




Sie haben gesehen, dass XML ein effizientes und effektives Mittel zur Beschreibung hoch strukturierter Daten mit sich selbst beschreibenden Tags darstellt. Der Wert der Kenntnisse, die wegen dieser vom Autor verfassten Datenbeschreibungen gespeichert werden, erhöht auch den Wert der Struktur. XML selbst stellt jedoch kein Mittel zur Verfügung, wie man spezifische Teilmengen der Daten lokalisieren kann, die in einem Dokument gespeichert sind. Die XML Path Language liefert syntaktische Ausdrücke, mit denen spezifische Datenteile, die in einer Dokument-Instanz gespeichert wurden, lokalisiert werden können. In der heutigen Lektion erfahren Sie Folgendes:
Die XML Path Language (XPath) stellt Ihnen eine Methode zur Verfügung, mit der man spezifische Knoten in einem XML-Dokumentbaum lokalisiert. Anders als XML ist XPath keine Struktursprache. Statt dessen handelt es sich um eine Sprache aus Ausdrücken auf der Grundlage von Strings, die von anderen XML-Technologien verwendet wird, um spezifische Knoten in einer XML-Struktur zu orten und anzusteuern. Das W3C empfiehlt die XPath-Version 1.0.
XPath wurde entwickelt, um mit der Extensible Stylesheet Language Transformations (XSLT) zu arbeiten, die XML-Dokumente in andere Formen verwandelt - etwa in andere XML-Dokumente oder in HTML - und mit der XML Pointer Language (XPointer), die eine Methode anbietet, auf bestimmte Informationen in einem XML-Dokument zu »zeigen«. Tatsächlich stellte das W3C während der Entwicklung von XSLT immer wieder signifikante Überschneidungen fest zwischen den Ausdruckssequenzen, die gestaltet wurden und denen, die für XPointer beschrieben worden waren. Das W3C führte die Mitglieder beider Gruppen zusammen, um eine getrennte, aber einmalige, Ausdruckssprache ohne Überschneidungen zu entwickeln, die von beiden Technologien genutzt werden kann. XPath wurde am 16. November 1999 veröffentlicht, am gleichen Tag wie XSLT. Mehr zur Rolle von XPath bei XSLT erfahren Sie am 16. Tag, wenn Sie Ihre eigenen Transformationen von XML zu HTML durchführen. XPointer wird am 11. Tag detailliert beschrieben.
XPath dient als Sub-Sprache für XSLT und XPointer. Ein XPath-Ausdruck kann bei der Stringmanipulation, bei numerischen Berechnungen und bei der Booleschen Logik verwendet werden. Hauptzweck von XPath und der Funktion, der es seinen Namen verdankt, ist jedoch, sich unter Verwendung einer Pfadnotation, ähnlich den Notationen, mit denen URLs aufgelöst werden und die durch die Dokumenthierarchie navigieren müssen, an Teile eines XML-Dokuments zu richten. XPath setzt sich aus einfachen Ausdrücken zusammen, analog zu den regulären Ausdrücken bei anderen Sprachen. Die Ausdrücke sind durch Pfadsymbole, Knotennamen und reservierte Wörter in einem kompakten String gekennzeichnet, der in einer anderen Syntax geschrieben wird als XML. XPath hat die Funktion, Teilkomponenten eines XML-Dokuments zu lokalisieren, aber es arbeitet auf der Grundlage abstrakter logischer Strukturen in der Instanz, nicht auf Syntaxgrundlage. Was das bedeutet, werden Sie feststellen, wenn Sie später ein XML- Dokument mit XPath-Ausdrücken untersuchen.
Wie Sie wissen, kann man Daten, die in einem XML-Dokument abgelegt sind, als hierarchische Baumstruktur aus einzelnen Knoten darstellen. Einige dieser Knoten können andere Knoten enthalten. Ein Element kann zum Beispiel andere Elemente enthalten. Elemente können auch Zeichendaten enthalten; wenn sie dies aber tun, repräsentieren diese Zeichendaten einen eigenen abgeleiteten Knoten. Der Zugriff auf die Daten, die in einem Knoten enthalten sind, erfordert, dass Sie die Struktur durchqueren, bis Sie zum abgeleiteten Textknoten des Elementknotens kommen. Sie kennen bereits Element- und Attributsknoten und wissen, dass es in einer XML-Dokument-Instanz auch Knoten für Kommentare gibt. XPath kennt sieben Knotentypen. Wenn man mit XPath arbeitet, erhält man eine strukturierte, leicht zu durchsuchende Hierarchie aus Knoten in einer Dokument-Instanz. Noch einmal: Das prinzipielle Konzept, das hinter XPath steht, ist die Durchquerung eines XML-Dokuments bis zur Ankunft an einem bestimmten Knoten. Die Durchquerung erfolgt unter Verwendung von Ausdrücken, die nach den Syntaxregeln von XPath aufgebaut sind. Werden XPath-Ausdrücke ausgewertet, kommt ein Datenobjekt heraus, das als eines der folgenden charakterisiert werden kann:
Der Knotenbaum, den XPath erzeugt, ähnelt der Baumstruktur, die das Document Object Model (DOM) ausmacht. Das DOM stellt Ihnen eine Applikationsprogrammier- Schnittstelle (API) zur Verfügung, mit der Sie auf exponierte Knoten in einem Dokumentbaum unter programmatischer Steuerung zugreifen, sie abfragen modifizieren oder neue Knoten hinzufügen können. Zum DOM kommen wir am 12. Tag.
