haben, die Leistung der beschriebenen Applikationsklassen verbessern. Anschließend überlegen Sie, wie ähnliche Ansätze Geschäftsprobleme in Ihrem Unternehmen lösen könnten. Für jedes Szenario der Enterprise-Applikationen werden die folgenden Informationen bereitgestellt:
Angenommen, Sie wollen Technologien für den Austausch von Daten verwenden, um einen Entwicklungsprozess in Ihrem Unternehmen zu verwalten und zu koordinieren. Vielleicht entwickeln Sie gerade ein neues Produkt oder vermarkten eine neue Dienstleistung. Vielleicht wollen Sie die Entwicklungsdaten für die gemeinsame Nutzung durch verschiedene Abteilungen Ihres Unternehmens ermöglichen, sodass Entscheidungen in Hinblick auf Herstellung, Marketing usw. getroffen werden können. Abhängig von der Größe Ihres Projekts brauchen Sie ein System, das den Datenfluss einrichtet, überwacht und verwaltet. Ihre Mitarbeiter an dem Projekt können intern oder extern sein, sodass eine flexible Methode für den Datenaustausch nötig ist. Überdies wollen Sie sicherstellen, dass der Umgang mit diesen wichtigen Daten zuverlässig ist.
Sie haben heute bereits einige der typischen Schritte für die Datenanalyse bei der Umwandlung in XML-Strukturen kennen gelernt. Vielleicht stellt die Information in diesen Dokumenten einen bestimmten Wert dar und der implizite Wert der Information ist die Rechtfertigung für den Aufwand, der entsteht, um diese Daten in eine auf XML basierende Lösung zu integrieren. Immer mehr Unternehmen produzieren Informationen, die an Kunden verkauft werden. Die Verteilung dieser Informationen ist häufig ein gemeinsamer Prozess, der der traditionellen Produktauslieferung entspricht. Die effektive, rechtzeitige, genaue und effiziente Auslieferung von Informationen kann einen Vorteil gegenüber der Konkurrenz für fast jedes Unternehmen der modernen Wirtschaft bedeuten. Der Verteilungskanal der Wahl für den Datenaustausch ist das Web geworden, weil es effizienten und globalen Zugriff erlaubt. Das Web erlaubt sowohl, Kunden und interne Mitarbeiter zu erreichen, als auch, relevante Informationen mit Geschäftspartnern und Kunden auf der gesamten Welt auszutauschen.
Wie in den Kapiteln 1 und 2 beschrieben, leidet HTML unter einigen Unzulänglichkeiten - obwohl es so gut wie überall unterstützt wird und plattformunabhängig ist. Werden strukturierte Daten benötigt, insbesondere solche, die aus einem dynamischen Zugriff auf verschiedene Quellen stammen, ist HTML im besten Fall aufwändig. Durch den Aufbau einer systematischen Abfolge der XML-Technologien, die Sie in den letzten 18 Kapiteln kennen gelernt haben, können Sie diese Einschränkungen kompensieren und die auf Daten basierenden Informationen auf neue Weise bereitstellen.
Die Abtrennung von Stil und Inhalt in XML ist ein Faktor, der zu einer erfolgreicheren Implementierung dynamischen Dateninhalts auf Webseiten führt. Damit HTML in Applikationen zur Datenauslieferung verwendet werden kann, müssen Sie den Text in Standard-Markup-Tags umwandeln, die die Datenkomponenten reflektieren. Ohne die vielfältigen anderen Web-Technologien kann HTML dies nicht ausreichend unterstützen. Im Vergleich dazu sind XML und XLS sehr viel effizienter in Hinblick auf Skalierung und Kontrolle, wo sie alles übertreffen, was mit HTML möglich wäre. Darüber hinaus haben Sie in Kapitel 16 erfahren, dass Sie das Ergebnis jeder XML-Technologie wieder in HTML umwandeln können, um es allen Clients anzeigen zu können, die eine eigene HTML- Unterstützung aufweisen. In Kapitel 15 haben Sie erfahren, dass die Daten Ihrer Applikation den Benutzern sogar unter Anwendung von persönlichen Einstellungen bereitgestellt werden können.
Lokale Benutzer können Style Sheets verwenden, um sie auf die in XML gespeicherten Daten anzuwenden, und es können Applikationen entwickelt werden, die ohne Verwendung von Style Sheets direkt auf die Daten zugreifen. Später in diesem Kapitel werden Sie ein serverseitiges Script anlegen, das XML-Daten entgegennimmt und in einer HTML-Tabelle ablegt, die über das Web an fast jeden beliebigen Browser weitergegeben werden kann. Diese Stärken helfen, XML als überragende Technologie für die Weitergabe von Informationen zu charakterisieren - es ist mehr, als nur eine Seitendarstellungs-Technologie.
Web-basierte Architekturen sind für das Sammeln und die Verteilung von Informationen optimal geeignet. In einem typischen Szenario fordern Benutzer oder Kunden Informationen von einem Server an, der basierend auf Quellinformationen eine Antwort abruft oder erstellt. Dem resultierenden Dokument kann ein Style Sheet zugeordnet werden, es kann umgewandelt und irgendwann an den Client geliefert werden. Weil es noch keine allgemeine Unterstützung von XML auf Browserebene gibt, verwenden die meisten auf XML basierenden Systeme zum Sammeln und zur Weitergabe von Informationen eine serverseitige Vorverarbeitung vor der Anlieferung.
Sie sehen, dass auf diese Weise sowohl statischer als auch dynamisch erzeugter Inhalt verarbeitet werden kann. Statischer Inhalt könnte aus einer Sammlung vorverarbeiteter Dokumente stammen. Dynamischer Inhalt könnte unter Verwendung eines Datenintegrations-Servers gesammelt und aufgebaut werden. Jedenfalls bietet XML wesentliche Vorteile gegenüber auf HTML basierenden Lösungen, aber auch gegenüber Lösungen, die ausschließlich auf proprietären Mechanismen für den Aufbau von Daten basieren, wie beispielsweise Datenbanken. Das bedeutet natürlich nicht, dass Sie kein HTML oder keine Datenbanken verwenden sollen. Beide spielen eine Rolle für die endgültige Lösung. Sie verwenden diese Technologien dafür, wofür sie am besten geeignet sind - beispielsweise die Anzeige von Browserseiten oder das effiziente Speichern von indizierten Daten - und wenden geeignete XML-Technologien auf die Ergebnisse an, um eine optimale Lösung zu erzielen.
Wenn Sie eine solche Applikation erstellen, ermitteln Sie normalerweise die Art und die Klassen der zu verteilenden Dokumente und Daten und erstellen dann Schablonen für ihre Auslieferung. Eine Schablone kann aus einem Schema und einem oder mehreren Style Sheets bestehen. Für Dokumente mit statischem Inhalt können die Autoren Applikationen anwenden, um XML-Dokumente daraus zu erstellen. Das dynamische Erstellen von Dokumenten kann durch Applikationen automatisiert werden, die mit Datenbanken arbeiten und elektronisch gespeicherte Informationen ausliefern. Darüber hinaus können Geschäftspartner Teile des Inhalts elektronisch oder über einen Webzugriff bereitstellen, den dieser Prozess ebenfalls beinhalten kann. Wie Sie bereits gesehen haben, bieten Ihnen die Erweiterbarkeit und die Interoperabilität von XML-Technologien eine effiziente Möglichkeit, Schemata von Herstellern oder Geschäftspartner mit Ihren eigenen zu kombinieren.
