XSLT (XSL Transformation Language) wandelt einen XML-Dokumentbaum in eine neue Baumstruktur um. Bei dem neuen Baum kann es sich ebenfalls um ein XML-Dokument handeln, aber auch um HTML oder ein anderes Format. XSLT ist eine deklarative, ereignisgesteuerte, auf Regeln basierte Programmiersprache, die als Dialekt von XML angelegt ist. Heute lernen Sie die folgenden Dinge kennen:
Wie Sie in Kapitel 15 erfahren haben, beinhaltet XSL (Extensible Stylesheet Language) eine Transformationssprache (XSLT) und eine Formatierungssprache (XSL-FO). Eine dritte Komponente des ursprünglichen XSL-Vorschlags, XPath, wurde zu einer separaten Spezifikation gemacht, weil man ihren Nutzen für andere XML-Technologien erkannt hatte. Wie XSL-FO ist auch XSLT eine Applikation von XML, sodass Sie es auch ganz einfach mit einem simplen Texteditor erzeugen können. Im letzten Kapitel haben Sie gelesen, dass XSLT unabhängig vom restlichen XSL angewendet werden kann. Sie nutzen diese Möglichkeit heute, indem Sie XML-Dokumente in korrekte HTML-Seiten umwandeln, ohne dass dazu XSL Formatting Objects verwendet werden.
Obwohl Sie XSLT verwenden, um XML in HTML umzuwandeln, hat XSLT einen viel breiteren Einsatzbereich. XSLT kann genutzt werden, um XML in andere Text- und Markup-Formate umzuwandeln und sogar in andere XML-Instanzen. Die Umwandlung von XML in XML wird häufig verwendet, um XML-Dokumente für spezielle Applikationen umzuwandeln. Beispielsweise können Unternehmen, die miteinander kommunizieren, XSLT verwenden, um das von Geschäftspartnern angebotene XML umzuwandeln, um die Kommunikation und die Kompatibilität zu verbessern. Stellen Sie sich beispielsweise einen Kaufauftrag vor, der als XML-Dokument-Instanz erzeugt wurde, die in ein XML-Dokument umgewandelt wird, das eine andere Struktur für die Eingabe in ein Auftragssystem verwendet. XSLT stellt eine einfache und zuverlässige Methode für solche Transformationen bereit.
Obwohl sich XSL zum Zeitpunkt der Drucklegung dieses Buches in der W3C Kandidatenempfehlungs-Phase befindet, ist XSL Transformations Version 1.0 bereits eine formale Empfehlung. Sie finden die Spezifikation unter http://www.w3.org/TR/xslt. Die Tatsache, dass sich XSLT sehr viel schneller zu einer gewissen Reife entwickelt hat als seine Obermenge XSL, hat dafür gesorgt, dass die Möglichkeit, XSLT unabhängig vom restlichen XSL einzusetzen, viel besser unterstützt wird. Obwohl Sie XSLT separat verwenden können, wie Sie es auch in diesem Kapitel tun werden, soll XSLT gemäß dem W3C hauptsächlich für Umwandlungen verwendet werden, die Teil einer allgemeinen Stilzuordnung für XML-Daten sind.
Die Verwendung einer Transformations-Programmiersprache ist im Umfeld der Webentwicklung sehr interessant. In gewisser Weise folgt das Konzept einer ungeschriebenen Programmierregel, dass Sie das Werkzeug verwenden sollen, das für die Aufgabenstellung am besten geeignet ist. Kennen Sie jemanden, der von einer einzigen Applikation so überzeugt ist, dass er alle Programmieraufgaben ausschließlich damit erledigt? Wenn Sie täglich eine Tabellenkalkulation anwendeten, würden Sie die erste Spalte auf 80 Zeichen erweitern und am Ende jeder Zeile die Eingabetaste drücken, um eine eigene Textverarbeitung daraus zu machen?
Durch die Verwendung von XML für ein intelligentes, datenabhängiges Speichern und effiziente, interoperable Informationsübertragung nutzen Sie einige der wichtigsten Stärken von XML. Durch die Umwandlung von XML in HTML beispielsweise können Sie Daten in einem Format präsentieren, das in fast jedem modernen Browser verarbeitet werden kann. Wie Sie wissen, ist die Darstellung von reinem XML in den meisten Browsern noch nicht vollständig implementiert, aber HTML funktioniert ausgezeichnet.
Die Transformationen können auch in Applikationen eingebaut werden, sodass sie Teil der normalen Verarbeitung werden. Beobachten Sie, wie der Internet Explorer das Ergebnis auf die Darstellung vorbereitet, wenn Sie eine XML-Seite in den Browser laden. Wie Sie in Kapitel 2 erfahren haben, zeigt der IE eigentlich nicht das XML an; statt dessen nimmt er mithilfe eines Stylesheets, das in der IE-Distribution enthalten ist, eine XSL-Transformation vor. Wenn Sie den IE installieren, installieren Sie auch verschiedene Begleitprodukte wie beispielsweise den MSXML-Parser und die entsprechenden Bibliotheken. In diesem Paket ist auch ein spezielles Stylesheet enthalten. Wenn Sie eine XML-Datei in den IE laden, prüft er zunächst, ob Sie ihr ein Stylesheet zugewiesen haben, das für die Darstellung verwendet werden kann. Ist dies nicht der Fall, verwendet der IE sein eigenes Standard-Stylesheet - dasjenige, das Ihnen farbige Tags und einen erweiterbaren/zusammenklappbaren Baum für Markup und Inhalt zur Verfügung stellt. Wenn Sie das Standard-Stylesheet ansehen wollen, starten Sie IE Version 5 oder höher und gehen zu dem nachfolgenden internen URI, indem Sie ihn direkt in das Adressfeld eingeben:
res://msxml.dll/defaultss.xsl
Sie erhalten die vertraute Baumansicht eines relativ komplexen XSL-Stylesheets, das im Rahmen dieses Kapitels nicht analysiert werden kann. Am Ende dieses Kapitels werden Sie jedoch das Stylesheet ansehen und die wichtigsten Regeln und Komponenten darin erkennen können.
Die Transformation findet statt, wenn eine XSL-Transformations-Engine ein XML- Dokument und ein XSL-Stylesheet verarbeitet. Mithilfe der Sprache XSLT stellen Sie XSL-Stylesheets zusammen, bei denen es sich ebenfalls um XML-Dokumente handelt. Ein XSL-Stylesheet enthält Anweisungen für die Umwandlung der XML-Quelldokumente von einem Dokumententyp in einen anderen, beispielsweise XML oder HTML. In Hinblick auf die Struktur betrachtet, spezifiziert ein XSL-Stylesheet die Transformation eines Knotenbaums in einen anderen. Es gibt zahlreiche Transformations-Engines und Editoren mit integrierter XSLT-Unterstützung.
XSLT kann in unterschiedlichsten Varianten auftreten und Sie sollten die Werkzeuge auswählen, die für Ihre Bedürfnisse am besten geeignet sind. Beispielsweise können Sie lokale Transformationen unter Verwendung einer Engine auf Ihrem Computer ausführen. Bei diesem Szenario werden Sie eine Engine aufrufen und den Namen eines XML- Dokuments sowie das zugehörige XSL-Dokument übergeben. Die Engine wird die Transformation verarbeiten und ein drittes Dokument als Ausgabe erzeugen. Engines dieser Art gibt es heute bereits auf fast jeder Plattform und viele beinhalten Open Source- Code, der in andere Applikationsprogramme integriert werden kann. Wie Sie sich sicher vorstellen können, sind durch die Integration der Leistung einer Transformations-Engine in Ihren Code komplexe Lösungen zu finden, die XML-Daten mit anderen Geschäftsprozessen umfassen. Eine vollständige Liste aller verfügbaren XSLT-Engines, XSLT-Editoren und -Utilities finden Sie unter http://www.xslt.com/ sxlt_tools_editors.html. Die W3C XSLT-Site (http://www.w3.org/Style/XSL/) enthält auch eine Liste aller XSLT-Werkzeuge.
Heute werden Sie von http://jclark.com/xml/xt.html einen Java XSLT-Prozessor (XT) herunterladen, um einige der Transformationsübungen nachvollziehen zu können. Dieser XSLT-Prozessor arbeitet in Kombination mit einem SAX-Parser. Sie haben bereits in Kapitel 13 einen SAX-Parser installiert, den XT verwenden kann.
Der Microsoft Internet Explorer unterstützt clientseitige Transformationen von XML unter Verwendung von XSL-Stylesheets. Das ist wirklich nur in Umgebungen praktisch, wo Sie eine vollständige Kontrolle über den Browser-Einsatz haben. Netscape-Browser beispielsweise unterstützen keine clientseitigen Transformationen; Sie müssen also garantieren, dass alle Ihre Benutzer eine kompatible Version von IE verwenden, um diesen Transformationsstil sinnvoll zu machen. Nichtsdestotrotz stellen die clientseitigen Transformationen eine einfache Methode dar, Ihre Programmierung schnell zu überprüfen und Ergebnisse anzuzeigen. Sie haben heute die Gelegenheit, IE zu verwenden, um clientseitiges XSLT auszuführen.
Einige Texteditoren bieten eine integrierte XSLT-Unterstützung, die eine Arbeitsumgebung für die Stylesheet-Entwicklung anbietet. Sie können sich heute einen kostenlosen Editor herunterladen, um diesen Ansatz auszuprobieren (Quelle: http:// www.architag. com/xray).
Sie können auch mit serverseitigem Scripting einen Prozessor aufrufen, um XML in HTML umzuwandeln, bevor Sie es an Ihren Webserver senden. Das ist eine interessante Technik, die in vielen vom Web abhängigen Applikationen praktisch sein kann.