XPath kennt die folgenden sieben Knotentypen: Wurzel, Element, Attribut, Kommentar, Text, Verarbeitungsanweisung und Namensraum. Der XPath-Baum hat nur einen Wurzelknoten, der alle anderen Knoten im Baum enthält. Verwechseln Sie den Wurzelknoten nicht mit dem Wurzelelement eines XML-Dokuments. Der Wurzelknoten enthält alle anderen Knoten einschließlich des Wurzelelements, alle anderen Elemente, alle Verarbeitungsanweisungen, Namensräume, Kommentare oder Text für die ganze Dokument-Instanz.
![]()
Der Wurzelknoten in einem XPath-Baum ist nicht das Gleiche wie das Wurzelelement in einer XML-Dokument-Instanz. Der Wurzelknoten enthält das Wurzelelement, alle anderen Elementknoten, Attributs- und Kommentarknoten sowie die Knoten für Text, Verarbeitungsanweisungen und Namensräume.
Wie bereits erwähnt, dient der Wurzelknoten als Container für die gesamten übrigen Knoteninhalte in einer XML-Dokument-Instanz. Der Wurzelknoten und die Elementknoten enthalten geordnete Reihen abgeleiteter Knoten. Jeder Knoten außer dem Wurzelknoten hat einen Stammknoten. Stammknoten können von null bis hin zu vielen abgeleiteten Knoten und Abkömmlingen (also Ableitungen der Ableitung) haben. Interessanterweise können nur die Knoten der Elemente, Kommentare, Verarbeitungsanweisungen und für Text abgeleitet sein. Sie erinnern sich, dass ein Attribut einem Adjektiv entspricht; ein Attribut modifiziert ein Element, das dem Substantiv in einer Sprache entspricht. Ein Attribut ist keine Ableitung von einem Element; es stellt einfach zusätzliche Informationen über das Element bereit. Ein Attribut ist einem Element zugeordnet, aber es ist kein abgeleitetes Konstrukt dieses Elements. Auch wenn das verwirrend erscheinen mag, Tatsache ist, dass ein Attribut zwar einen Stamm haben kann, aber nicht die Ableitung von diesem Stamm ist. Ein Stamm enthält seine Ableitungen. Wie Sie am 2. Tag gesehen haben, kann sogar ein leeres Element, das keinen Inhalt hat, zugeordnete Attribute haben. Ein Attribut wird nicht als Inhalt eines Elements betrachtet. Mit der gleichen Logik gilt, dass ein Namensraumknoten einen Stamm haben kann, aber nicht die Ableitung dieses Stamms ist. Ein Namensraum stellt nur zusätzliche Informationen über den Stamm bereit; er beschreibt den Namensraum, in den der Stamm eingebunden ist. Der Namensraumknoten ist eigentlich eine spezialisierte Instanz des Attributsknotens.
![]()
Attributs- und Namensraumknoten haben Stammknoten, sind aber selbst in XPath keine abgeleiteten Knoten dieses Stamms. Attributs- und Namensraumknoten stellen Informationen bereit oder modifizieren ihre Stammknoten, aber sie sind nicht Inhalt ihrer Stammknoten. Ein abgeleiteter Knoten muss in einem Stammknoten enthalten sein.
Um die einzelnen Teile eines Knotenbaums bei XPath besser zu verstehen, werden wir Ihnen ein XML-Dokument mit einem Diagramm der XPathknoten zeigen, die dem Dokument entsprechen. Sie werden eine Version des Dokuments sehen, das Sie an früheren Tagen manipuliert haben, zunächst in seiner XML-Version und dann als Knotenbaum, der mit XPath-Ausdrücken durchsucht werden kann. Listing 9.1 zeigt das XML-Nachrichten-dokument nachricht01_9.xml, das Sie bereits verwendet haben. Um alle sieben XPathknoten darzustellen, schließt das Dokument jetzt eine Verarbeitungsanweisung und Kommentare ein.