In vielen Unternehmen werden viele fertige Softwarepakete sowie verschiedene benutzerdefinierte Lösungen eingesetzt. Auftragsbearbeitung, Ressourcenplanung im Unternehmen, Personalabteilung, Buchhaltung und Finanzwesen, Verkauf usw. basieren häufig auf unterschiedlichen Applikations-Softwarepaketen, die sogar auf verschiedenen Plattformen ausgeführt werden können. Das ist kein schlechter Entwurf oder das Ergebnis einer schlechten Geschäftsplanung; es ist nur eine Folge der Natur der verschiedenen Geschäftsapplikationen. Im Normalfall ist eine Geschäftsapplikation hoch spezialisiert, um bestimmte Aspekte des Geschäftsprozesses modellieren zu können. Um alle Bedürfnisse abzudecken, muss ein Unternehmen möglicherweise verschiedene Einzellösungen einsetzen. Ein Problem entsteht, wenn Daten aus einer Applikation mit Daten aus einer anderen kombiniert werden sollen. Herkömmliche Methoden für die benutzerdefinierte Integration sind teuer, langsam und arbeitsaufwändig und häufig benötigt man dazu externe Unterstützung durch Dienstleister, die auf die Integration von Geschäftsapplikationen spezialisiert sind, die manchmal auch als EAI (Enterprise Application Integration) bezeichnet werden.
Weil XML mit Daten zurecht kommt, die als Text abgelegt sind, bietet es Integrationsmöglichkeiten, die ganz einfach in Scripts ausgedrückt und für die unterschiedlichsten Zwecke kombiniert werden können. Die Natur intelligenter Datenspeicher ermöglicht Ihnen, sicherzustellen, dass Metadaten Teil der Übertragungs- Infrastruktur sind. Mehrere spezialisierte XML-Applikationen wurden entworfen, um eine Übertragung zwischen verschiedenen Applikationen zu ermöglichen. Beispielsweise erledigen Server-Lösungen von WebMethods (http://www.webmethods.com) und BizTalk (http://www.biztalk.org) die Übersetzung von Geschäftslogik zwischen Applikationen. Obwohl sie etwas über den Rahmen dieses Kapitels hinausgehen, sollten Sie diese auf XML basierenden Lösungen kennen, die auch dann in der Lage sind, eine komplexe Applikations-Integration zu erledigen, wenn sich diese Applikationen in unterschiedlichen, über das Internet verbundenen Unternehmen befinden. Morgen werden Sie SOAP (Simple Object Access Protocol) kennen lernen und erfahren, wie eine vollständig plattformunabhängige Lösung eine Möglichkeit bieten kann, externe Objekte über in XML- Container eingeschlossene Methodenaufrufe anzusprechen.
Die Architektur für die Applikations-Integration unter Verwendung von XML beinhaltet die Übertragung von mit XML kodierten Daten von einem Programm zu einem anderen über ein lokales Netzwerk oder tatsächlich über das Internet. Später in diesem Kapitel werden Sie eine HTML-Applikation erstellen, die sich auf einem Webserver befindet. Wenn diese Applikation geladen wird, startet sie ein separates serverseitiges Script, das in VBScript geschrieben ist. Das Script fragt eine Microsoft Access-Datenbank mithilfe einer SQL-Anweisung ab und gibt einen XML-Datenstrom zurück. Die HTML-Applikation bindet die XML-Elemente unter Verwendung einer einfachen Objekt-Datenbindung und zeigt die Tabelle auf einer Webseite an. Dies ist nur ein Beispiel für die Natur der interoperablen Integration, die durch XML ganz einfach bewerkstelligt werden kann.
Wie die Applikation, die Sie später erstellen werden, umfasst der Prozess für die Entwicklung der Integration mehrere systematische Schritte. Im Wesentlichen entwickeln Sie dafür eine Protokoll-Engine oder verwenden eine bereits existierende, die eine Anforderungsanweisung formatieren kann. Die Anforderung sollte in der Lage sein, eine Verbindung zu einem Webserver aufzubauen, um eine Applikation auszuführen, die sich auf dem Host befindet. Die Host-Applikation verarbeitet die Anforderung und erzeugt eine Antwort, die an die anfordernde Applikation zurückgegeben wird. Anschließend erzeugen Sie eine Abbildungsebene, die die in der Antwort enthaltenen Daten in Strukturen übersetzt, die von der lokalen Applikation verarbeitet werden können.
Manchmal befinden sich die Daten, die Sie benötigen, nicht in einer einzigen Datenbank. Sie können sich in mehreren Datenbanken befinden und diese müssen sich nicht unbedingt im selben Unternehmen befinden. Eine Klasse von Applikationen, die auch als Applikationen für die Datenintegration bezeichnet werden, kann die Anforderung erfüllen, Daten zu sammeln und kombiniert auszugeben. Diese Art der Integration kann Zeit und Aufwand für Angestellte sparen, die Daten aus unterschiedlichen Quellen konsolidieren müssen, um komplexe Geschäftstransaktionen zur realisieren. Die Kosten für die Ausführung einzelner Applikationen können als die Summe der gesamten unabhängig voneinander ausgeführten Verarbeitungen plus der manuellen Schritte für die Konsolidierung der Ergebnisse oder die Erstellung eines übergreifenden Berichts betrachtet werden. Die Automatisierung dieser Prozesse ist für die Unternehmen häufig sehr wirtschaftlich.
Die zentralisierte Synthese komplexer Geschäftsdaten charakterisiert eine überlebensfähige Lösung für Applikationen zur Datenintegration. Praktisch ausgedrückt, die Applikationen benötigt wahrscheinlich multidirektionalen Zugriff auf eine Vielzahl von Komponentenprozessen. Hier werden die Vorteile von XML sofort deutlich. Mit anderen Worten könnte die resultierende Synthese als Eingabe oder Feedback für Komponenten-Applikationen in der Datenintegrationsschleife benötigt werden. Die Möglichkeiten der XML-Technologie für die Bereitstellung eines interoperablen Datenaustausches könnte sie in einigen Fällen zum de facto-Format für Geschäftstransaktionen machen. Viel davon ist auf Client-Seite relevant, wo die Unterstützung von XML immer noch schwach ist, aber die Entwicklung dagegen schnell. Bis dahin kann die Synthese auf Servern realisiert werden und in den verschiedensten Formaten über die unterschiedlichsten Methoden an die Clients geschickt werden.
Normalerweise basieren die Lösungen für die Datenintegration auf einer Architektur, die durch einen Integrationsserver charakterisiert ist, der zwischen einer Vielzahl von Client- Applikationen auf der einen Seite und mehreren Datenbanken oder Datenquellen auf der anderen Seite sitzt. Die Datenquellen können Datensätze sein, Dateien in einem Dateisystem oder Applikationen. Die einzige Forderung ist, dass man extern darauf zugreifen können muss. Der Integrationsserver nimmt die Daten aus diesen Quellen entgegen, setzt sie zu XML-Datenströmen zusammen und übergibt sie den Client- Applikationen in einem für sie lesbaren Format. Er könnte auch aktualisierte Informationen von einer Client-Applikation entgegennehmen, sie in ihre Komponenten zerlegen und in einem geeigneten Datenbehälter speichern. Der Zugriff auf die Datenquellen kann unter Verwendung nativer XML-Mechanismen oder über andere Datenbank- oder Dateisystemtransporte erfolgen, wie beispielsweise JDBC (Java Database Connectivity), ODBC (Open Database Connectivity) oder proprietäre APIs.
Heute haben Sie Architekturen kennen gelernt, die normalerweise in einem Drei- Schichten-Client-Server-Modell eingesetzt werden. Diese Architektur ist eine spezielle Form der Client-/Server-Architektur, die aus drei wohl definierten und separaten Prozessen besteht, die auf unterschiedlichen Plattformen ausgeführt werden.