Im letzten Kapitel haben Sie ein Beispiel kennen gelernt, bei dem ein XML-Dokument mit Unternehmensstrategien in XSL Formatting Objects umgewandelt wurde, um es in einem Interpreter anzeigen und eine PDF-Version des Strategiehandbuchs erstellen zu können. Durch eine leichte Abänderung des Szenarios, wobei die Formatting Objects und die Notwendigkeit einer PDF-Ausgabe ausgeschlossen werden, erhalten wir eine Situation, in der dieselbe XML-Quelle in HTML umgewandelt wird, um sie in einem Unternehmens-Intranet anzuzeigen. Man braucht immer noch mehrere verschiedene Prozesse und Vokabulare, um ein XML-Dokument so umzuwandeln, dass dem Inhalt ein bestimmter Stil zugewiesen wird. Die einzelnen Komponenten bei der XSL- Transformation von XML in HTML sehen wie folgt aus:
Bei diesem Unternehmensstrategie-Szenario haben Sie immer noch ein XML-Dokument in Ihrem Unternehmens-Intranet, das die administrativen Strategien für Ihr Unternehmen enthält. Wie zuvor handelt es sich dabei um ein Dokument, das regelmäßig aktualisiert wird, um Änderungen in Hinblick auf Arbeitgeberzulagen, Abrechnungspraktiken und andere Strategien zu reflektieren. Statt jedoch ein PDF-Dokument zu erzeugen, wollen Sie das Dokument in bestimmten Zeitabständen verarbeiten, um eine HTML-Webseite zu erzeugen, auf die die Angestellten jederzeit zugreifen können. Wenn Sie diese Transformation zu einem regelmäßigen Prozess machen, stellen Sie sicher, dass der Webinhalt aktuell bleibt.
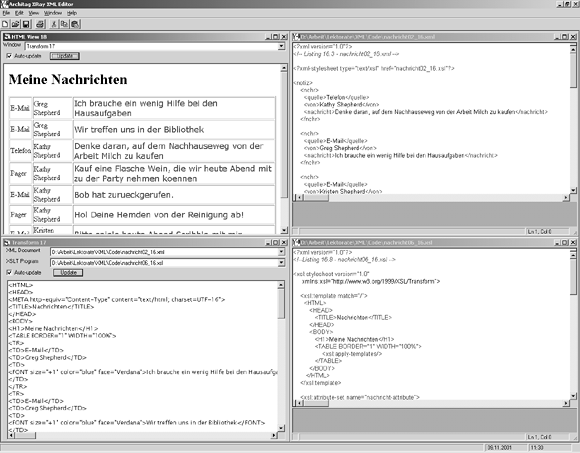
XSLT eignet sich bestens für dieses Szenario. Auch hier wird einem XML-Instanzdokument (corp.xml), das die Unternehmensstrategien und Richtlinien in geeigneten Elementen enthält, ein Stylesheet (corp.xsl) zugeordnet. Dieses Stylesheet identifiziert Vergleichsregeln und Aktionen, die den XSLT-Prozessor anweisen, XML-Elemente durch HTML-Tags für die Textgröße von Überschriften, hervorgehobene Abschnitte, Seitenränder usw. zu ersetzen. Eine XSLT-Engine verarbeitet die beiden XML-Dokumente (corp.xml und corp.xsl) als kombinierte Quellbäume in einer Transformation, die ein HTML- Ausgabebaumdokument (corp.html) erzeugt. Die gesamte Operation umfasst weniger Schritte als die für das Erstellen einer PDF-Datei mit Formatting Objects. In diesem Fall erzeugt die Transformations-Engine einen HTML-Ergebnisbaum statt eines FO-Ergebnisbaums. Nachdem der HTML-Ergebnisbaum erzeugt wurde, ist der Prozess abgeschlossen. Die neue HTML-Seite enthält den gewünschten Inhalt aus dem Unternehmensstrategiedokument (corp.xml). Dieses Szenario ist in Abbildung 16.1 gezeigt.
Abbildung 16.1: XSL-Transformationsprozess
Heute werden Sie Stylesheets anlegen und den XSLT-Prozess unabhängig von der XSL- FO-Komponente von XSL ausführen. Die von Ihnen erzeugten XSL-Stylesheets werden verwendet, um XML-Dokument-Instanzen in wohl geformte HTML-Instanzen für die Darstellung in einem Browser umzuwandeln. Wie bereits erwähnt, haben Sie die Gelegenheit, mehrere Engines auszuprobieren.
Heute werden Sie mehrere Werkzeuge herunterladen und installieren. Das erste ist der Java XT-Prozessor. Es gibt mehrere gute Alternativen:
Der Prozessor, den Sie heute verwenden, XT, ist ein kostenloser XSLT-Prozessor, den James Clark, einer der Autoren der XSLT-Spezifikation in Java geschrieben hat. Laden Sie unter http://jclark.com/xml/xt.html die XT-Distributionsdateien herunter. Befolgen Sie die Anleitungen dazu sorgfältig, weil Sie wie bei allen Java-Programmen für die Umgebungsvariablen verantwortlich sind, beispielsweise CLASSPATH und HOMEPATH, und stellen Sie sicher, dass Sie Variablen mit geeigneten Pfaden eingerichtet haben, sodass die Applikationen korrekt arbeiten können. Mit anderen Worten, weil XT Zugriff auf Ihren SAX-Parser benötigt, muss die Umgebungsvariable CLASSPATH auf Ihrem System den Pfad zum Browser enthalten. Die Dokumentation zum Setup dieser Distribution zeigt die für Ihr Betriebssystem erforderlichen Schritte auf, deshalb werden diese speziellen Anweisungen hier nicht detailliert beschrieben.
Wenn Sie auf einem Computer unter einem Windows-Betriebssystem arbeiten, können Sie XT alternativ auch als ausführbare Win32-Applikation herunterladen. Diese Version ist am einfachsten zu installieren. Sie beinhaltet den XP SAX-Parser, ebenfalls von James Clark, als Teil des Bundles. Sie brauchen eine Microsoft Java-VM (Virtuelle Maschine), weil der XT-Prozessor darauf ausgelegt wurde, bei der Ausführung unter einem Windows- Betriebssystem die Vorteile dieser VM zu nutzen. Eine Kopie der VM finden Sie gegebenenfalls unter http://www.microsoft.com/java/vm/dl_vm40.htm. Wenn Sie jedoch den Internet Explorer in Version 4.01 oder höher bereits auf Ihrem Computer installiert haben, brauchen Sie keine neue Version der VM zu installieren; bei der Installation des IE wurde bereits eine geeignete Version auf Ihrer Maschine eingerichtet. Das bedeutet, wenn Sie ein Windows-Betriebssystem verwenden und den IE auf Ihrem Computer installiert haben, laden Sie XT einfach als ausführbare Win32-Applikation herunter und installieren sie. Benutzer anderer Betriebssysteme -beispielsweise Unix, Linux oder Macintosh - müssen eine vollständige Implementierung von XT vornehmen und sollten dazu die Installationsanweisungen sorgfältig lesen.
Nachdem Sie XT installiert haben, können Sie ihn nutzen, um XSL-Transformationen auszuführen. Die Befehlszeilensyntax, die Sie für den Aufruf des Prozessors heute verwenden, sieht folgendermaßen aus:
java -Dcom.jclark.xsl.sax.parser=Ihr_SAX_Treiber
com.jclark.xsl.sax.Driver quelle.xml stylesheet.xsl ergebnis.html
Ersetzen Sie quelle.xml durch den Pfad und den Namen Ihres Quell-XML-Dokuments. Ersetzen Sie stylesheet.xsl im Befehlszeilenstring durch den vollständig qualifizierten Namen Ihres XSL-Stylesheets und ergebnis.html durch den Namen der Ausgabedatei, die Sie erzeugen wollen. Die meisten der Ausgabedateien, die Sie heute anlegen, enden mit der Dateinamenerweiterung .htm, weil Sie normalerweise XML-Dokumente in HTML umwandeln. XT kann aber auch mit einem Stylesheet verwendet werden, das gegebenenfalls eine andere XML-Struktur zurückgibt.
Wenn Sie die ausführbare Win32-Applikation installiert haben, können Sie für den Aufruf von XT eine abgekürzte Befehlszeilenanweisung verwenden:
xt quelle.xml stylesheet.xsl ergebnis.html
Setzen Sie auch hier die oben beschriebenen Werte für die Platzhalter ein.
Es gibt mehrere XML-Editoren, die mit XSLT-Stylesheets zurechtkommen. Einige davon sind in der Lage, die Transformationen unter Verwendung einer eingebauten oder lokal referenzierten Transformations-Engine vorzunehmen und die umgewandelten Ergebnisse in eingebauten HTML-Viewern anzuzeigen. Bei diesen Editoren handelt es sich unter anderem um:
Der Editor, den Sie für die heutige Übung verwenden, ist der XML-Editor XRay. Sie können Ihn kostenlos unter http://www.architag.com/xray herunterladen. Dieser Editor bietet vollständige Unterstützung für korrekt formatiertes XML und eine XML-Auswertung anhand von DTDs, XDR und XSD-Schemata. Heute werden Sie jedoch seine XSLT- Fähigkeiten nutzen. Sie können ein XML-Dokument in einem Fenster und ein XSL- Stylesheet in einem anderen anlegen. Anschließend führen Sie die Transformation in einem dritten Fenster aus und zeigen die HTML- oder XML-Ausgabe in einem vierten Fenster an.
Laden Sie XRay jetzt herunter und richten Sie es ein; übernehmen Sie bei der Installation die Standardwerte. Sie werden XRay später verwenden, um XSLT-Stylesheets zu erstellen und zu testen.