Listing 9.1: Ein XML-Dokument, das alle sieben XPathknotenformen einschließt - nachricht01_9.xml
1: <?xml version="1.0"?>
2: <!-- Listing 9.1 - nachricht01_9.xml -->
3:
4: <notiz xmlns="urn:STY_XML_in_21Tagen:XPath">
5:
6: <?Nachrichtprozessor befehl = "NachrichtAufnehmen" ?>
7: <!--Dies ist ein Beispiel fuer eine Verarbeitungsanweisung -->
8:
9: <nachricht typ="telefon nachricht">
10: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
11: <status>dringend</status>
12: </nachricht>
13: </notiz>
![]()
Diese relativ einfache Dokument-Instanz hat ein Wurzelelement notiz, das in Zeile 4 einen Namensraum mit der URI run:STY_XML_in_21Tagen:XPath einschließt. Zeile 6,
6: <?Nachrichtprozessor befehl = "NachrichtAufnehmen" ?>,stellt eine Verarbeitungsanweisung dar. Am 14. Tag werden Sie Verarbeitungsanweisungen verwenden, mit denen Sie XML-Dokument-Instanzen mit Cascading Stylesheets (CSS) verknüpfen, um die Ausgabe auf Clientseite zu formatieren. Am 15. Tag werden Sie mit ähnlichen Verarbeitungsanweisungen für den gleichen Zweck ein Extensible Stylesheet Language (XSL)-Stylesheet mit XML-Dokumenten verbinden. Verarbeitungsanweisungen sind speziell an die Anwendung gerichtet, die das XML-Dokument parst. Das Beispiel in Zeile 6 kann einen NachrichtProzessor erzeugen, der die Nachrichtendaten, die diese XML-Dokument-Instanz bereitstellt, bearbeitet.
Die Zeilen 2 und 7 sind Kommentare. Beachten Sie, dass der Kommentar in Zeile 2 vor dem Wurzelelement der XML-Instanz auftritt, während der Kommentar in Zeile 7 sich innerhalb des notiz-Elements befindet. Da der Wurzelknoten außerhalb des Wurzelelements liegt, kann XPath den Kommentar in Zeile 2 genauso leicht lokalisieren wie den in Zeile 7.
Die XML-Deklaration in Zeile 1 ist nicht in einem Dokumentknoten enthalten. Sie haben vielleicht angenommen, dass es sich um eine Verarbeitungsanweisung handelt, aber technisch gesehen ist das nicht der Fall und XPath hat keinen Ausdruck, um diese Information zu lokalisieren.
Der Rest der Knoten in diesem Dokument umfasst Element- und Attributsknoten, die XPath leicht lokalisieren kann.
Um den Knotenbaum, der aus XPath resultiert, besser zu verstehen, betrachten Sie Abbildung 9.1. Ein solcher Baum zeigt jeden Knotentyp mit dem Inhalt der Knoten. Die Kästchen stehen für die Knotentypen, die XPath kennt, sowie für den Knoteninhalt. Die Zeilen zwischen jedem Kästchen zeigen die Beziehungen der Knoten untereinander. Sie sollten die Knotenkästchen in Abbildung 9.1 auf die eigentlichen Knoten in Listing 9.1, die sie repräsentieren, zurück projizieren können. Gehen Sie das Diagramm Knoten für Knoten durch und lesen Sie dazu die angefügte Beschreibung.
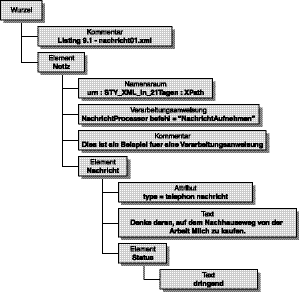
Abbildung 9.1: Ein XPath-Baum für Listing 9.1 - nachricht01_9.xml
Man kann sehen, dass der Wurzelknoten alle anderen Knoten im XPath-Baum enthält. Die XML-Deklaration aus Zeile 1 beim Listing 9.1 ist in dem Diagramm nicht eingeschlossen, weil es im resultierenden XPath-Baum dafür keine Darstellung gibt. Die erste Ableitung des Wurzelknotens ist der Kommentarknoten, der in der Dokument-Instanz vor dem Wurzelelement notiz auftritt. Als Nächstes kommt der Elementknoten für das Element notiz.
Die Zeilen, die aus dem Kästchen für das notiz-Element stammen, enden dort, wo der Namensraumknoten, der Knoten für die Verarbeitungsanweisung, der Kommentarknoten und der Knoten des Elements nachricht einsetzen. XPath betrachtet jeden davon in seiner Beziehung zum Elementknoten. Der Namensraumknoten urn:STY_XML_in_ 21Tagen:XPath ist keine Ableitung des Elementknotens notiz, auch wenn es sich bei diesem Knoten um den Stammknoten für den Namensraum handelt. Der Knoten für die Verarbeitungsanweisung NachrichtProzessor befehl="NachrichtAufnehmen", der Kommentar-knoten und der Knoten für das Element nachricht werden als abgeleitete Knoten des Elementknotens notiz betrachtet.