Die Benutzerschnittstelle, die auf dem Computer des Benutzers (d.h. des Clients) ausgeführt wird, wird häufig durch eine Browser-Applikation charakterisiert. Diese Schicht könnte auch durch jeden anderen clientseitigen Benutzeragenten wie beispielsweise ein webfähiges funkgesteuertes Gerät, Handy oder PDA, repräsentiert werden. Dies ist die erste von drei Schichten, die häufig als die Benutzer- oder Client-Schicht bezeichnet wird.
Die Mittelschicht enthält die funktionalen Module, die die Daten verarbeiten. Diese Mittelschicht wird auf einem Server oder auf mehreren Servern ausgeführt, wovon einer den Applikationsserver darstellt. Eine weitere Server-Klasse, die Webserver, sind ebenfalls in der Mittelschicht angeordnet und dienen häufig als Portal für andere Mittelschicht- Applikationen. Die Applikation zur Weitergabe und Aggregation von Informationen, die Sie früher in diesem Kapitel kennen gelernt haben, ist ein Beispiel für eine Applikation, die sich auf der Mittelschicht befinden kann. Auf Mittelschicht-Servern wird das serverseitige Scripting verwaltet und ausgeführt. Angenommen, Sie besuchen einen Online-Buchladen; nach dem Zugriff begrüßt Sie die Website mit Ihrem Namen und stellt Ihnen neu erschienene Bücher vor, die Ihren Bestellungen in der Vergangenheit entsprechend für Sie interessant sein könnten. Vielleicht kaufen Sie häufig Bücher wie dieses - über Programmierung.
Die Personalisierungs-Applikation wird auf der Mittelschicht ausgeführt. Sehr wahrscheinlich liest sie die in einer Datenbank auf der Datenschicht abgelegten Datensätze, um festzustellen, welche Kaufgewohnheiten Sie haben, verarbeitet die Ergebnisse in der Mittelschicht, schlägt in den Listen der Neuerscheinungen nach, ob Einträge mit Ihren »Vorlieben« übereinstimmen und präsentiert Ihnen auf der Client- Schicht ihre Vorschläge für ähnliche Titel, die Sie vielleicht auch kaufen wollen. Dies ist ein klassisches Beispiel für eine Drei-Schichten-Web-Applikation.
Wie bereits erwähnt, wird die dritte Schicht als die Datenschicht bezeichnet und enthält häufig ein Datenbank-Managementsystem (DBMS), das die von der Mittelschicht benötigten Daten enthält. Diese Schicht wird auf einem zweiten Server ausgeführt, dem Datenbankserver. Bestellerprofile und Online-Kataloge wie die in Ihrem Online- Buchladen werden normalerweise in Datenbanken auf der Datenschicht abgelegt.
Sie werden feststellen, dass XML auf oder zwischen allen diesen Schichten existieren kann. Die Applikations-Szenarien, die Sie heute bereits kennen gelernt haben, stellen Beispiele dafür dar, wie XML auf allen Schichten dieser beliebten Architektur verwendet werden kann. In den nachfolgenden Übungen werden Sie auf XML basierte Applikationen erstellen, die zwischen allen drei Schichten kommunizieren und auf allen drei Schichten arbeiten können. Dieses Modell, das die besten Vorgehensweisen für die Entwicklung verwendet, entspricht dem Ansatz, der auch von der W3C und den Webentwicklern empfohlen wird.
In den nachfolgenden Übungen werden Sie die Mittelschicht-Programmierung nutzen, um auf Daten zuzugreifen, die in einer Datenbank gespeichert sind. Anschließend werden Sie die Daten durch die Erstellung von XML-Strukturen auf einen Browser verschieben, wo die clientseitige Darstellung stattfindet. Die Beispiele verwenden die folgenden Technologien:
Um die Applikation nachzuvollziehen und zu erstellen, können Sie die angegebenen Komponenten-Technologien verwenden, wobei es nicht unbedingt eine Rolle spielt, welche Versionen Sie verwenden. Außerdem können Sie auch andere Komponenten verwenden, beispielsweise eine andere Datenbank oder eine Mittelschicht-Scriptsprache, und Ihren Entwurf auf der Funktionalität der gezeigten Modelle aufsetzen. Außer dem verwendeten XML können jedoch die anderen aufgeführten Komponenten-Technologien nicht genauer erklärt werden, weil dies den Rahmen dieses Buches sprengen würde. Die funktionalen Bestandteile der Code-Beispiele dieser Übung werden kurz besprochen, aber eine vollständige Beschreibung von SQL, IIS, VBScript, HTML und dem ODBC API oder Microsoft Access sollten Sie sich aus anderen Quellen beschaffen. Markt+Technik, der Verlag, bei dem dieser Titel erscheint, bietet ausgezeichnete Bücher zu all diesen Technologien.
![]()
Beachten Sie, dass die Microsoft-Produkte zu Demonstrationszwecken ausgewählt wurden. Sie können natürlich auch andere Produkte für Webserver und unterstützende Produkte einsetzen. Beispielsweise können Sie statt der oben gezeigten Folge auch Apache, Tomcat und MySQL einsetzen.
Wir bleiben bei der Metapher des auf XML basierten Nachrichten- und Erinnerungssystems und Sie erzeugen jetzt eine Datenbank mit einzelnen Nachrichten als Datensätze. Die Felder entsprechen den nachricht-Komponenten, die Ihnen bereits von früheren Kapiteln her vertraut sind, nämlich id, von, quelle und nachricht. Das Feld id ist ein autonumber key-Feld in der Datenbank. Alle anderen Felder haben den Datentyp text. Beachten Sie, dass diese Übung zwar eine Microsoft Access-Datenbank verwendet, Sie aber jede andere ODBC-konforme Datenbank verwenden können, die SQL unterstützt.
Um Ihre Datenbank mit Access zu erzeugen, starten Sie die Applikation und wählen im Popup-Fenster, das beim Starten der Applikation angezeigt wird, den Befehl Neue Datenbank erstellen und dazu verwenden | Leere Access-Datenbank, wie in Abbildung 19.1 gezeigt.
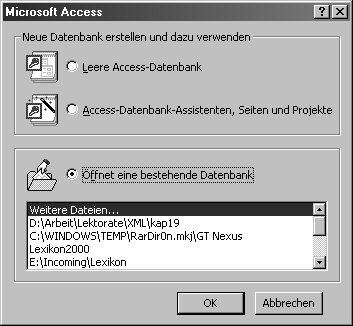
Abbildung 19.1: Eine neue Access-Datenbank anlegen
Ein Dialogfeld erscheint, in dem Sie aufgefordert werden, Ihre neue Datenbank zu speichern. Damit alle weiteren Schritte wie beschrieben funktionieren, erzeugen Sie ein neues Verzeichnis c:\tag_19 und legen Ihre Datenbank in diesem unter dem Namen nachricht. mdb ab. Sie können natürlich auch ein beliebiges anderes Verzeichnis verwenden, aber dann müssen Sie bei den nachfolgenden Schritten entsprechende Anpassungen vornehmen. Wenn Sie c:\tag_19 als Ihr Verzeichnis verwenden, sieht der vollständig qualifizierte Pfad zu Ihrer neuen Datenbank wie folgt aus:
C:\tag_19\nachricht.mdb
Nachdem Sie Ihre neue Datenbank gespeichert haben, wird das Hauptfenster für den Datenbankentwurf in Access angezeigt. Wählen Sie für das Tabellen-Objekt die Option Erstellt eine Tabelle in der Entwurfsansicht. Diese Option ist bereits hervorgehoben angezeigt. Abbildung 19.2 zeigt die Option an, die Sie auswählen sollten.