Nachdem der XSLT-Prozessor aufgerufen wurde, liest er den Quell-XML-Dokumentbaum und den XSL-Dokumentbaum. Das Stylesheet enthält Regelmengen für die Umwandlung der Originalbaumstruktur in einen neuen Ergebnisbaum. Die Regeln werden in Schablonen ausgedrückt, die für die Elemente im Original-XML-Dokument ausgefüllt werden. Jede Schablone enthält XPath-Vergleichsausdrücke, sodass der XSLT-Prozessor den Ziel-Knoten im Quelldokument finden kann. Wird eine Übereinstimmung gefunden, werden die Regeln aus der Schablone auf den Inhalt des übereinstimmenden Elements angewendet. Dieser Prozess wird fortgesetzt, bis alle Schablonen und alle Übereinstimmungen erfolgreich verarbeitet wurden. XSLT ist ein ereignisgesteuerter Prozess, der auf der SAX-Parsing-Technologie basiert. Die von Ihnen konstruierten Regeln informieren den Prozessor darüber, wie er vorgehen soll, z.B.:
Weil es sich bei einem XSLT-Dokument um XML handelt, setzt es sich aus Elementen und Attributen zusammen. Die Elemente in XSLT entsprechen dem XSLT-Namensraum:
http://www.w3.org/1999/XSL/Transform
Wie Sie aus Kapitel 8 wissen, handelt es sich bei einem Namensraum nur um eine Beschriftung, allerdings eine spezielle Beschriftung, weil sie einem XML-Prozessor bekannt ist. Der Prozessor ordnet die Programmiererwartungen dem übergebenen Namensraum zu. Auf diese Weise wird das Programmverhalten mit den Elementen der kodierten Elementmenge verknüpft. Das bedeutet, ein XSLT-Prozessor führt beispielsweise spezielle Anweisungen auf Grundlage der angetroffenen Elemente aus. Jedes Element in einem XSLT-Stylesheet entspricht einer dem Prozessor übergebenen Ereignisanweisung, die wiederum ein Ereignis auslöst, das eine vorgesehene Funktion ausführt. Leider implementieren nicht alle Prozessoren dieselbe Menge an Ereignissen und Funktionen. Die W3C-Spezifikation bietet eine Möglichkeit, die Prozessfolge zu verschmelzen, aber es liegen Differenzen vor. Manchmal werden andere Namensräume verwendet, um alternative Elementmengen zu definieren. Damit geraten Sie in ein Dilemma, wenn es zur Kodierung von XSLT kommt. Der W3C-Namensraum kann für einige Prozessoren genutzt werden, aber nicht für alle. Wenn Sie beispielsweise vorhaben, clientseitige Transformationen im Internet Explorer auszuführen, müssen Sie einen anderen Namensraum in Ihrem XSLT-Programm verwenden:
http://www.w3.org/TR/WD-xsl
Glücklicherweise müssen Sie für die meisten Transformationen, mit denen Sie es heute zu tun bekommen, nur den Namensraum ändern, um eine clientseitige Transformation auszuwählen oder eine Transformation, die eine andere Engine verwendet.
Wie bereits erwähnt, beschreibt der von XSLT ausgedrückte Prozess Regeln für die Umwandlung eines Quellbaums in einen Ergebnisbaum. Jede Schablonenregel ist ein eigenständiges Objekt, das untätig bleibt, bis eine Übereinstimmung die darin enthaltenen Regeln aktiviert. Weil die XSLT-Engine den Quellbaum in einzelnen Knoten verarbeitet, führt er die Regeln aus, wenn Elemente oder andere Konstrukte entsprechend übereinstimmen. Tritt eine Übereinstimmung auf, werden die in den Regeln enthaltenen Anweisungen ausgeführt.
Man könnte sich die Leistung jeder Schablonenregel analog zur Ausführung einer Sub- Routine in einer anderen Sprache vorstellen. Die Sub-Routinen sind in einer Auflistung gespeichert, dem XSL-Dokument, und stehen nach Bedarf zum Aufruf zur Verfügung. Die Reihenfolge der Regeln im XSL-Dokument spielt keine Rolle. Jede Regel wird dann aufgerufen, wenn sie benötigt wird - abhängig von einem übereinstimmenden XPath- Ausdruck. Mit anderen Worten, der XSLT-Prozessor liest das XML-Quelldokument und übergibt den Elementinhalt an geeignete Sub-Routinen, wenn eine Übereinstimmung festgestellt wird. Der Inhalt des übereinstimmenden Elements wird der XSLT-Sub-Routine oder der Schablonenregel übergeben und von ihr verarbeitet. In den Übungen, die Sie heute nachvollziehen werden, führt diese Verarbeitung normalerweise dazu, dass HTML- Elemente im Ergebnisbaum platziert werden.
Die Instanzierung der Schablone für ein übereinstimmendes Quellelement führt also dazu, dass ein Teil des Ergebnisbaums erstellt wird. Die Schablone kann auch spezielle Anweisungen enthalten, die dem Prozessor mitteilen, wie er mit dem Inhalt der übereinstimmenden Elemente umgehen soll.
Die Sub-Routine führt mehrere Standard-Routinen aus. Angenommen, Sie wollen HTML-Markup um den Inhalt eines bestimmten Elements herum erstellen, sodass er als Teil einer markierten Liste auf einer Webseite angezeigt wird. Dieser Prozess kann von einer XSLT-Schablone problemlos ausgeführt werden. Eine Übereinstimmung mit diesem Element wird die Anweisungen ausführen, die benötigt werden, um ein entsprechendes Start-Tag im Ergebnisbaum zu platzieren. An dieser Stelle stellt die Sub-Routine normalerweise mögliche Ausgänge zur Verfügung. Diese Ausgänge werden als XSL- Elemente implementiert. Die Elemente stellen Funktionen für die XSLT-Sprache bereit. Heute werden Sie vor allem einen der beiden folgenden Schablonenausgänge verwenden oder XSLT-Funktionen, die das Verlassen der Schablone ermöglichen:
Neben den bereits beschriebenen stehen auch noch weitere Funktionen in XSLT zur Verfügung. Tabelle 16.1 bietet einen Überblick über die XSLT-Funktionen.
Die Vorgehensweise dabei ist, irgend etwas zu vergleichen und dann wiederholt auszuführen, bis der gesamte Quellbaum umgewandelt ist. Was die Schablone macht, ist nicht auf das Erstellen einer Elementstruktur begrenzt, wie beispielsweise das Anlegen von HTML-Tags. Die Schablone kann Berechnungen vornehmen und abhängig von diesen Berechnungen Ergebnisse erzeugen. Sie kann auch statischen Inhalt erzeugen, der im Ergebnisbaum platziert werden kann. Was die Schablone genau macht, bleibt Ihnen überlassen. Unabhängig von den Aktionen der Schablone haben Sie zwei Ausgänge oder die zuvor beschriebenen Funktionen. Natürlich stehen auch andere Funktionen zur Verfügung, aber heute konzentrieren wir uns auf die Elemente xsl:apply-templates und xsl:value-of.
Die Sprache XSLT besteht aus Elementen und Attributen wie jedes andere XML- Dokument. Die Besonderheit von XSLT sind die Funktionen, die verschiedenen Elementen zugeordnet sind. Die xsl:apply-templates- und xsl:valalue-of-Elemente sind nur zwei der Elemente des XSLT-Dialekts. Tabelle 16.1 zeigt einen Überblick über alle XSLT-Elemente und die dafür vorgesehene Funktion (oder die Ausgänge) an.
Am einfachsten versteht man die Schablonenregeln, indem man selbst welche erstellt und ausprobiert. In dieser ersten Übung werden Sie auf ein einfaches XML-Dokument eine XSL-Transformation anwenden, um einen HTML-Ergebnisbaum zu erzeugen, der in einem Browser angezeigt werden kann. Das XML-Dokument folgt der zuvor eingerichteten Metapher des Nachrichten- und Erinnerungssystems. Nachdem Sie das XML-Dokument angelegt haben, legen Sie ein XSLT-Dokument an.
Um die beiden zu verknüpfen, verwenden Sie ein Stylesheet-Element für eine Verarbeitungsanweisung (PI, Processing Instruction) im XML-Quelldokument. Dieses Element hat zwei Attribute: type und href. Das Attribut type kann zwei mögliche Werte annehmen: text/xsl, der eine Verknüpfung zu einem XSL-Stylesheet darstellt, oder text/ css, wenn ein CSS verwendet wird. Das Attribut href stellt einen URI für das zugeordnete XSL-Dokument dar. Die Syntax für diese PI lautet wie folgt:
<?xml-stylesheet type="text/xsl" href="meinStylesheet.xsl"?>
Diese PI wird nicht von allen XSLT-Prozessoren verwendet, die Sie für Ihre Transformationen einsetzen können. Einen Hinweis zu dieser PI finden Sie unter http:// www.w3.org/TR/xml-stylesheet/ auf der W3C-Website. Manchmal sieht man das Element auch als xml:stylesheet (mit einem Doppelpunkt) statt als xml-stylesheet (mit einem Bindestrich). Wenn ein Parser, der in der Lage ist, einer XML-Instanz ein Stylesheet direkt zuzuordnen, auf diese Verarbeitungsanweisung trifft, nimmt er die entsprechende Zuordnung vor. Diese Zuordnung funktioniert im Microsoft Internet Explorer und in Netscape 6.0. Das W3C hat das Konzept der Stylesheet-Verknüpfung unterstützt, um die Hersteller der bedeutenden Browser zu veranlassen, es in ihren nächsten Releases zu berücksichtigen.
Listing 16.1 zeigt das vollständige XML-Dokument. Erstellen Sie dieses Dokument in einem Texteditor und speichern Sie es als nachricht01_16.xml.