Der nachricht-Knoten ist Stamm des Attributsknotens typ, auch wenn der Attributsknoten keine Ableitung dieses Stammes ist. Der nachricht-Knoten enthält einen Textknoten und den Elementknoten status als abgeleitete Elemente. Der Elementknoten status enthält einen Textknoten.
Sie haben gesehen, welche einfachen Beziehungen in der Dokument-Instanz nachricht01_9.xml zwischen den Knoten bestehen. Einige Beziehungen sind zunächst aber weniger offensichtlich. Sie sind Stamm- und Ableitungsbeziehungen durchgegangen. Als Nächstes können Sie die Beziehungen von Vorfahren und Abkömmlingen betrachten, die XPath kennt.
![]()
Die Anordnung der Knoten in einem XPath-Baum wird durch die Reihenfolge bestimmt, in der sie im ursprünglichen Dokument der XML-Instanz angetroffen werden. Diese Reihenfolge nennt man Dokumentanordnung. Sie beginnt beim Wurzelknoten und schreitet den XPath-Baum weiter hinunter, parallel zur Anordnung der Elemente, Kommentare, Verarbeitungsanweisungen, Text, Attribute und Namensräume im Dokumentbaum.
Jeder Knoten in einem XPath-Baum umfasst eine Stringdarstellung, die als Stringwert bezeichnet wird und die XPath verwendet, um Knotenvergleiche durchzuführen. Der Stringwert eines Elements ist sein vollständiger Textinhalt plus den Text seiner Abkömmlinge. Zeile 11 von Listing 9.1,
11: <status>dringend</status>,
schließt die Auszeichnung und den Inhalt des status-Elements ein. Betrachten Sie nun den Textknoten des status-Elements, das den Stringwert dringend hat. Der status- Elementknoten hat nur einen zugeordneten Textknoten als Abkömmling, somit ist das alles, was der Stringwert für diesen Knoten einschließt. Der status-Elementknoten und sein abgeleiteter Textknoten haben die gleichen Stringwerte.
![]()
Der Stringwert aller Elementknoten wird bestimmt, indem man die Stringwerte all seiner Textknoten-Abkömmlinge zusammenzieht.
Der Stringwert für das nachricht-Element aus Abbildung 9.1 ist verschachtelter. Er enthält den Textinhalt des Elementknotens nachricht, der wiederum seinerseits die Textknoten seiner Knoten-Abkömmlinge (status) in der Dokumentanordnung enthält - alle Knoten, die nachfolgen. Deshalb ist der Stringwert für den nachricht-Elementknoten Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen dringend. Dies ist der resultierende String, der durch das Zusammenfügen der Stringwerte vom Textknoten und aller Textknoten-Abkömmlinge geformt wird. Der Stringwert des unmittelbar abgeleiteten Knotens für das nachricht-Element ist weiterhin nur Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen und der Stringwert für das status-Element bleibt dringend. Der Stringwert für den nachricht-Elementknoten jedoch ist die Zusammenfügung der beiden anderen, nachfolgenden Stringwerte.
![]()
Knoten-Abkömmlinge sind alle Knoten, die einem Knoten in der Dokumentanordnung nachfolgen.
Können Sie auf der Grundlage des Gelernten den Stringwert des Wurzelknotens für das Dokument in Listing 9.1 bestimmen? Dazu müssen Sie die Stringwerte seiner Textknoten- Abkömmlinge zusammenziehen. Es ist Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen dringend, genau wie beim nachricht-Elementknoten, weil es in dieser Dokument-Instanz keine weiteren Textknoten-Abkömmlinge gibt.
Der Stringwert von Attributsknoten enthält nur den Wert des Attributs. Der Stringwert für den Attributsknoten typ ist daher telefon nachricht. Bei Kommentarknoten sind die Stringwerte der Kommentartext oder Listing9.1-nachricht01_9.xml für den Kommentarknoten, der zum Kommentar in Zeile 2 von Listing 9.1 gehören.
Verarbeitungsanweisungen haben Stringwerte, die die Anweisung nach dem ersten Argument umfassen. Zeile 6 von nachricht01.xml,
6: <?NachrichtProzessor befehl = "NachrichtAufnehmen" ?>,
zeigt die Auszeichnung für eine Arbeitsanweisung. Das erste Argument dieser Anweisung ist NachrichtProzessor, sodass der Stringwert für den Knoten der Verarbeitungsanweisung befehl="NachrichtAufnehmen" ist. Dies gilt für Verarbeitungsanweisungen, die URLs enthalten, wie das bei verlinkten Stylesheets der Fall ist. Mehr zu den Stylesheets am 14. und 15. Tag.