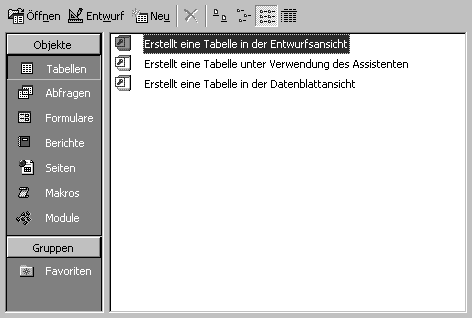
Abbildung 19.2: Die Entwurfsansicht in Microsoft Access
Geben Sie in jede der bereitgestellten Tabellenzeilen Details zu einem der Felder Ihrer neuen Tabelle ein. In Zeile 1 geben Sie als Feldnahme id ein und bewegen sich mithilfe der Tabulatortaste in die Spalte Felddatentyp. Wenn Sie in dieser Zelle der Tabelle auf den Pfeil nach unten klicken, wird eine Pulldown-Liste angezeigt. Wählen Sie den Eintrag AutoWert. Bevor Sie in das nächste Feld gehen, machen Sie dieses Feld zum Primärschlüssel-Feld, indem Sie in der Symbolleiste oben am Bildschirm auf das Symbol mit dem kleinen Schlüssel klicken oder indem Sie im Pulldown-Menü für die Zeile den Menüpunkt Primärschlüssel auswählen. Gehen Sie mithilfe der Tabulatortaste in die nächste Zeile dieser Tabelle, die dem nächsten Feld der Tabelle entspricht, die Sie anlegen wollen. Geben Sie als Feldnamen von ein und wählen Sie als Datentyp Text. Wiederholen Sie diesen Vorgang für die Felder quelle und nachricht, die beide den Datentyp Text haben. Ihr vollständiges Entwurfsansichts-Fenster sollte jetzt aussehen, wie in Abbildung 19.3 gezeigt.
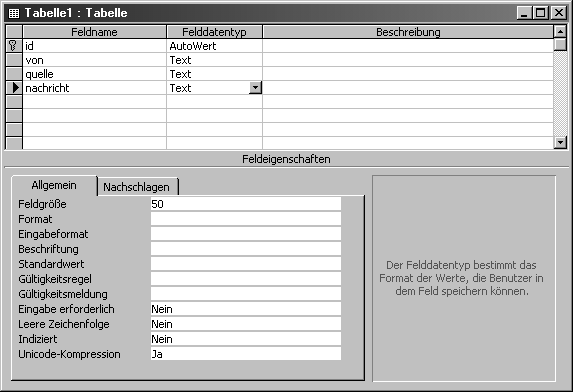
Abbildung 19.3: In der Entwurfsansicht erstellen Sie neue Datenfelder
Wählen Sie im Pulldown-Menü Datei den Eintrag Speichern unter und geben Sie Ihrer Tabelle den Namen nchr. Wählen Sie im Pulldown-Menü Ansicht den Eintrag Datenblattansicht. Jetzt können Sie Daten direkt in die Datenbank eingeben. In das Feld id brauchen Sie keinen Wert einzutragen, weil dies die AutoWert-Funktion von Access für Sie übernimmt. Gehen Sie mithilfe der Tabulatortaste in die erste von-Zelle und geben Sie einen Namen ein. Geben Sie weitere Daten in die Felder ein, um mehrere Datensätze zu erzeugen. Sie brauchen nicht dieselben Daten zu verwenden wie in Abbildung 19.4 gezeigt und Sie müssen sich auch nicht auf drei Datensätze beschränken, wenn Sie mehr eingeben wollen.
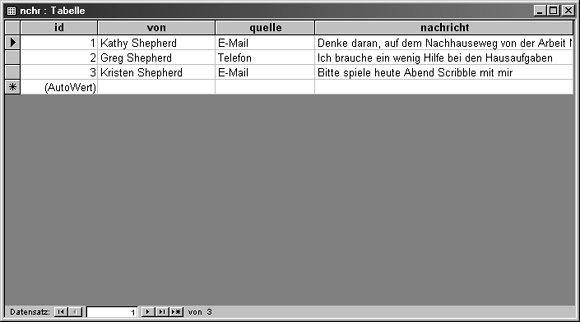
Abbildung 19.4: Die Tabelle nchr wurde mit Daten gefüllt
Jetzt können Sie die Datenbank schließen. Sie haben damit eine Datenbank mit Nachrichten angelegt, auf die Sie in einem späteren Schritt über das Scripting zugreifen können. Die Datenbank enthält Datensätze, die den einzelnen Nachrichten oder Erinnerungen entsprechen, ähnlich wie Sie sie in den letzten Kapiteln im XML dargestellt haben.
Wie Sie wissen, stellt eine Datenbank eine praktische und effiziente Möglichkeit dar, Daten zu speichern - komplett mit Index, Datenbanksicherheit und allen anderen Funktionsmerkmalen, die Unternehmen von dieser Technologie erwarten. Die meisten Unternehmen bewahren wichtige Daten in ihren Datenbanken auf. Häufig handelt es sich dabei um die Verlaufsdaten, die Sie benötigen, um dynamischen Webinhalt zu erzeugen, oder wenn Sie eine Verbindung zwischen Applikationen einrichten. Letztlich wollen Sie die Daten aus einer Datenbank in Form eines XML-Streams verschieben, sodass sie einfach in anderen Applikationen verwendet oder mit einem Stil versehen und an einen Client ausgeliefert werden kann.
ODBC-Werkzeuge (Open Database Connectivity) stellen wie die JDBC-Werkzeuge (Java Database Connectivity) eine Möglichkeit dar, auf eine Datenbank zuzugreifen, die durch die Instanziierung spezieller Client- und Server-Treiber-Software bereitgestellt werden. ODBC stellt Ihnen ein API (Application Programming Interface) bereit, das es ermöglicht, Daten aus einer Datenbank über eine vereinheitlichte Quelle zu extrahieren.
![]()
Weitere Informationen über ODBC finden Sie in Access 2000 Programmierung in 21 Tagen von Said Baloui, erschienen im Verlag Markt+Technik (ISBN: 3-8272-5705-0).
Sie nutzen ODBC, indem Sie mithilfe des Windows DSN-Administrationswerkzeugs eine benannte Quelle erzeugen. Damit erhalten Sie eine Verbindung zwischen der Datenbank, die durch einen Objektaufruf in einem Mittelschicht-Script durchsucht werden kann. Die DSN richtet einen benannten Verweis sowie einen Link zu dem Datenbank-Treiber (in Ihrem Fall für Microsoft Access) ein, der einer bestimmten Datenbank zugeordnet ist. Durch die Einrichtung dieser DSN stellen Sie eine direkte Verbindung zu Ihrer Datenbank durch das Betriebssystem bereit, die den Pfad durch das Dateisystem beinhaltet. Mit anderen Worten, wenn Sie ein Objekt anlegen, das eine Verbindung zu Ihrer DSN einrichtet, verwendet das Objekt ODBC, um auf die Datenbank zuzugreifen, sodass Sie SQL-Anweisungen übergeben können, um mit den Daten zu arbeiten. Das Datenbankobjekt richtet mithilfe seiner eigenen Methodenmenge eine Verbindung zur Datenbank ein. Die Verbindung bleibt bestehen, bis Sie sie mit einer Close-Methode im API schließen.