Listing 16.1: Ein XML-Quelldokument - nachricht01_16.xml
1: <?xml version="1.0"?>
2: <!-- Listing 16.1 - nachricht01_16.xml -->
3:
4: <?xml-stylesheet type="text/xsl" href="nachricht01_16.xsl"?>
5:
6: <notiz>
7: <head>Meine Nachrichten</head>
8:
9: </notiz>
![]()
Die Verarbeitungsanweisung befindet sich in Zeile 4. Sie ordnet nachricht01_16.xsl, ein XSL-Stylesheet, zu. Das Wurzelelement notiz (Zeilen 6-9) enthält ein untergeordnetes head-Element (Zeile 7) mit Textinhalt.
Die Transformation in dieser ersten Übung platziert einfach den Inhalt des head-Elements (Meine Nachrichten) in den BODY-Abschnitt der resultierenden HTML-Seite. Das Wurzelelement eines XSL-Dokuments ist das xsl:stylesheet-Element, in dem das xsl- Präfix die XSL-Elemente zum Namensraum http://www.w3.org/1999/XSL/Transform bindet oder abhängig von dem verwendeten Prozessor auch zu einem anderen Namensraum. Das xsl:stylesheet-Element enthält das Namensraum-Attribut sowie ein version-Attribut. XSLT liegt bisher nur in einer einzigen Version vor: version="1.0". Das ganze xsl: stylesheet-Element sieht wie folgt aus:
<xsl:stylesheet version = "1.0"
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
In dieser ersten Übung brauchen Sie nur eine Schablonenregel. Sie schreiben eine Schablonenregel, die mit dem notiz-Element vergleicht und seinen Inhalt verarbeitet. Der Inhalt des notiz-Elements ist das head-Element. Sie verwenden das xsl:value-of-Element, um den Inhalt des head-Elements auszuwählen (select) und es direkt im Ausgabebaum zu platzieren. Sie müssen die Standard-HTML-Markup-Tags aufnehmen, die zum Erstellen einer HTML-Seite erforderlich sind. Die vollständige Schablonenregel sollte so aussehen:
<xsl:template match = "notiz">
<HTML>
<BODY><xsl:value-of select="head"/></BODY>
</HTML>
</xsl:template>
Diese Regel wird ausgeführt, wenn der Prozessor eine Übereinstimmung für das notiz- Element findet, was in diesem Fall nicht passiert. Anschließend schreibt er die Tags <HTML> und <BODY> in den Ergebnisbaum. An dieser Stelle trifft der Prozessor auf ein xsl:value-of- Attribut. Wie bereits erwähnt, gibt dieses den ausgewählten Inhalt direkt an den Ergebnisbaum aus. Anschließend schließt die Schablone die BODY- und HTML-Tags korrekt ab. Listing 16.2 zeigt das vollständige XSL-Dokument, das unter dem Namen nachricht01_16.xsl abgelegt wird.
Listing 16.2: XSL-Transformationsdokument - nachricht01_16.xsl
1: <?xml version="1.0"?>
2: <!-- Listing 16.2 - nachricht01_16.xsl -->
3:
4: <xsl:stylesheet version = "1.0"
5: xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
6:
7: <xsl:template match = "notiz">
8: <HTML>
9: <BODY><xsl:value-of select="head"/></BODY>
10: </HTML>
11: </xsl:template>
12:
13: </xsl:stylesheet>
![]()
Das Wurzelelement (xsl:stylesheet) beginnt in Zeile 4 mit einem version- und einem xmlns-Attribut.
Wenn Sie beide Dokumente angelegt und gespeichert haben, verarbeiten Sie sie unter Verwendung des XSLT-Prozessors XT, um einen Ausgabebaum als nachricht01_16.html zu erzeugen. Unter Windows kann die Befehlszeilenanweisung folgendermaßen aussehen:
xt nachricht01_16.xml nachricht01_16.xsl nachricht01_16.html
Wenn Sie eine andere Version von XT verwenden, kann Ihre Befehlszeilenanweisung wie folgt aussehen:
java -Dcom.jclark.xsl.sax.parser=ihr-Sax-Treiber
com.jclark.xsl.sax.Driver nachricht01_16.xml nachricht01_16.xsl nachricht01_16.html
Werden keine Fehler zurückgemeldet, haben Sie die Datei nachricht01_16.html angelegt, die in einem Browser angezeigt werden kann wie in Abbildung 16.2. Weil Sie HTML erzeugt haben, kann es in fast jedem Browser angezeigt werden, der HTML unterstützt.
Abbildung 16.2: Das Ergebnis einer XSL-Transformation, dargestellt in Netscape 6
Vergessen Sie nicht, dass XSLT in der Lage ist, die unterschiedlichsten Textausgabeformate zu erzeugen. HTML stellt nur eine der Möglichkeiten dar. HTML ist praktisch, wenn Sie Ausgaben für das Web erzeugen, die von Benutzern mit unterschiedlichen Browsern angezeigt werden. Sie können mit XSLT aber auch andere XML-Dialekte oder Textdateien erzeugen, wie bereits erwähnt. Das kann vorteilhaft sein, wenn Sie beispielsweise ein XML-Dokument in WML (Wireless Markup Language) erstellen wollen, um es auf webfähigen funkgesteuerten Geräten anzuzeigen wie beispielsweise Handys oder PDAs.
Weil die Reihenfolge der Regeln keine Rolle spielt, kann XSLT eine Schablonenregel ganz einfach wiederverwenden. Damit eine Regel verarbeitet wird, ist nur eine erfolgreiche Übereinstimmung erforderlich. Enthält Ihr XML-Dokument wiederholte Elemente, kann eine Regelmenge ihre Verarbeitung übernehmen, indem sie mehrfach angewendet wird. In der nächsten Übung werden Sie das Ergebnis dieses iterativen Prozesses sehen.
Machen Sie das XML-Quelldokument größer. Sie brauchen Daten, die Sie für die rest- lichen Übungen verwenden können. Das Dokument sollte ein notiz-Wurzelelement haben, das mehrere nchr-Elemente enthält. Jedes nchr-Element enthält ein quelle-, von- und nachricht-Element mit Textinhalt. Dabei kann es sich um einen beliebigen Textinhalt handeln, aber Sie sollten sicherstellen, dass Ihre Elemente nur mit den hier angegebenen übereinstimmen, sodass die Transformationen korrekt ausgeführt werden. Listing 16.3 zeigt ein Beispiel für ein XML-Quelldokument. Legen Sie es an und speichern Sie es unter dem Namen nachricht02_16.xml.
Listing 16.3: Ein komplexeres XML-Quelldokument - nachricht02_16.xml
1: <?xml version="1.0"?>
2: <!-- Listing 16.3 - nachricht02_16.xml -->
3:
4: <?xml-stylesheet type="text/xsl" href="nachricht02_16.xsl"?>
5:
6: <notiz>
7: <nchr>
8: <quelle>Telefon</quelle>
9: <von>Kathy Shepherd</von>
10: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen</nachricht>
11: </nchr>
12:
13: <nchr>
14: <quelle>E-Mail</quelle>
15: <von>Greg Shepherd</von>
16: <nachricht>Ich brauche ein wenig Hilfe bei den Hausaufgaben</nachricht>
17: </nchr>
18:
19: <nchr>
20: <quelle>E-Mail</quelle>
21: <von>Kristen Shepherd</von>
22: <nachricht>Bitte spiele heute Abend Scribble mit mir</nachricht>
23: </nchr>
24:
25: <nchr>
26: <quelle>Pager</quelle>
27: <von>Kathy Shepherd</von>
28: <nachricht>Kauf eine Flasche Wein, die wir heute Abend mit zu der Party nehmen koennen</nachricht>
29: </nchr>
30:
31: <nchr>
32: <quelle>Telefon</quelle>
33: <von>Kristen Shepherd</von>
34: <nachricht>Kannst du mich zu meiner Freundin fahren?</nachricht>
35: </nchr>
36:
37: <nchr>
38: <quelle>E-Mail</quelle>
39: <von>Greg Shepherd</von>
40: <nachricht>Wir treffen uns in der Bibliothek</nachricht>
41: </nchr>
42:
43: <nchr>
44: <quelle>E-Mail</quelle>
45: <von>Kathy Shepherd</von>
46: <nachricht>Bob hat zurueckgerufen.</nachricht>
47: </nchr>
48:
49: <nchr>
50: <quelle>Pager</quelle>
51: <von>Kathy Shepherd</von>
52: <nachricht>Hol Deine Hemden von der Reinigung ab!</nachricht>
53: </nchr>
54:
55: </notiz>
![]()
Die XSL-Verarbeitungsanweisung in Zeile 4 gibt ein XSL-Stylesheet in nachricht02_16.xsl an. Das Wurzelelement notiz beginnt in Zeile 6 und enthält mehrere nchr-Elemente. Jedes nchr-Element enthält ein quelle-, von- und nachricht-Element mit Zeichendateninhalt.