Namensraumknoten haben als Stringwert ihre URIs. Der Stringwert für den Namensraum, der dem notiz-Element zugeordnet ist, ist urn:STY_XML_in_21Tagen:XPath.
Tabelle 9.1 fasst zusammen, was Sie über die sieben Knotentypen bei XPath gelernt haben.
Tabelle 9.1: Die sieben Knotentypen bei XPath
Sie haben von abgeleiteten und Stammknoten erfahren und wissen, dass einige Knoten bei XPath Stammknoten haben, ohne abgeleitete Knoten dieser Stämme zu sein. Attributs- und Namensraumknoten zum Beispiel stellen Informationen bereit oder modifizieren ihre Stammknoten, aber sie sind kein Inhalt ihrer Stammknoten. Ein abgeleiteter Knoten muss in einem Stammknoten enthalten sein. Sie haben sich das Konzept der Stamm- und Ableitungsbeziehungen angeschaut, das auf XPath-Ausdrücke angewendet wird.
XPath kennt im Wesentlichen elf benannte Knotenbeziehungen in einem XML- Dokument. Wenn Sie XPath-Ausdrücke erstellen, geben Sie eine Adresse und einen Pfad zur Lokalisierung dieser Adresse an. Dies nennt man eine Achse, die auf relative Art durchquert werden kann. Der Prozess, von Ihrem Standort an den oder die Knoten zu gelangen, den Sie zu lokalisieren versuchen, verlangt, dass der Standortpfad zum Teil auf Grundlage dieser Achsenbeziehungen durchquert wird.
Damit Sie diese Beziehungen besser verstehen, geben wir Ihnen im folgenden Abschnitt die Gelegenheit, jede dieser Achsenbeziehungen im Einzelnen zu untersuchen. Sie werden eine Textbeschreibung zusammen mit einer Abbildung zu sehen bekommen, die die ausgewählten Knoten auf Grundlage der vorgestellten Beziehung zeigt. Die ausgewählten Knoten werden dabei diejenigen sein, die das Resultat der Auflösung eines Beziehungsdescriptors darstellen, bzw. das Resultat, das die Durchquerung eines bestimmten Lokalisierungspfads ergibt. Die Abbildungen zeigen einen Kontextknoten als Ausgangspunkt für die Beziehungen. Ausgehend von Ihrem aktuellen Referenzpunkt im Kontextknoten weisen Sie den Prozess an, den relativen Lokalisierungspfad zu durchqueren und Zielknoten auszuwählen, die der Beziehung entsprechen, die der XPath- Ausdruck charakterisiert. Das bedeutet, dass der gleiche relative Lokalisierungspfad an unterschiedlichen ausgewählten Knoten enden kann, wenn er ausgehend von zwei verschiedenen Kontextknoten durchquert wird. Im Verlauf der angegebenen Beispiele werden Sie eine ganze Reihe von Kombinationen zu diesem Konzept kennen lernen. Zunächst ist es jedoch wichtig klarzustellen, was die Begriffe Kontextknoten und ausgewählter Knoten bedeuten. Sehen Sie sich die XML-Dokument-Instanz in Listing 9.2 genau an.
Listing 9.2: Eine XML-Dokument-Instanz mit eingebetteten Elementtypen
- auffahrt.xml
1: <?xml version="1.0"?>
2: <!-- Listing 9.2 - auffahrt.xml -->
3:
4: <auffahrt>
5: <auto>
6: <mfgr>Ford</mfgr>
7: <modell>Mustang</modell>
8: <farbe>rot</farbe>
9: </auto>
10: </auffahrt>
Angenommen, der Kontextknoten für einen XPath-Ausdruck, der auf diese Dokument- Instanz angewendet wird, ist der Elementknoten auto und Sie wollen seinen Stammknoten lokalisieren. Der ausgewählte Knoten, in diesem Fall der Stamm, ist dann der Elementknoten auffahrt. Wenn Sie den gleichen Kontextknoten voraussetzen (den Elementknoten auto), dann resultiert die Auswahl der abgeleiteten Knoten in der Lokalisierung der Elementknoten mfgr, modell und farbe. In jedem Fall werden die ausgewählten Knoten auf Grund ihrer relativen Zuordnung zum Kontextknoten bestimmt. Natürlich muss man den Kontextknoten im Auge behalten, wenn man Lokalisierungspfad- Ausdrücke erstellt, weil XPath sich von Natur aus relativ verhält.