Um die DSN zu erstellen, brauchen Sie das ODBC-Datenquellen-Werkzeug. Für diese Übung brauchen Sie Windows 98/2000. Öffnen Sie die Systemsteuerung von Windows, indem Sie in der Windows-Symbolleiste auf die Start-Schaltfläche klicken und im Menüpunkt Einstellungen die Option Systemsteuerung auswählen. Wenn das ODBC-Datenquellen-Werkzeug angezeigt wird, gehen Sie auf die Registerkarte System- dsn. Achten Sie sorgfältig darauf, auf die Registerkarte System-dsn zu gehen, nicht auf Benutzer-dsn oder Datei-dsn.
![]()
Sie können entweder eine System-DSN oder eine Benutzer-DSN einrichten. Die Benutzer-DSN erlaubt dem Benutzer der DSN jedoch nur, über die Datenquelle auf die Datenbank zuzugreifen. Damit mehrere Benutzer auf der Maschine auf eine bestimmte Datenbank zugreifen können, müssen entweder mehrere Benutzer-DSNs oder eine System-DSN konfiguriert werden. Eine System-DSN erlaubt allen Benutzern einer Maschine, über diese Datenquelle auf die Datenbank zuzugreifen.
Es wird ein Fenster mit den existierenden DSNs angezeigt, falls solche vorhanden sind. Klicken Sie auf die Schaltfläche Hinzufügen. Ein neues Fenster wird angezeigt, das alle auf Ihrem Computer installierten Datenbank-Treiber auflistet. Falls auf Ihrem System Microsoft Access 2000 korrekt als Teil von Office 2000 installiert ist, sollte in dieser Liste ein entsprechender Treiber erscheinen. Wählen Sie den Microsoft Access Treiber (*.mdb) und klicken Sie auf die Schaltfläche Fertig stellen. Ein Fenster mit dem Titel ODBC Microsoft Access Setup wird angezeigt. Geben Sie in das Feld Datenquellenname nachrichtDB ein und achten Sie dabei unbedingt auf die Groß-/ Kleinschreibung.
Richten Sie die DSN wie hier gezeigt ein, um sicherzustellen, dass die von Ihnen in den nachfolgenden Schritten angelegten Scripts korrekt funktionieren. Klicken Sie in diesem Fenster auf die Schaltfläche Auswählen und suchen Sie im Dialogfeld Datenbankdatei auswählen Ihre Datenbank unter c:\tag_19\nachricht.mdb. An dieser Stelle sollte Ihr Bildschirm aussehen wie in Abbildung 19.5 gezeigt.
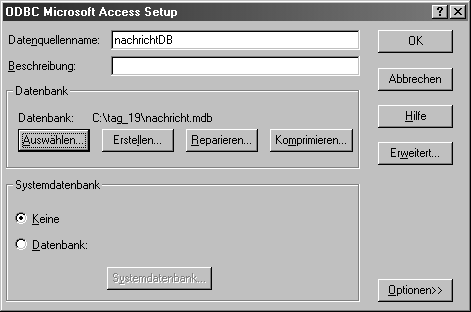
Abbildung 19.5: Einen Datenquellennamen mithilfe des ODBC-Werkzeugs anlegen
Schließen Sie alle Dialogfelder, indem Sie auf OK klicken.
In den nachfolgenden Übungen verwenden Sie IIS als Webserver, der über Ihren Webbrowser zur Verfügung steht. IIS stellt eine ausgezeichnete Möglichkeit dar, eine serverseitige Programmierung auf einem lokalen Host zu testen. Häufig entwickeln Programmierer Applikationen auf einem lokalen Host, wie beispielsweise IIS, und geben sie dann auf einen externen Host als Produktions-Websites weiter. Dafür gibt es auch andere Methoden, aber IIS stellt eine einfache Alternative dar, die gut funktioniert.
Um Microsoft IIS (Internet Information Services) in nachfolgenden Schritten als Webserver verwenden zu können, registrieren Sie Ihr Verzeichnis c:\tag_19 als Web- Freigabe-Verzeichnis. Dazu suchen Sie im Windows Explorer Ihr Verzeichnis c:\tag_19. Klicken Sie im Explorer-Fenster mit der rechten Maustaste auf das Verzeichnis und wählen Sie im Popup-Menü den Eintrag Freigabe. Klicken Sie auf die Registerkarte Web-Freigabe und achten Sie darauf, nicht versehentlich auf die Registerkarte Freigabe zu gehen. Das neue Fenster Alias bearbeiten erscheint. In diesem Fenster brauchen Sie nichts zu verändern; die Standardwerte führen zu einer ausreichenden IIS-Unterstützung, um die restlichen Übungen nachvollziehen zu können. Beachten Sie, dass das System dieser Web-Freigabe automatisch den Alias tag_19 zuweist. Sie verwenden diesen Alias später als Teil des URL, den Sie in Ihren Browser eingeben, wenn Sie auf Programme zugreifen, die in diesem Web-Freigabe-Verzeichnis auf dem Webserver abgelegt sind. Die Syntax für das Laden eines Programms, beispielsweise einer HTML-Seite oder eines Server-Scripts, die in diesem Web-Freigabe-Verzeichnis abgelegt sind, sieht wie folgt aus:
http://localhost/tag_19/meinedatei.asp
In der nächsten Übung erstellen Sie eine Active Server Page (ASP), die HTML erzeugt, das die über SQL von der zuvor angelegten DSN abgerufenen Daten anzeigt. Mit anderen Worten, nachdem Sie eine Datenbank haben, die über Ihr ODBC API zur Verfügung steht, können Sie ein Verbindungsobjekt anlegen, das Ihnen erlaubt, der Datenbank SQL- Anweisungen zu übergeben, die Ergebnisse an Ihr serverseitiges Script zurückgeben. Durch das Einpacken Ihrer Abfrage in HTML-Anweisungen können Sie die Ergebnisse - beispielsweise die Datensätze aus der Datenbank - in einem Browser anzeigen. Angenommen, Sie wollen das Script verwenden, um die Datenbank abzufragen und alle Felder jedes Datensatzes in einer markierten Listen auszugeben. Ziel dieser Übung ist, Ausgaben zu erzeugen, die etwa wie die in Abbildung 19.6 aussehen.
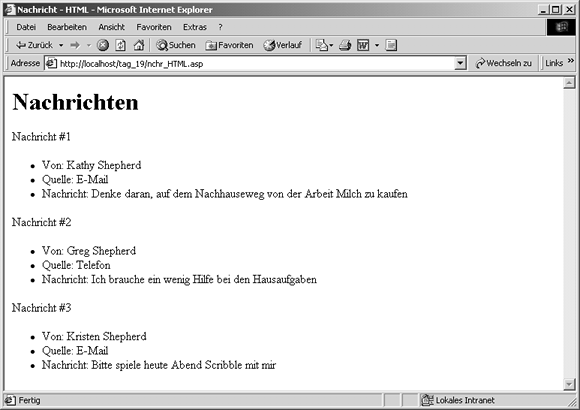
Abbildung 19.6: HTML-Ausgabe, die durch ein serverseitiges Script für den Zugriff auf eine Datenbank erzeugt wird
Jetzt können Sie Ihren bevorzugten Texteditor starten und anfangen, das Script den nachfolgenden Schritten entsprechend zu erstellen. Die Active Server Page enthält VBScript und HTML. VBScript kann vom Webbrowser im IIS Webserver gelesen und interpretiert werden. Zunächst richten Sie mit der Sprachdeklarations-Anweisung die ASP als auf VBScript basierende Seite ein. Dazu verwenden Sie die folgende Syntax:
<%@ Language = "VBScript"%>
Anschließend erzeugen Sie den Anfang der HTML-Seite mit den Standardabschnitten <!DOCTYPE...>, <HTML>, <HEAD> und <BODY>. Diese Abschnitte müssen später alle abgeschlossen werden wie auf einer ganz normalen HTML-Seite. Innerhalb des <BODY>- Abschnitts platzieren Sie die Logik für das Öffnen der ODBC-Verbindung, übergeben der Datenbank die SQL-Anweisungen und formatieren die Antwort innerhalb von HTML- Anweisungen.