In dieser Übung erzeugen Sie zwei Vergleichsschablonen. Die eine vergleicht mit dem notiz-Element und erzeugt die Standard-HTML-Tags um den Inhalt des notiz-Elements herum. Sie müssen das xsl:template-Element mit dem Vergleichs-Attribut notiz verwenden. Anschließend können Sie die Standard-HTML-Tags platzieren, beispielsweise HTML, HEAD und BODY. Fügen Sie ein TITLE-Tag ein und dann ein H1-Tag mit dem Inhalt Meine Nachrichten. Die erste Schablone sieht wie folgt aus:
<xsl:template match="notiz">#
<HTML>
<HEAD>
<TITLE>Nachrichten</TITLE>
</HEAD>
<BODY>
<H1>Meine Nachrichten</H1>
<xsl:apply-templates/>
</BODY>
</HTML>
</xsl:template>
![]()
Wenn diese Regel ausgeführt wird, platziert sie <HTML>, <HEAD>, <TITLE>Nachrichten</TITLE>, </HEAD>, <BODY> und <H1>Meine Nachrichten</H1> direkt in dem Ergebnisbaum. Der Ergebnisbaum ist in diesem Fall eine von Ihnen erzeugte HTML-Seite. Anschließend trifft die Ausführung auf das xsl:apply-templates-Element. Das xsl:apply-templates-Element stellt den Inhalt des verglichenen Elements notiz allen anderen Regeln im XSLT-Dokument zur Verfügung. Weil es sich dabei um das Wurzelelement handelt, enthält es nur weitere Elemente. Insbesondere sind die nchr-Elemente im notiz-Element enthalten. Weil das nchr-Element eine Übereinstimmung erzeugt, verlässt der Prozessor diese Schablone und beginnt mit der Verarbeitung der übereinstimmenden Schablone. Nachdem er damit fertig ist, kehrt er an diese Stelle zurück, um die restlichen Schritte auszuführen, nämlich die BODY- und HTML-Elemente im Ergebnisbaum zu platzieren.
Die zweite Schablone erzeugt nur mit dem nchr-Element eine Übereinstimmung. Dies ist die Schablone, in die der Prozessor gesprungen ist, als er in der ersten Schablone auf das xsl:apply-templates-Element getroffen war. Die Regel in dieser Schablone erzeugt HTML- Markup und ermöglicht, den Inhalt des nchr-Elements in den Ergebnisbaum zu übergeben. In späteren Übungen werden wir das noch verfeinern. Die Regel sieht wie folgt aus:
<xsl:template match="nchr">
<P>Hier ist eine Nachricht:<BR/>
<xsl:apply-templates/>
</P><BR/>
</xsl:template>
Das xsl:apply-templates-Element in der zweiten Regel stellt den Inhalt des nchr- Elements vor; weil es in den untergeordneten Elementen keine übereinstimmenden Regeln gibt, übergibt das xsl:apply-templates-Element den Inhalt direkt an den Ausgabebaum. Das ist in gewisser Weise problematisch.
Das vollständige XSLT-Dokument finden Sie in Listing 16.4. Erstellen Sie dieses Dokument und speichern Sie es unter dem Namen nachricht02_16.xsl.
Listing 16.4: Iterative Verarbeitung in XSLT - nachricht02_16.xsl
1: <?xml version="1.0"?>
2: <!-- Listing 16.4 - nachricht02_16.xsl -->
3:
4: <xsl:stylesheet version="1.0"
5: xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
6:
7: <xsl:template match="notiz">
8: <HTML>
9: <HEAD>
10: <TITLE>Nachrichten</TITLE>
11: </HEAD>
12: <BODY>
13: <H1>Meine Nachrichten</H1>
14: <xsl:apply-templates/>
15: </BODY>
16: </HTML>
17: </xsl:template>
18:
19: <xsl:template match="nchr">
20: <P>Hier ist eine Nachricht:<BR/>
21: <xsl:apply-templates/>
22: </P><BR/>
23: </xsl:template>
24: </xsl:stylesheet>
![]()
Die erste Schablonenregel (Zeilen 7-17) erzeugt eine Übereinstimmung mit dem notiz-Element (Zeile 7). Es werden mehrere Standard-HTML-Tags im Ausgabebaum platziert (Zeilen 8-13). Anschließend legt das xsl:apply-templates-Element den Inhalt des notiz-Elements allen anderen Regeln im Dokument offen. Der Inhalt von notiz ist nchr; die zweite Schablone erzeugt also eine Übereinstimmung. Jetzt hat die zweite Schablone die Steuerung und beim Parsing werden auch die HTML-Tags in Zeile 20 platziert. Das xsl:apply-templates-Element legt den Inhalt des nchr-Elements allen anderen Regeln im Dokument offen. Es werden keine weiteren Regeln angewendet. Der Inhalt des untergeordneten Elements des nchr-Elements wird dem Ausgabebaum gleichzeitig mit dem Auslösen des xsl:apply-templates-Elements übergeben. Nachdem alle nchr-Elemente verarbeitet wurden, geht die Steuerung in Zeile 15 zurück, wo die HTML-Tags abgeschlossen werden.
Nachdem Sie dieses Codebeispiel hergestellt haben, erzeugen Sie daraus mit dem XT- Prozessor nachricht02_16.html und sehen es in einem Browser an. Weil Sie normales HTML erzeugen, wie bereits erwähnt, kann es von fast jedem Browser verarbeitet werden. Einer der Gründe dafür, warum XSLT häufig verwendet wird, um Dokumente von XML in HTML zu übersetzen, ist, weil man Ausgaben erzeugen will, die unabhängig von bestimmten Browsern, Plattformen oder Betriebssystemen sind. Abbildung 16.3 beispielsweise zeigt das erwartete Ergebnis für die Verarbeitung von nachricht02_16.html im W3C-Browser Amaya. Amaya ist ein vom W3C als allgemeines Webwerkzeug bereitgestellter Browser und Editor (http://www.w3.org/Amaya/).
In dem in Listing 16.4 gezeigten Code wird eine interessante Logik ausgeführt, wodurch die XSLT-Verarbeitung scheinbar verwirrend aussieht. Die zweite Regel übergibt den Inhalt der untergeordneten Elemente des nchr-Elements, auch wenn Sie dies nicht explizit formuliert haben. Dieser Ansatz funktioniert, aber es gibt eine andere, intuitivere Möglichkeit, die direkte Übergabe von Inhalt in den Ausgabebaum zu realisieren. Dieser Ansatz ist, darauf zu vergleichen und ihn explizit zu verarbeiten.
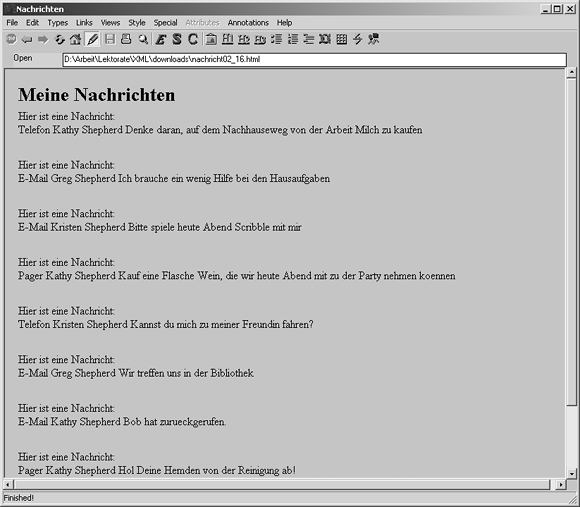
Abbildung 16.3: Ergebnis der iterativen XSLT-Verarbeitung, dargestellt in einem Amaya-Browser
Weil XSLT Ihnen ermöglicht XPath-Anweisungen als Werte bestimmter Attribute zu verwenden, können Sie Ihre Kontrolle über die Auswahl von Knoten unter Verwendung der Logik verbessern, die Sie in Kapitel 9 kennen gelernt haben. Beispielsweise können Sie Text-Knoten unter Verwendung des XPath-Ausdrucks text() oder den aktuellen Knoten mit einem Punkt (.) auswählen. Diese Ausdrücke würden die zuvor als Werte von match- oder select-Attributen verwendeten Namen als explizite Elementnamen verwenden.
In der aktuellen Übung können und sollen Sie eine Schablone erzeugen, die auf alle XPath text()-Knoten vergleicht und den resultierenden Text der HTML-Seite mit dem zuvor beschriebenen xsl:value-of-Element übergibt. Durch diese explizite Verarbeitung von Text können Sie sicher gehen, dass die Ergebnisse wie erwartet aussehen, und Sie können die Ausgabe nach Bedarf weiter formatieren. Wenn Sie diese Regel formulieren, können Sie einfach Folgendes schreiben:
<xsl:template match="text()">
<xsl:value-of select="."/>
</xsl:template>
Fügen Sie diese Schablonenregel in Ihr XSL-Dokument ein und speichern Sie das Ergebnis unter dem Namen nachricht03_16.xsl. Um sicherzustellen, dass alles funktioniert hat, wandeln Sie das Dokument nachricht02_16.xml mit XT unter Verwendung des Dokuments nachricht03_16.xls um, um nachricht03_16.html als Ausgabe zu erzeugen, und zeigen die resultierende HTML-Datei in einem Browser an. In Ihrem Dokument nachricht02_16.xml ändern Sie das href-Attribut (Zeile 4, Listing 16.3) in die xml-stylesheet-Verarbeitungsanweisung um, um die Datei nachricht03_16.xsl zuzuweisen. Die überarbeitete Verarbeitungsanweisung sieht wie folgt aus:
<?xml-stylesheet type="text/xsl" href="nachricht03_16.xsl"?>
Listing 16.5 zeigt das vollständige Dokument nachricht03_16.xsl.
Listing 16.5: Ein Vergleich mit Text-Knoten wurde hinzugefügt - nachricht03_16.xsl
1: <?xml version="1.0"?>
2: <!-- Listing 16.5 - nachricht03_16.xsl -->
3:
4: <xsl:stylesheet version="1.0"
5: xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
6:
7: <xsl:template match="notiz">
8: <HTML>
9: <HEAD>
10: <TITLE>Nachrichten</TITLE>
11: </HEAD>
12: <BODY>
13: <H1>Meine Nachrichten</H1>
14: <xsl:apply-templates/>
15: </BODY>
16: </HTML>
17: </xsl:template>
18:
19: <xsl:template match="nchr">
20: <P>Hier ist eine Nachricht:<BR/>
21: <xsl:apply-templates/>
22: </P><BR/>
23: </xsl:template>
24:
25: <xsl:template match="text()">
26: <xsl:value-of select="."/>
27: </xsl:template>
28:
29: </xsl:stylesheet>
![]()
Diesem Listing wurde in den Zeilen 25-27 eine Schablone hinzugefügt, die auf Text-Knoten vergleicht (match="text()"). Der XPath-Ausdruck text() gibt untergeordnete Text-Knoten des Inhalts-Knotens zurück. Die XPath-Anweisung xsl:value-of mit select="." weist den Prozessor an, den gesamten dem aktuellen Knoten zugeordneten Text dem Ausgabebaum zu übergeben (Zeile 26). Aus Kapitel 9 wissen Sie, dass der Punkt (.) auf den aktuellen Knoten des XML-Baums verweist.