Es kann sein, dass der Knoten, den Sie mit einem XPath-Ausdruck lokalisieren wollen, der Kontextknoten ist. In diesem Fall sind Kontextknoten und ausgewählter Knoten identisch. Abbildung 9.2 zeigt einen Baum, der die Knoten für ein XML-Dokument darstellt. Er ähnelt stark einigen anderen Baumstrukturen, die Sie im Verlauf Ihrer Studien bereits kennen gelernt haben. Die Knotennamen sind für den Zweck dieser Ausführungen nicht notwendig; deshalb wurden sie weggelassen. Sie können trotzdem erkennen, dass die Linien, die dort zusammenkommen, Beziehungen zwischen den Knoten anzeigen. Man sieht deutlich, dass manche untergeordnet sind, wenn sie auf einer niedrigeren Ebene der Baumstruktur auftreten. Zusätzlich ist zu sagen, dass diejenigen, die horizontal nebeneinander liegen, Geschwister sind und die gleiche Anzahl an Stammknoten auf der höheren Baumebene haben. Manche Stammknoten haben mehr als eine Ableitung.
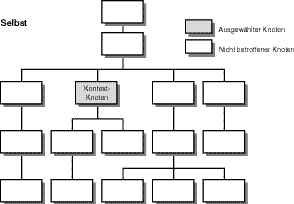
Abbildung 9.2: Ein Knotenbaum in XPath, der nur den Kontextknoten auswählt
Sie sehen den Kontextknoten auf dem zweiten Ast des Knotenbaums. Gemäß der Legende oben rechts wird der ausgewählte Knoten grau angezeigt. In diesem Fall sind Kontextknoten und ausgewählter Knoten identisch. Anders gesagt, die Auswertung eines XPath-Ausdrucks, der sich selbst lokalisiert, gibt den Kontextknoten zurück. Das Konzept des Selbst ist wichtig bei XPath, weil man es mit bestimmten anderen benannten Beziehungen kombinieren kann, sodass der Kontextknoten absichtlich zusammen mit den anderen ausgewählten Knoten im resultierenden Knotensatz eingeschlossen wird. Sie werden später mehrere Beispiele dafür sehen.
Sie haben bereits Stammknoten kennen gelernt. Sie wissen, dass sie normalerweise abgeleitete Knoten enthalten - mit Ausnahme der Attribute und Namensräume, wie bereits erwähnt. Stammknoten nehmen einen übergeordneten Platz im Knotenbaum im Verhältnis zu ihren jeweiligen abgeleiteten Knoten ein. Hinsichtlich des Kontextknotens liegt ein Stammknoten eine Generation oder Ebene höher als ein Kontextknoten im XPath-Baum; daher ist der ausgewählte Knoten, der aus der Auswertung eines XPath- Ausdrucks resultiert, der einen Stammknoten lokalisieren soll, ein einzelner übergeordneter Knoten. Abbildung 9.3 zeigt dies.
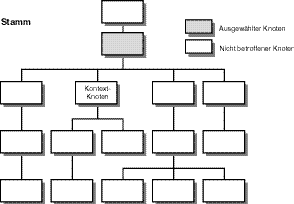
Abbildung 9.3: Ein Knotenbaum in XPath, der eine Stamm-Beziehung anzeigt
Beachten Sie, dass die korrekte Auswahl, die aus einer Stamm-Beziehung resultiert, ein einziger Knoten ist. In den folgenden Beziehungen sehen Sie mitunter mehrere Knoten oder Knotensätze, die als Resultat der Auswertung eines XPath-Ausdrucks ausgewählt werden.
![]()
Bei XPath kann ein Lokalisierungspfad-Ausdruck eine Sammlung von Knoten zurückgeben, die bestimmte Beziehungsmerkmale gemeinsam haben. Eine solche Sammlung bezeichnet man als Knotensatz.
Wie bereits beschrieben, ist ein abgeleiteter Knoten im Stammknoten enthalten. Ein XPath-Ausdruck kann eine beliebige Zahl von abgeleiteten Knoten haben, aber die Ableitungen liegen immer genau eine Ebene unterhalb des Kontextknotens. Abbildung 9.4 zeigt ausgewählte abgeleitete Knoten.
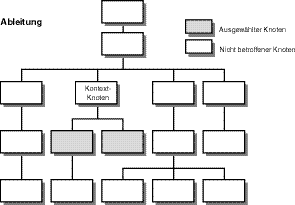
Abbildung 9.4: Zwei abgeleitete Knoten des Kontextknotens werden ausgewählt.
Haben Sie bemerkt, dass einer der abgeleiteten Knoten einen abgeleiteten Knoten hat? Dieser untere Abkömmling wird von einem XPath-Ausdruck, der nur abgeleitete Knoten anfordert, nicht ausgewählt, weil er mehr als eine Ebene vom Kontextknoten entfernt ist. Sie werden gleich sehen, wie man auf Knotensätze verweist, die alle Abkömmlinge einschließen.