Um eine Verbindung mit der Datenbank einzurichten, auf die Sie zuvor mit Ihrer DSN verwiesen haben, legen Sie ein neues Server-Objekt an, das das ADO (ActiveX Data Object) Connection instanziiert, ebenso wie eine open-Methode, der Sie die DSN als Argument übergeben. Die Syntax für diesen Methodenaufruf und die zugeordnete Methode sieht wie folgt aus:
set oMeinObjekt = Server.CreateObject("ADODB.Connection")
oMeinObjekt.open("meineDSN")
Insbesondere werden Sie den folgenden Code verwenden:
set oNchr = Server.CreateObject("ADODB.Connection")
oNchr.open("nachrichtDB")
Das neue Objekt heißt oNchr und die DSN nachrichtDB ist als Argument kodiert, das dem ADO über die open-Methode übergeben wird. Das dient letztlich dazu, eine Verbindung zwischen diesem ASP-Script und Ihrer nachricht.mdb-Datenbank einzurichten. Die Verbindung bleibt geöffnet, bis Sie sie mit der Close-Eigenschaft für das Connection-Objekt schließen, was dann so aussieht:
oNchr.Close
Die Close-Eigenschaft folgt der restlichen Logik, die Sie ausführen, während die ODBC geöffnet ist, wie beispielsweise bei der Ausführung von SQL-Anweisungen oder Formatierungsantworten von der Abfrage. Um SQL auszuführen, wenden Sie die Execute- Methode auf das Connection-Objekt an. Das Ergebnis ist ein RecordSet-Objekt, das von der Execute-Methode zurückgegeben wird. Die Syntax für die Übergabe von SQL über diese Objektaufrufe an eine Datenbank sieht so aus:
Set meineRecordSetVariable = oMeinObjekt.Execute("SQL-Anweisung")
Um alle Datensätze (*) aus der Tabelle nchr in Ihrer Datenbank nachricht.mdb auszuwählen, verwenden Sie die folgende einfache SQL-Anweisung:
SELECT * FROM nchr;
Wenn Sie das resultierende RecordSet als nchrRS bezeichnen, sieht der vollständige Objektaufruf folgendermaßen aus:
Set nchrRS = oNchr.Execute("SELECT * FROM nchr;")
Wenn Sie nur den ersten Datensatz der Datenbank zurückgeben wollen, können Sie alle erforderlichen Felder auf das Standard-Ausgabegerät oder den Bildschirm ausgeben. Weil Sie in diesem Fall jedoch alle Datensätze Ihrer Datenbank ausgeben wollen, brauchen Sie eine Möglichkeit, die Datensätze zu durchlaufen und jeden davon anzuzeigen. Der einfachste Ansatz dafür wäre, eine Schleife zu programmieren, die einen Datensatz liest, die Ausgabe erzeugt und dann mit dem nächsten Datensatz weitermacht. Die do-Schleifen von VBScript sind gut für diesen Zweck geeignet. Sie beginnen Ihre Schleife mit einer Anweisung, die den Interpreter anweist, diese solange auszuführen, bis keine weiteren Datensätze mehr vorliegen, was dadurch gekennzeichnet ist, dass das Script die EOF- Markierung (End of File) erreicht. Innerhalb der Schleife schreiben Sie die relevanten Felder aus allen Datensätzen auf den Bildschirm und gehen dann weiter zum nächsten Datensatz. Die Syntax für diese Schleife sehen Sie hier:
do until meineRecordSetVariable.EOF
Response.Write (meineRecordSetVariable("Feldname"))
...
meineRecordSetVariable.MoveNext
Loop
Die Schleife für unsere Übung sieht so aus:
do until nchrRS.EOF
Response.Write ("<P>Nachricht #" & _
nchrRS("ID") & "<UL>")
Response.Write ( _
"<LI>Von: " & nchrRS("von") & "</LI>" & _
"<LI>Quelle: " & nchrRS("quelle") & "</LI>"& _
"<LI>Nachricht: " & nchrRS("nachricht") & "</LI>" )
Response.Write ("</UL>")
nchrRS.MoveNext
Loop
Nach dieser Schleife schließen Sie die Verbindung mit oNchr.Close, wie bereits beschrieben. Anschließend geben Sie das Objekt frei, indem Sie die Variable oNchr auf Null setzen:
Set oNchr = nothing
Jetzt müssen Sie nur noch die BODY- und HTML-Elemente abschließen. Listing 19.1 zeigt die vollständige Applikation. Speichern Sie Ihr Script unter dem Namen nchr_HTML.asp.
Listing 19.1: Ein ASP-Script zum Extrahieren von Datensätzen aus einer Datenbank - nchr_HTML.asp
1: <%@ LANGUAGE = "VBScript"%>
2: <%' Listing 19.1 - nchr_HTML.asp
3: %>
4:
5: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
6: "http://www.w3.org/TR/html4/loose.dtd">
7: <!-- HTML-Datei, erzeugt von ASP -->
8:
9: <HTML>
10: <HEAD>
11: <TITLE>Nachricht - HTML</TITLE>
12: </HEAD>
13: <BODY>
14: <H1>Nachrichten</H1>
15: <%
16: set oNchr = Server.CreateObject("ADODB.Connection")
17: oNchr.open("nachrichtDB")
18:
19: set nchrRS = oNchr.Execute("SELECT * FROM nchr;")
20:
21: do until nchrRS.EOF
22: Response.Write ("<P>Nachricht #" & _
23: nchrRS("ID") & "<UL>")
24: Response.Write ( _
25: "<LI>Von: " & nchrRS("von") & "</LI>" & _
26: "<LI>Quelle: " & nchrRS("quelle") & "</LI>"& _
27: "<LI>Nachricht: " & nchrRS("nachricht") & "</LI>" )
28: Response.Write ("</UL>")
29: nchrRS.MoveNext
30: Loop
31: oNchr.Close
32: set oNchr = nothing
33: %>
34: </BODY>
35: </HTML>
![]()
Die Zeile 1 richtet die Scripting-Sprache für die Active Server Page als VBScript ein. Die Zeilen 5-6 enthalten die DOCTYPE-Deklaration für die durch das Script zu erstellende HTML-Seite. Die Zeilen 9-14 stellen typische HTML-Tags für die erstellte Seite dar. Die Zeilen 15-33 enthalten das restliche VBScript. Das ADO wird in Zeile 16 erzeugt und mit dem Namen oNchr versehen. Dem Connection-Objekt wird mit der Open-Methode die DSN nachrichtDB zugeordnet (Zeile 17). Zeile 19 übergibt der Datenbank mit der Execute-Methode für das Connection-Objekt die SQL-Abfrage. Die Zeilen 21-30 enthalten die Schleife, die die Abfrage-Ergebnisse auf dem Bildschirm ausgeben. Die Schleife wird ausgeführt, bis das Ende der Datenbankdatei erreicht ist (Zeile 21). Jedes der Felder des ersten gefundenen Datensatzes wird an das Standard-Ausgabegerät (Response.Write) weitergegeben und in die entsprechenden HTML-Tags eingeschlossen (Zeilen 22-28). In der Zeile 29 weist die MoveNext-Eigenschaft für das RecordSet-Objekt den ganzen Prozess an, in der Datenbank eine Zeile weiterzurücken. Zeile 30 weist das Script an, zurück zur do-Anweisung in Zeile 21 zu gehen. Falls der aktuelle Datensatz nicht der letzte Datensatz ist, wird die Schleife weiter ausgeführt, bis dies der Fall ist. Zeile 31 schließt die Verbindung. Zeile 32 setzt die Variable oNchr auf Null. Das Script wird in Zeile 33 abgeschlossen und die restlichen Zeilen schließen geöffnete HTML-Elemente mit schließenden Tags ab.