Im vorigen Beispiel haben Sie XML in HTML umgewandelt, aber das Ergebnis war nicht ganz zufrieden stellend. Der Textinhalt der quelle-, von- und nachricht-Elemente wurde innerhalb eines einzigen Zeichenstrings ausgegeben. In dieser Übung werden Sie Schablonenregeln formulieren, die auf diese Elemente vergleichen und ihren Inhalt jeweils in Zellen einer HTML-Tabelle platzieren. Das ist eine sehr praktische Methode, die selbst dann effektiv eingesetzt werden kann, um Daten auf einer HTML-Seite anzuzeigen, wenn sehr große XML-Quelldokumente vorliegen.
Die erste Schablone vergleicht auf den Wurzel-Knoten. Statt den Wurzel-Knoten anzugeben, verwenden wir jetzt den XPath-Ausdruck für den Wurzel-Knoten. Wie Sie aus Kapitel 9 wissen, ist das ein Schrägstrich (/). Ob Sie den Wurzel-Knoten explizit angeben oder die XPath-Kurzform (/) dafür verwenden, bleibt ganz Ihnen überlassen. Beide erzeugen identische Ergebnisse. Die Alternative wird hier nur deshalb erwähnt, um Ihnen die verschiedenen Möglichkeiten zu zeigen. In der Praxis trifft man beide Ansätze an, aber die Kurzformversion wird immer beliebter. In der ersten Schablone fügen Sie HTML-Tags ein, um eine Tabelle anzulegen. Das border-Attribut soll auf 1%, das width-Attribut auf 100% gesetzt werden. Die erste Schablone kann folgendermaßen aussehen:
<xsl:template match="/">
<HTML>
<HEAD>
<TITLE>Nachrichten</TITLE>
</HEAD>
<BODY>
<H1>Meine Nachrichten</H1>
<TABLE BORDER="1" WIDTH="100%">
<xsl:apply-templates/>
</TABLE>
</BODY>
</HTML>
</xsl:template>
Die einzigen neuen Elemente sind die TABLE-Tags und die Auswahl des Wurzel-Knotens unter Verwendung eines Schrägstrichs. Jetzt erstellen Sie eine Schablone für die Tabellenzeilen, die dem nchr-Element entsprechen. Sie kann wie folgt aussehen:
<xsl:template match="nchr">
<TR>
<xsl:apply-templates/>
</TR>
</xsl:template>
Die nächste Regel füllt die Tabellenzellen mit dem Inhalt von quelle, von und nachricht. Sie fragen sich vielleicht, warum Sie nur eine Schablonenregel brauchen, um den Inhalt dreier Elemente zu berücksichtigen. Dank der Integration von XPath-Ausdrücken in XSLT können Sie das Pipe-Symbol (|) als Boolesches »Oder« zwischen den Namen von Elementen angeben, auf die Sie dieselbe Schablone anwenden wollen. Die endgültige Regel sieht wie folgt aus:
<xsl:template match="quelle | von | nachricht">
<TD>
<xsl:apply-templates/>
</TD>
</xsl:template>
Listing 16.6 zeigt eine Kombination des Ganzen.
Listing 16.6: Tabellen mit XSLT anlegen - nachricht04_16.xsl
1: <?xml version="1.0"?>
2: <!--Listing 16.6 - nachricht04_16.xsl -->
3:
4: <xsl:stylesheet version="1.0"
5: xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
6:
7: <xsl:template match="/">
8: <HTML>
9: <HEAD>
10: <TITLE>Nachrichten</TITLE>
11: </HEAD>
12: <BODY>
13: <H1>Meine Nachrichten</H1>
14: <TABLE BORDER="1" WIDTH="100%">
15: <xsl:apply-templates/>
16: </TABLE>
17: </BODY>
18: </HTML>
19: </xsl:template>
20:
21: <xsl:template match="nchr">
22: <TR>
23: <xsl:apply-templates/>
24: </TR>
25: </xsl:template>
26:
27: <xsl:template match="quelle | von | nachricht">
28: <TD>
29: <xsl:apply-templates/>
30: </TD>
31: </xsl:template>
32:
33: </xsl:stylesheet>
![]()
Die Zeile 7 erzeugt eine Übereinstimmung mit dem Wurzel-Knoten des XML-Dokuments, sodass die erste Schablone auf die gesamte XML-Instanz angewendet wird. Die TABLE-Tags in den Zeilen 14 und 16 umschließen den restlichen Ergebnisbaum. Die Schablone in den Zeilen 21-25 richtet die Tabellenzeilen ein, indem sie die nchr-Containerelemente auswählt. Zeile 27 zeigt, wie eine einzelne Regel auf drei verschiedene Elemente vergleichen kann.
![]()
Einige der heutigen Beispiele verwenden XT, während andere den XML-Editor XRay von Architag verwenden. Sie können dieselben Werkzeuge wie hier gezeigt verwenden, aber auch Ihre eigenen einsetzen. Beispielsweise kann XRay nur auf Windows-Systemen eingesetzt werden, aber auch Unix-Benutzer haben die Möglichkeit, XSLT einzusetzen, unter anderem mit XT, Apache Xalan und anderen. Unabhängig davon, welche XSLT-Engine Sie verwenden, kann der Code für die heute gezeigten Beispiele ohne größere Änderungen unmittelbar verwendet werden. Lesen Sie jedoch in der Dokumentation der von Ihnen verwendeten Engine nach, um etwaige Laufzeit-Optionen oder versionsabhängige Besonderheiten zu beachten.
Wenn Sie das Beispiel genau nachvollziehen wollen, verwenden Sie den XML-Editor XRay für die Verarbeitung. Gehen Sie dazu wie folgt vor:

Abbildung 16.4: Die XSLT-Transformation hat eine Tabelle ergeben, die hier im XML-Editor XRay angezeigt wird.
XSLT bietet umfassende Sortierfunktionen, sodass Sie ausgewählte Knoten in aufsteigender oder absteigender Reihenfolge sortieren können. Darüber hinaus können Sie auch nach Groß- und Kleinbuchstaben sortieren und nach Datentypen. In der nächsten Übung werden Sie die Zeilen der Tabelle abhängig von der von-Spalte in aufsteigender alphabetischer Reihenfolge sortieren. Dazu fügen Sie eine Schablone in das existierende XSLT-Programm ein. Diese Schablone vergleicht auf das Wurzelelement notiz. Anschließend verwenden Sie die xsl:apply-templates-Elemente, fügen aber ein Attribut hinzu, um das nchr-Element auszuwählen. Damit teilen Sie der XSLT-Engine mit, dass sie nur die ausgewählten untergeordneten Knoten verarbeiten soll. In diesem speziellen Dokument ist nchr der einzige untergeordnete Knoten von notiz, aber Sie sollten dieses praktische Attribut unbedingt kennen, um es in eigenen Anwendungen sinnvoll einsetzen zu können. Wird keine Auswahl vorgegeben, werden alle untergeordneten Knoten verarbeitet. Das xsl:sort-Element wird als Inhalt des xsl:apply-templates-Elements aufgenommen. Für das xsl: sort-Element geben Sie zwei Attribute an: select und order. Das select-Attribut gibt an, welche Elemente sortiert werden, und order gibt an, ob in aufsteigender oder in absteigender Reihenfolge sortiert werden soll. Eine vollständige Liste aller verfügbaren Attribute für jedes Element finden Sie unter http://www.w3.org/TR/xslt. Die vollständige neue Regel sieht jetzt so aus:
<xsl:template match="notiz">
<xsl:apply-templates select="nchr">
<xsl:sort select="von" order="ascending"/>
</xsl:apply-templates>
</xsl:template>
Fügen Sie diese Regel Ihrem Dokument nachricht04_16.xsl in XRay hinzu und speichern Sie die Datei unter dem Namen nachricht05_16.xsl. Listing 16.7 zeigt das vollständige neue Dokument.
Listing 16.7: Tabellenzeilen mit XSLT sortieren - nachricht05_16.xsl
1: <?xml version="1.0"?>
2: <!--Listing 16.7 - nachricht05_16.xsl -->
3:
4: <xsl:stylesheet version="1.0"
5: xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
6:
7: <xsl:template match="/">
8: <HTML>
9: <HEAD>
10: <TITLE>Nachrichten</TITLE>
11: </HEAD>
12: <BODY>
13: <H1>Meine Nachrichten</H1>
14: <TABLE BORDER="1" WIDTH="100%">
15: <xsl:apply-templates/>
16: </TABLE>
17: </BODY>
18: </HTML>
19: </xsl:template>
20:
21: <xsl:template match="nchr">
22: <TR>
23: <xsl:apply-templates/>
24: </TR>
25: </xsl:template>
26:
27: <xsl:template match="notiz">
28: <xsl:apply-templates select="nchr">
29: <xsl:sort select="von" order="ascending"/>
30: </xsl:apply-templates>
31: </xsl:template>
32:
33: <xsl:template match="quelle | von | nachricht">
34: <TD>
35: <xsl:apply-templates/>
36: </TD>
37: </xsl:template>
38: </xsl:stylesheet>
![]()
Die neue Schablonenregel sehen Sie in den Zeilen 27-31. Die Regel vergleicht auf das Wurzelelement notiz (Zeile 27). Die Schablone wird nur auf das untergeordnete nchr-Element des übereinstimmenden Knotens angewendet. Die untergeordneten nchr-Elemente werden von XSLT in aufsteigender alphabetischer Reihenfolge angewendet. Der Rest des Beispiels bleibt unverändert.