Die Vorfahrenknoten umfassen sowohl den Stammknoten als auch den Stammknoten des Stamms usw., den ganzen XPath-Baum hinauf - in umgekehrter Dokumentanordnung - bis zurück zum Wurzelknoten. In Abbildung 9.5 zeigen die ausgewählten Knoten diese Vorfahren-Beziehung an.
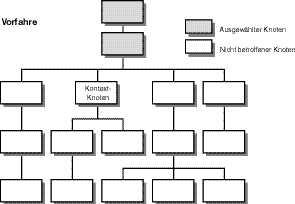
Abbildung 9.5: Ein Knotenbaum in XPath, der eine Vorfahren-Beziehung anzeigt
Sie haben gelernt, dass ein XPath-Ausdruck, der einen Stammknoten lokalisiert, in einem einzigen Knoten resultiert, wogegen ein Vorfahren-Ausdruck alle höher gelegenen Knoten auswählt, die dem Kontextknoten unmittelbar vorausgehen. Nur die Anzahl der Vorfahrenknoten, die zwischen Kontext- und Wurzelknoten liegen, begrenzt diese Auflistung. Der Wurzelknoten ist der letzte Vorfahre aller anderen Knoten im Baum.
Die Vorfahre-oder-Selbst-Beziehung schließt alle Knoten ein, die von einem Vorfahren- Ausdruck lokalisiert werden plus den Kontextknoten, das Selbst. Im Fall des XPath-Baum- Beispiels wählt Vorfahre-oder-Selbst drei Knoten aus, wie in Abbildung 9.6 gezeigt wird.
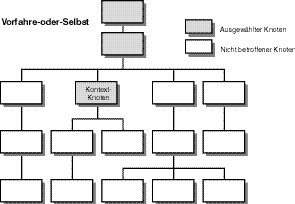
Abbildung 9.6: Eine Vorfahre-oder-Selbst-Beziehung im XPath-Baum
Um die abgeleiteten Elemente und alle Ableitungen von diesen, Ableitungen der Ableitung usw., auszuwählen, muss man die Abkömmling-Beziehung verwenden. Abbildung 9.7 zeigt als Resultat dieser Beziehung drei Knoten. Jeder dieser Knoten ist dem Kontextknoten untergeordnet oder in ihn eingebettet.
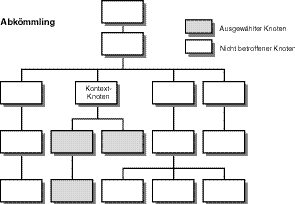
Abbildung 9.7: Ein Knotenbaum in XPath, der eine Abkömmling-Beziehung darstellt
Eine Abkömmling-Beziehung kann eine beliebige Anzahl an Knoten enthalten. Der Knotensatz beginnt mit dem Kontextknoten und wird fortgeführt, bis das Ende der Linie erreicht ist, die dem Kontextknoten untergeordnet ist.
Wie bei der Vorfahre-oder-Selbst-Beziehung kann man auch einen Knotensatz auswählen, der die Abkömmlinge und den Kontextknoten verkörpert. Eine solche Beziehung heißt Abkömmling-oder-Selbst-Beziehung. Diese Beziehung sehen Sie in Abbildung 9.8, die für den Beispielbaum vier ausgewählte Knoten anzeigt.
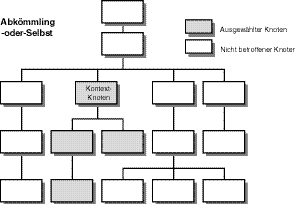
Abbildung 9.8: Ein Knotenbaum in XPath, der eine Abkömmling-oder-Selbst-Beziehung anzeigt
Die Abkömmling-oder-Selbst-Beziehung enthält den Kontextknoten plus alle Knoten, die in ihn eingebettet sind, bis das Ende der Linie erreicht ist.
Sie haben gesehen, dass XPath einen Knotenbaum jeweils in Richtung der Dokumentanordnung oder der umgekehrten Dokumentanordnung durchquert. Das Konzept der folgenden Knoten wählt alle Knoten aus, die es über den Kontextknoten hinaus gibt. Die folgenden Knoten beginnen mit den gleichrangigen Verwandten des Kontextknotens und schließen all deren Abkömmlinge ein. Welche Knoten als die folgenden betrachtet werden, bestimmt die Dokumentanordnung für die Knoten in einem Baum. Alle Knoten, die durchquert werden, bevor man zum Kontextknoten kommt, sind aus der Nachfolge-Beziehung ausgeschlossen. Abbildung 9.9 zeigt eine Nachfolge- Beziehung, die sieben Knoten auswählt.
Haben Sie bemerkt, dass die Nachfolge-Beziehung nicht die abgeleiteten Knoten oder die Abkömmlinge eines Kontextknotens einschließt? Sie schließt nur die Knoten ein, die auf gleichrangiger Ebene nachfolgen sowie deren Abkömmlinge.