Um Ihr Server-Script auszuführen und die in Abbildung 19.1 gezeigten Ergebnisse zu erzeugen, gehen Sie mit Ihrem Browser auf die Kopie der ASP auf Ihrem Web-Host. Dazu geben Sie den folgenden URL in das Adressfeld des Microsoft Internet Explorers ein:
http://localhost/tag_19/nchr_HTML.asp
Das vorige Beispiel hat eine HTML-Ausgabe für die Anzeige in einem Browser erstellt. Wenn Sie den Code genauer betrachten, werden Sie sehen, dass es sich bei ihm auch um korrektes XML handelt, allerdings in HTML-Vokabular ausgedrückt. Durch kleine Veränderungen des Scripts können Sie dafür sorgen, dass es XML erzeugt, das aussieht wie das in den letzten Kapiteln erstellte.
Im nächsten Beispiel werden Sie dieselben Objektaufrufe ausführen und dieselbe SQL- Anweisung verwenden, die Ergebnisse aber in XML-Tags und nicht in HTML einschließen. Mit anderen Worten: statt mit den Abschnitten <!DOCTYPE...>, <HTML>, <HEAD> und <BODY> zu beginnen, schreiben Sie eine XML-Deklaration und das benötigte Wurzelelement:
<?xml version="1.0"?>
<notiz>
...VBScript
</notiz>
Der Code in der Schleife unterscheidet sich ebenfalls und reflektiert die statt des HTML verwendeten XML-Tags. Die Schleife könnte wie folgt aussehen:
do until nchrRS.EOF
Response.Write ("<nchr id='" & _
nchrRS("ID") & "'>")
Response.Write ( _
"<von>" & nchrRS("von") & "</von>" & _
"<quelle>" & nchrRS("quelle") & "</quelle>" & _
"<nachricht>" & nchrRS("nachricht") & "</nachricht>" )
Response.Write ("</nchr>")
nchrRS.MoveNext
Loop
Beachten Sie, dass die HTML-Listenelemente jetzt die bereits bekannten XML-Elemente von, quelle und nachricht sind. Beachten Sie auch, dass der Wert aus dem Datenbankfeld id als Attributwert im XML-Ergebnis verwendet wird.
Das Listing 19.2 zeigt das vollständige Programm. Nehmen Sie die erforderlichen Änderungen an Ihrem ersten Script vor und speichern Sie den neuen Code unter dem Namen nchr_XML.asp. Achten Sie dabei darauf, dass Sie den Namen genau wie gezeigt schreiben, weil er in der nächsten Übung von einem anderen Programm aufgerufen wird.
Listing 19.2: Ein ASP-Script, das Datensätze aus einer Datenbank extrahiert und das Ergebnis als korrektes XML zurückgibt - nchr_XML.asp
1: <%@ LANGUAGE = "VBScript"%>
2: <%' Listing 19.2 - nchr_XML.asp
3: %>
4:
5: <%Response.ContentType="text/xml"%>
6: <?xml version="1.0"?>
7: <!-- XML-Datei, erzeugt durch ASP -->
8:
9: <notiz>
10: <%
11: set oNchr = Server.CreateObject("ADODB.Connection")
12: oNchr.open("nachrichtDB")
13:
14: set nchrRS = oNchr.Execute("SELECT * FROM nchr;")
15:
16: do until nchrRS.EOF
17: Response.Write ("<nchr id='" & _
18: nchrRS("ID") & "'>")
19: Response.Write ( _
20: "<von>" & nchrRS("von") & "</von>" & _
21: "<quelle>" & nchrRS("quelle") & "</quelle>" & _
22: "<nachricht>" & nchrRS("nachricht") & "</nachricht>")
23: Response.Write ("</nchr>")
24: nchrRS.MoveNext
25: Loop
26: oNchr.Close
27: set oNchr = nothing
28: %>
29: </notiz>
![]()
Die Zeile 1 richtet die Scripting-Sprache für die Active Server Page als VBScript ein. Die Zeile 6 enthält die XML-Deklaration für das vom Script zu erzeugende Dokument. Zeile 9 enthält das Start-Tag für das Wurzelelement (notiz) der erstellten Seite. Die Zeilen 10-28 enthalten das restliche VBScript. Das ADO wird in Zeile 11 erzeugt und mit dem Namen oNchr versehen. Dem Connection-Objekt wird mit der Open-Methode die DSN nachrichtDB zugeordnet (Zeile 12). Zeile 14 übergibt der Datenbank mit der Execute-Methode für das Connection-Objekt die SQL-Abfrage. Die Zeilen 16-25 enthalten die Schleife, die die Abfrage-Ergebnisse auf dem Bildschirm ausgeben. Die Schleife wird ausgeführt, bis das Ende der Datenbankdatei erreicht ist (Zeile 16). Jedes der Felder des ersten gefundenen Datensatzes wird an das Standard-Ausgabegerät (Response.Write) weitergegeben und in die entsprechenden HTML-Tags eingeschlossen (Zeilen 17-23). In Zeilen 24 weist die MoveNext-Eigenschaft für das RecordSet-Objekt den ganzen Prozess an, in der Datenbank eine Zeile weiterzurücken. Zeile 25 weist das Script an, zurück zur do-Anweisung in Zeile 16 zu gehen. Falls der aktuelle Datensatz nicht der letzte ist, wird die Schleife weiter ausgeführt, bis dies der Fall ist. Zeile 26 schließt die Verbindung. Zeile 27 setzt die Variable oNchr auf Null. Das Script wird in Zeile 28 abgeschlossen und das Wurzelelement (</notiz>) in Zeile 29.
Sie führen das Script aus, indem Sie den folgenden URL in Ihren Browser eingeben:
http://localhost/tag_19/nchr_XML.asp
Die Ausführung dieses Scripts erzeugt die in Abbildung 19.7 gezeigte Ausgabe.
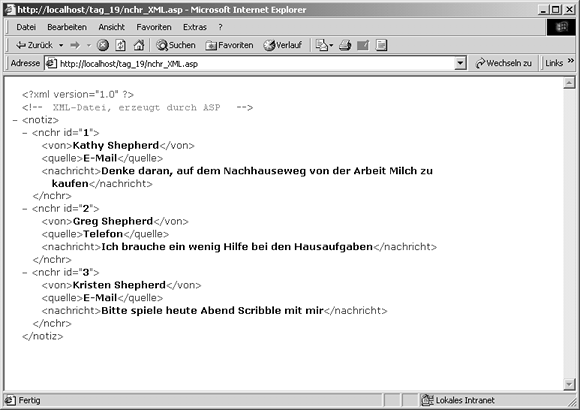
Abbildung 19.7: XML-Ausgabe, erzeugt durch ein serverseitiges Script, das auf eine Datenbank zugreift
Das vorige Beispiel hat eine Ausgabe in XML aus Ihrer Datenbank erzeugt, die jedoch so nicht in einem Browser angezeigt werden kann. Sie können ein Style Sheet erstellen und es ihr zuordnen, um der Ausgabe einen Stil zuzuweisen. Statt dieses Ansatzes werden Sie jedoch eine HTML-Seite erstellen, die eine XML-Dateninsel einrichtet und HTML- Elemente an die entsprechenden XML-Datenelementen bindet. Sie haben diese Technik in Kapitel 17 kennen gelernt. Der Unterschied dabei ist, dass Sie hier nicht auf ein statisches XML-Dokument zugreifen, sondern dass Ihre Dateninsel in der nächsten Übung das Script nchr_XML.asp aufruft, um das zu erzeugen, was man sich am besten als virtuelles XML vorstellt. In diesem Fall sind die XML-Daten transient, befinden sich im Arbeitsspeicher, werden aber niemals permanent auf der Festplatte abgelegt.