Haben Sie bei der Eingabe von Zeichen in XRay bemerkt, dass sich Ihre Anzeige in allen vier Fenstern geändert hat? Der Parser versucht, die XML-Instanzdokumente für jede Tastatureingabe auszuwerten. Nachdem Sie fertig sind, wurde Ihre Tabelle neu sortiert, wie in Abbildung 16.5 zu sehen ist.
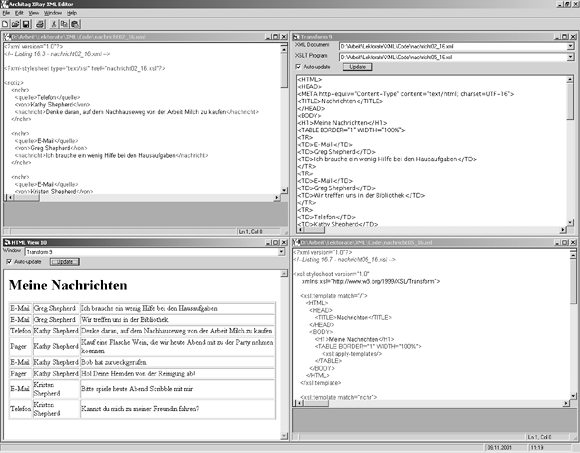
Abbildung 16.5: Die Tabelle wurde nach der von-Spalte in aufsteigender Reihenfolge sortiert.
Im nächsten Beispiel werden Sie einem HTML FONT-Tag Attribute für Farbe, Größe und Schriftart hinzufügen, um den Nachrichten in einer Spalte der Tabelle einen Stil zuzuordnen. Das xsl:attribute-set-Element sollte ein unmittelbar untergeordnetes Element des Wurzelelements sein und kann xsl:attribute-Elemente enthalten, die zur Definition von Attributen verwendet werden. Der xsl:attribute-Ansatz bietet dem Entwickler zahlreiche Möglichkeiten, umfassende Beziehungen zwischen Elementen und Attributen im Ergebnisbaum einzurichten.
Jedes xsl:attribute-Element hat ein zwingend erforderliches name-Attribut, das dem erzeugten Attribut einen Namen zuordnen kann. Angenommen, Sie wollen, dass der Nachrichtentext in Ihrer Tabelle rot erscheint. Sie können ein Attribut für die Farbe erstellen und es in der Transformation nach Bedarf anwenden. Das xsl:-Attribute-set- Element in Ihrem Beispiel würde folgendermaßen aussehen:
<xsl:attribute-set name=" nachricht-attribute ">
<xsl:attribute name="size">+1</xsl:attribute>
<xsl:attribute name="color">blue</xsl:attribute>
<xsl:attribute name="face">Verdana</xsl:attribute>
</xsl:attribute-set>
Das Attribut name="nachricht-attribute" für das xsl:attribute-set-Element ist eine Referenz, die im nächsten Schritt aufgerufen wird. Die drei xsl:attribute-Elemente erzeugen drei Attribute mit entsprechenden Werte. Sie werden einem Element des Ergebnisbaums während der Transformation übergeben. In diesem Fall sind die Attribute HTML FONT-Attribute, denen in der Transformation ein FONT-Tag zugeordnet werden soll. Eine neue Schablonenregel wird erstellt, um den Attributen das FONT-Element zuzuordnen. Weil Sie im Original-XML nur für die nachricht-Elemente einen Stil einführen wollen, erfolgt der Vergleich nur auf das nachricht-Element. Und so sieht die neue Schablonenregel aus:
<xsl:template match="nachricht">
<TD>
<FONT xsl:use-attribute-sets="nachricht-attribute">
<xsl:apply-templates/>
</FONT>
</TD>
</xsl:template>
Wie Sie sehen, richtet das Tag <FONT xsl:use-attribute-sets="nachricht--Attribute"> die Kodierung für die Attribute im FONT-Tag des Ergebnisbaums ein. Damit das korrekt funktioniert, müssen Sie jedoch noch das nachricht-Element aus dem Vergleichs-Attribut der vorherigen Schablone entfernen. Listing 16.8 zeigt den fertigen Code für dieses Beispiel.
Listing 16.8: Attributstile mit XSLT anwenden - nachricht06_16.xsl
1: <?xml version="1.0"?>
2: <!--Listing 16.8 - nachricht06_16.xsl -->
3:
4: <xsl:stylesheet version="1.0"
5: xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
6:
7: <xsl:template match="/">
8: <HTML>
9: <HEAD>
10: <TITLE>Nachrichten</TITLE>
11: </HEAD>
12: <BODY>
13: <H1>Meine Nachrichten</H1>
14: <TABLE BORDER="1" WIDTH="100%">
15: <xsl:apply-templates/>
16: </TABLE>
17: </BODY>
18: </HTML>
19: </xsl:template>
20:
21: <xsl:attribute-set name="nachricht-attribute">
22: <xsl:attribute name="size">+1</xsl:attribute>
23: <xsl:attribute name="color">blue</xsl:attribute>
24: <xsl:attribute name="face">Verdana</xsl:attribute>
25: </xsl:attribute-set>
26:
27: <xsl:template match="nachricht">
28: <TD>
29: <FONT xsl:use-attribute-sets="nachricht-attribute">
30: <xsl:apply-templates/>
31: </FONT>
32: </TD>
33: </xsl:template>
34:
35: <xsl:template match="nchr">
36: <TR>
37: <xsl:apply-templates/>
38: </TR>
39: </xsl:template>
40:
41: <xsl:template match="notiz">
42: <xsl:apply-templates select="nchr">
43: <xsl:sort select="von" order="ascending"/>
44: </xsl:apply-templates>
45: </xsl:template>
46:
47: <xsl:template match="quelle | von ">
48: <TD>
49: <xsl:apply-templates/>
50: </TD>
51: </xsl:template>
52: </xsl:stylesheet>
Abbildung 16.6: Ausgewähltem Inhalt mit XSLT einen Stil zuordnen
![]()
Die Zeilen 21-25 beinhalten die Attributmenge (xsl:attribute-set) mit dem Referenznamen nachricht-attribute. Die Zeilen 22, 23 und 24 richten Attribute für Größe, Farbe und Schriftart ein. Die neue Schablone in den Zeilen 27-33 vergleicht auf das nachricht-Element im XML-Quelldokument. Der Referenzname nachricht-attribute wird vom xsl:use-attribute-sets-Attri-but für das FONT-Tag angewendet. Das nachricht-Element wurde aus dem xsl:template-Element in Zeile 47 entfernt. Abbildung 16.6 zeigt das Ergebnis der Transformation im IE-Browser.
Wie die meisten Programmiersprachen enthält auch XSLT Elemente, die für bedingte Vergleiche, Schleifen über bestimmte Knoten und Wechsel zwischen verschiedenen Logikverzweigungen verwendet werden. Sie können im Rahmen der heutigen Übungen nicht vorgestellt werden, aber in diesem Referenzabschnitt sollen einige der wichtigsten Elemente aufgezeigt werden, die diese Konstrukte anbieten. Tabelle 0.1 listet die Elemente auf; weitere Informationen darüber finden Sie unter http://www.w3.org/TR/ xslt.html.
Das xsl:for-each-Element erlaubt die Anwendung einer einfachen Schleife in XSLT, die sich über eine bestimmte Knoten-Menge erstrecken kann. Diese Anweisung ist praktisch für die Verarbeitung wiederholt auftretender Knoten. Die Syntax des xsl:for-each- Elements lautet:
<xsl:for-each select="Knoten">
Schablonenrumpf
</xsl:for-each>
Der Wert des select-Attributs kann ein beliebiger XPath-Ausdruck sein. Sie können mit einem xsl:for-each-Element beispielsweise jedes der nchr-Elemente in Ihrem Dokument nachricht02_16.xml (Listing 16.3) auswählen:
<xsl:for-each select="nchr">
Angenommen, Sie wollen den Inhalt der quelle-, von- und nachricht-Elemente aus jedem übergeordneten nchr-Element in die Zellen einer HTML-Tabelle einfügen. Dazu können Sie eine Schablone mit xsl:for-each formulieren:
<xsl:for-each select="nchr">
<TR>
<TD><xsl:value-of select="quelle"/></TD>
<TD><xsl:value-of select="von"/></TD>
<TD><xsl:value-of select="nachricht"/></TD>
</TR>
</xsl:for-each>
Das xsl:for-each-Element stellt eine Möglichkeit dar, die Eingabe-Knoten funktional den gewünschten Ausgabe-Knoten zuzuordnen. Beispielsweise erzeugt der Codeabschnitt für jedes nchr-Element im Dokument nachricht02_16.xml eine Tabellenzeile mit Zellen, die mit dem Inhalt der quelle-, von- und nachricht-Elemente gefüllt werden.