Wenn Sie in Kapitel 17 die Datei insel02.html angelegt haben, können Sie diese jetzt bearbeiten. Sie ist der Seite dieser Übung ganz ähnlich. Der wichtigste Unterschied ist, dass die Dateninsel im aktuellen Beispiel Daten aus einem ASP-Programm abruft statt aus einem statischen XML-Dokument. In der aktuellen Übung sieht das HTML-Tag <XML> also folgendermaßen aus:
<XML src="nchr_XML.asp" id="meineNchr"></XML>
Beachten Sie, dass die Quelle für die Dateninsel die ASP ist. Deshalb können Sie diese Seite nur dann ausführen, wenn Sie sie über den IIS Webserver übergeben. Mit anderen Worten, Sie können diese Seite nicht wie eine herkömmliche HTML-Seite im Browser anzeigen. Der Webserver muss sie zuvor verarbeiten, um sicherzustellen, dass der ASP- Code ausgeführt wird.
Die restliche Seite enthält Standard-HTML-Markup sowie die Daten, um die Tabelle mit den gebundenen Elementen zu erstellen. Der Tabellencode für die HTML-Seite sieht wie folgt aus:
<TABLE id="Tabelle" border="6" width="100%"
datasrc="#meineNchr" summary="Nachrichten">
<THEAD style="background-color: aqua">
<TH>Von</TH>
<TH>Quelle</TH>
<TH>Nachricht</TH>
</THEAD>
<TR valign="top" align="center">
<TD><SPAN DATAFLD="von"></SPAN></TD>
<TD><SPAN DATAFLD="quelle"></SPAN></TD>
<TD><SPAN DATAFLD="nachricht"></SPAN></TD>
</TR>
</TABLE>
Der Wert des Datenquellen-Attributs für das TABLE-Tag entspricht dem id-Attribut, das in der Dateninsel bereitgestellt wird (<XML src="nchr_XML.asp" id="meineNchr></XML>). Jede der <TD>-Zellen enthält ein SPAN-Element, das zu einem der Elemente von, quelle oder nachricht im XML-Instanzdokument gebunden wird. Listing 19.3 zeigt das vollständige Programm.
Listing 19.3: Eine ASP-Dateninsel, die transiente XML-Daten aus einer Datenbank verwendet - ASP_insel.html
1: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
2: "http://www.w3.org/TR/html4/loose.dtd">
3: <!-- Listing 19.3 - ASP_insel.html -->
4:
5: <HTML>
6: <HEAD>
7: <TITLE>XML-Datenbindung</TITLE>
8: </HEAD>
9: <BODY>
10: <H1>Nachrichten</H1>
11: <XML SRC="nchr_XML.asp" ID="meineNchr"></XML>
12: <TABLE id="Tabelle" border="6" width="100%"
13: datasrc="#meineNchr" summary="Nachrichten">
14: <THEAD style="background-color: aqua">
15: <TH>Von</TH>
16: <TH>Quelle</TH>
17: <TH>Nachricht</TH>
18: </THEAD>
19: <TR valign="top" align="center">
20: <TD><SPAN DATAFLD="von"></SPAN></TD>
21: <TD><SPAN DATAFLD="quelle"></SPAN></TD>
22: <TD><SPAN DATAFLD="nachricht"></SPAN></TD>
23: </TR>
24: </TABLE>
25: </BODY>
26: </HTML>
![]()
Die Zeile 11 richtet die Dateninsel ein. Sie wird mithilfe des HTML-Elements XML aus nchr_XML.asp abgerufen. Das Attribut id="meineNchr" stellt eine Referenz (meineNchr) bereit, die in Zeile 13 verwendet wird, um auf die Datenquelle für die Tabelle zu verweisen. Das XML-Dokument, das dazu gebunden wird, wird durch den Wert des Attributs src angegeben. Das Start-Tag für die Tabelle (Zeilen 12-13) enthält das Attribut datasrc, das die benannte Referenz (#meineNchr) der Dateninsel angibt. Ein Tabellen-Head-Bereich wird eingeführt (Zeilen 14-18), der eine Überschriftzeile zur Beschriftung der Tabellenspalten bereitstellt. Die TR ist in den Zeilen 19-23 geschrieben.
Sie führen diese Seite aus, indem Sie den folgenden URL in das Adressfeld Ihres Browsers eingeben:
http://localhost/tag_19/ASP_insel.html
Sie sehen das in Abbildung 19.8 gezeigte Ergebnis.
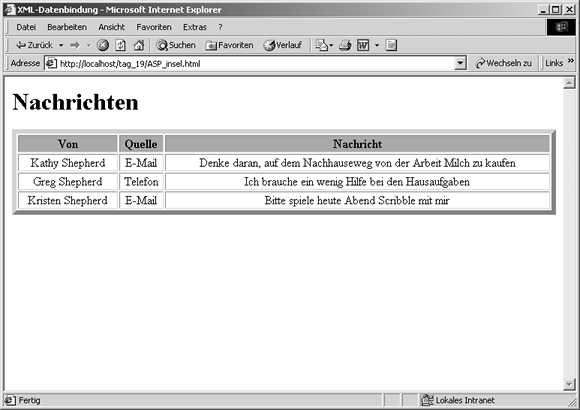
Abbildung 19.8: Eine Downstream-Web-Applikation, die auf ein Mittelschicht-Script zugreift
Heute haben Sie erfahren, wie Sie XML mithilfe von Enterprise-Applikationen in Geschäftsmodelle integrieren können. Die meisten der hier gezeigten Modelle basieren irgendwie auf Datenbanken. Die Drei-Schichten-Architektur des Webs stellt Datenbanken auf der Datenschicht bereit. Mittelschicht-Scripts können genutzt werden, um auf die in Datenbanken gespeicherten Daten zuzugreifen, sie zu verarbeiten, zu manipulieren und sie zum Client zu transportieren. Downstream-Prozesse können auf Mittelschicht- Applikationen zugreifen, um Daten zu extrahieren. Sie haben verschiedene Technologien kennen gelernt, um Daten und Applikationen zu integrieren, und im Kern dieser Technologien stand immer XML, das die Möglichkeit des Datenaustausches bietet.
Frage:
Was ist eine Dokumentanalyse?
Antwort:
Die Dokumentanalyse beinhaltet das Auswerten der Komponenten, Aufgaben und
Anforderungen für eine oder mehrere Dokumentklassen, um eine detaillierte und
definitive Beschreibung für alle darin einzuordnenden Dokumente zu bieten.
Frage:
Was ist die Drei-Schichten-Web-Architektur?
Antwort:
Es handelt sich dabei um eine spezielle Client-/Server-Architektur, die aus drei
wohl definierten und separaten Prozessen besteht, die jeweils auf
unterschiedlichen Plattformen ausgeführt werden. Die Client-Schicht, die aus
Browsern oder anderen Clients besteht, greift über einen Webserver auf der
Mittelschicht auf Applikationen zu. Daten werden auf der Datenschicht
gespeichert, normalerweise in Datenbanken, Dateisystemen oder anderen
formalen Strukturen.