Das xsl:if-Element in XSLT erlaubt, dass eine Anweisung genau dann ausgeführt wird, wenn eine bestimmte Boolesche Bedingung zutrifft. Anders als die if-Anweisung in den meisten Sprachen gibt es für die xsl:if-Anweisung keine entsprechende else-Anweisung. Ergibt die überprüfte Bedingung den Wert True, wird die Anweisung ausgeführt. Die Syntax des xsl:if-Elements sieht wie folgt aus:
<xsl:if test=Ausdruck>
Schablonenrumpf
</xsl:if>
Wenn Sie beispielsweise nur die nchr-Elemente des Dokuments nachricht02_16.xml auswählen wollen, die untergeordnete quelle-Elemente mit dem Inhalt E-Mail haben, können Sie Folgendes schreiben:
<xsl:for-each select="nchr" >
<xsl:if test="quelle='E-Mail'">
<xsl:value-of select="nachricht"/><br/>
</xsl:if>
</xsl:for-each>
Wenn Sie diesen Ausschnitt in eine Schablone einfügen, die in Ihrem Dokument auf das notiz-Element vergleicht, gibt es den Inhalt der nachricht-Elemente zurück, für die das quelle-Element den Inhalt E-Mail hat:
Ich brauche ein wenig Hilfe bei den Hausaufgaben
Bitte spiele heute Abend Scribble mit mir
Wir treffen und in der Bibliothek!
Bob hat zurückgerufen.
Das xsl:choose-Element in XSLT definiert eine bedingte Schablone, die unter verschiedenen Alternativen wählt. Das xsl:choose-Element stellt eine ähnliche Funktionalität wie die Anweisungen switch, if-then-else oder select in anderen Programmiersprachen dar. Das xsl:choose-Element hat keine Attribute Es handelt sich dabei um ein Containerelement, das ein oder mehrere untergeordnete xsl:when-Elemente und möglicherweise ein untergeordnetes xsl:otherwise-Element enthält. Es kann beliebig viele xsl:when-Elemente enthalten, aber in jedem xsl:choose-Element muss mindestens eines enthalten sein. Das xsl:otherwise-Element ist optional, aber wenn es vorhanden ist, muss es das letzte Element im xsl:choose-Element sein.
<xsl:choose>
<xsl:when test=Ausdruck>
Schablonenrumpf
</xsl:when>
<xsl:otherwise>
Schablonenrumpf
</xsl:otherwise>
</xsl:choose>
Das xsl:when-Element erlaubt, dass eine Anweisung dann ausgeführt wird, wenn eine Bedingung einen Booleschen True-Wert ergibt, vergleichbar mit der Arbeitsweise und den Kriterien des xsl:if-Elements. Das test-Attribut kann einen beliebigen XPath-Ausdruck als Wert haben. Weil xsl:otherwise die Auswahl trifft, wenn die xsl:when-Elemente nicht erfüllt werden können, ist dafür kein Boolescher Vergleich erforderlich.
Wenn Sie beispielsweise den Inhalt Ihrer nachricht-Elemente abhängig vom Inhalt des quelle-Elements unterschiedlich behandeln wollen, formulieren Sie ein xsl:choose- Element, das jeden der möglichen Werte des quelle-Elements überprüft. Vielleicht wollen Sie eine Beschriftung einführen, die die Quelle jeder Nachricht anzeigt. Für nchr- Elemente, die ein untergeordnetes quelle-Element mit dem Inhalt E-Mail haben, können Sie die Beschriftung E-Mail-Nachricht: anzeigen usw. Der Code für das xsl:choose- Element wird etwa folgendermaßen aussehen:
<xsl:choose>
<xsl:when test="quelle='E-Mail'">
<P>E-Mail-Nachricht:
<xsl:value-of select="nachricht"/><br/>
</P>
</xsl:when>
<xsl:when test="quelle='Telefon'">
<P>Telefon-Nachricht:
<xsl:value-of select="nachricht"/><br/>
</P>
</xsl:when>
<xsl:otherwise>
<P>Pager-Nachricht:
<xsl:value-of select="nachricht"/><br/>
</P>
</xsl:otherwise>
</xsl:choose>
Im Fall des Dokuments nachricht02_16.xml können Sie XPath-Ausdrücke verwenden, um auf zwei von drei Werte des quelle-Elements zu testen. Nach dem Test auf zwei Werte bleibt nur noch der dritte Wert übrig und er könnte deshalb mithilfe des xsl:otherwise- Elements ausgewählt werden. Wenn Sie diesen Codeausschnitt in einer Schablone verwenden, die jedes untergeordnete nchr-Element des notiz-Elements in Ihrem Dokument auswählt, würde es beschriftete Nachrichten ausgeben etwa auf die folgende Art:
Telefon-Nachricht: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
E-Mail-Nachricht: Ich brauche ein wenig Hilfe mit den Hausaufgaben!
E-Mail-Nachricht: Bitte spiele heute Abend Scribble mit mir.
Pager-Nachricht: Kauf eine Flasche Wein, die wir heute Abend mit zu der Party nehmen können!
Phone Nachricht: Bringst du mich zu meiner Freundin?
E-Mail-Nachricht: Wir treffen uns in der Bibliothek!
E-Mail-Nachricht: Bob hat zurückgerufen.
Pager-Nachricht: Hol deine Hemden aus der Reinigung!
Weil ein XSL-Stylesheet eine XML-Instanz ist, die den allgemeinen XML-Syntaxregeln folgt, erwarten Sie vielleicht, dass Sie andere Elemente nach Bedarf verschachteln können. Wenn Sie beispielsweise die Ausgabe abhängig von mehreren Quellen sortieren wollen, können Sie ein xsl:sort-Element in das XSLT-Dokument einfügen, das etwa wie folgt aussieht:
<xsl:sort select="quelle" order="ascending"/>
xsl:choose erlaubt jedoch keine anderen untergeordneten Elemente als xsl:when und xsl:otherwise; deshalb müssen Sie den Sortiervorgang irgendwo außerhalb der xsl:choose-Auswahl durchführen.
Heute haben Sie XSLT (XSL Transformation Language) verwendet, um XML in HTML umzuwandeln. Sie haben gesehen, dass XSLT unabhängig vom restlichen XSL eingesetzt werden kann, um XSLT-Anfragen an einen XSLT-Prozessor zu verarbeiten. Sie haben XT verwendet, einen kostenlosen Java-Prozessor mit einer Befehlszeilen-Schnittstelle, ebenso wie einen Prozessor, der in den XML-Editor XRay eingebaut ist. XSLT verwendet das Konzept der Schablonenvergleiche, um Regelmengen zu erzwingen. XSLT verwendet XPath, um Knoten in einem Quellbaum auf Übereinstimmung zu überprüfen. XSLT ist eine leistungsfähige Technologie, eine ereignisgesteuerte, regelbasierte Programmiersprache.
Frage:
Welche Beziehung besteht zwischen XPath und XSLT?
Antwort:
XPath wird in XSLT-Vergleichsschablonen verwendet, um Elemente zu finden,
die von einer Schablonen-Regelmenge verarbeitet werden sollen. XPath war
ursprünglich eine Komponenten-Technologie. Später wurde es von XSLT
abgespalten, sodass es auch für andere XML-Technologien eingesetzt werden
konnte.
Frage:
Welche Einschränkungen gelten in Bezug auf Hardware und Betriebssystem für XSLT?
Antwort:
XSLT kann auf vielen Systemen eingesetzt werden. Es benötigt nur einen SAX-
basierten Parser sowie eine Bibliothek mit allgemeinen Prozeduraufrufen. Es gibt
Versionen der XSLT-Engines in den meisten bekannten Programmiersprachen für
fast alle gebräuchlichen Computerplattformen.
Frage:
Das Apache-Projekt verfügt über eine XSLT-Engine namens Xalan, die Sie zusammen
mit dem Formatting Objects-Prozessor für Kapitel 15 heruntergeladen haben. Wie kann
Xalan genutzt werden, um XML in HTML umzuwandeln?
Antwort:
Xalan ist ein XSLT-Prozessor der Apache XML-Projektgruppe für die
Transformation von XML-Dokumenten in HTML, Text oder andere XML-
Dokumenttypen. Beispielsweise können Sie Xalan anstelle von XT einsetzen.
Zunächst müssen Sie festlegen, welche Version der Xalan-Engine Sie verwenden
wollen. Zum Zeitpunkt der Drucklegung dieses Buches beinhaltet beispielsweise
die FOP-Distribution Xalan 1.2.2 und Xalan 2.1.0, die beide in Java geschrieben
sind. Neue Versionen von Xalan oder anderer Apache-Projektsoftware können Sie
immer bei http://xml.apache.org/ herunterladen. Weitere Informationen finden
Sie in der Online-Dokumenation der von Ihnen gewählten Version. Wie bei den
meisten Java-Applikationen müssen Sie geeignete Umgebungsvariablen einrichten
und CLASSPATH so setzen, dass die Applikation und alle benötigten
Hilfsapplikationen enthalten sind. In diesem Fall geben Sie die Xerces.jar-Dateien
für den Xerces-Parser an oder entsprechende Dateien für den Parser Ihrer Wahl.
Sie können Xalan von der Befehlszeile aus mit einer Anweisung wie der folgenden
aufrufen:
java org.apache.xalan.xslt.Process -IN meineDatei.xml -XSL meineDatei.xsl
-OUT meineDatei.out
Lesen Sie jedoch in der Dokumentation die Syntax der von Ihnen verwendeten Version nach, weil sie möglicherweise eine andere Befehlsstruktur verwendet. Zum Zeitpunkt der Drucklegung dieses Buches gibt es zweiundzwanzig Flags und Argumente, die in der Befehlszeile angegeben werden können, mit denen Sie Traces, Zeilenschaltungen, HTML-Formatierung usw. steuern können. Weitere Informationen finden Sie in der Dokumentation.
Anhand der Übung können Sie wieder überprüfen, was Sie heute gelernt haben. Die Antwort finden Sie in Anhang A.
XSLT hat ein Element, xsl:number, das übereinstimmende Elemente automatisch nummeriert. Schreiben Sie XSLT-Code, der mithilfe von xsl:number die Titel der CDs in Ihrem Dokument CD.xml nummeriert. Falls Sie Probleme haben, sehen Sie sich auf der W3C-Site die Beispiele für xsl:number an.