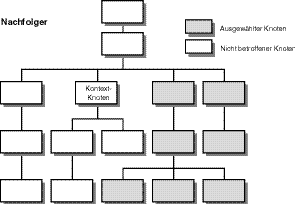
Abbildung 9.9: Ein Knotenbaum in XPath, der eine Nachfolge-Beziehung anzeigt
Die Nachfolge-Geschwister-Beziehung wählt Knoten aus, die sich anschließen und gleichrangig sind, wenn man den XPath-Baum in Richtung der Dokumentanordnung durchquert. Nur die Knoten, die auf der gleichen Ebene liegen wie der Kontextknoten, werden ausgewählt. Abkömmlinge der Geschwister sind aus dem ausgewählten Knotensatz ausgeschlossen. Abbildung 9.10 zeigt diese Beziehung.
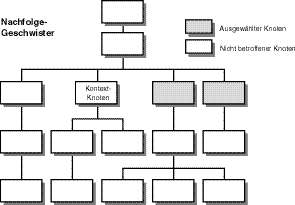
Abbildung 9.10: Ein Knotenbaum in XPath, der eine Nachfolge-Geschwister-Beziehung anzeigt
Die Auswahl der vorangehenden Knoten wird auf eine Weise aufgelöst, die der Nachfolge- Beziehung ähnelt, nur dass die gleichrangigen Verwandten und ihre Abkömmlinge diejenigen sind, die vor dem Kontextknoten auftreten, wenn man sie in der Dokumentanordnung antrifft. Diese Beziehung wird in Abbildung 9.11 gezeigt.
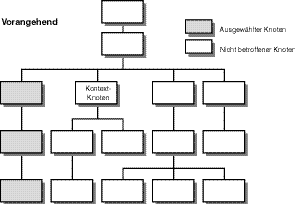
Abbildung 9.11: Ein Knotenbaum in XPath, der eine VorangehendeKnoten-Beziehung anzeigt
Beachten Sie, dass die vorangehenden Elemente nur diejenigen sind, die auf der gleichen horizontalen Ebene liegen wie der Kontextknoten oder eine Ebene tiefer, dass sie aber in einem Dokument vor dem Kontextknoten auftreten. Knoten, die auf einer höheren Ebene liegen, wie Stamm- oder Vorfahrenknoten, werden nicht als vorangehend betrachtet.
Es überrascht nicht, dass es eine Vorangehende-Geschwister-Beziehung gibt, die nur die Knoten auswählt, die gleichrangige Verwandte des Kontextknotens sind, wenn sie in der Dokumentanordnung vor dem Kontextknoten durchquert werden. Abbildung 9.12 zeigt diese Beziehung.
In diesem Abschnitt haben Sie die standardmäßigen Beziehungstypen kennen gelernt, die bei XPath möglich sind. Sie haben gesehen, dass die ausgewählten Knoten immer in verschiedenen Richtungen um den Kontextknoten herum lagen. Der Zugriff auf eine solche relative Positionierung kann für die Durchquerung eines großen und komplexen Dokuments nützlich sein. Nehmen wir zum Beispiel an, dass Sie ein umfangreiches Finanzdokument als Referenz haben, das in XML programmiert ist und alle unterschiedlichen Mehrwertsteuersätze der verschiedenen Staaten in der EU einschließt. Möglicherweise gibt es für jeden Staat abgeleitete Elemente, die eine Reihe von Steuern für Benzin, Alkohol usw. einschließen. Sie können einen Lokalisierungspfad auf der Grundlage der Knotenbeziehungen verwenden, um alle abgeleiteten Steuern des jeweiligen Staats für die weitere Verarbeitung zu lokalisieren.
Sie haben gesehen, dass der XPath-Baum in Richtung der Dokumentanordnung durchquert wird, was sich auf die Knoten auswirkt, die als dem Kontextknoten vorausgehend oder nachfolgend gelten. Im nächsten Abschnitt werden Sie sehen, wie man XPath-Ausdrücke schreibt, die diese Beziehungen mit den Knotennamen kombinieren. Damit erreichen Sie eine stärkere Kontrolle über den Auswahlprozess und können spezifische Knoten lokalisieren.
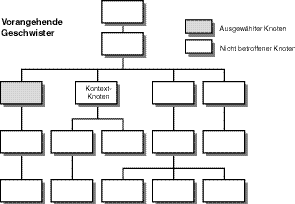
Abbildung 9.12: Ein Knotenbaum in XPath, der eine Vorangehende-Geschwister-Beziehung anzeigt
Sie haben die relative Natur von XPath, die sich in benannten Beziehungen ausdrückt, kennen gelernt und die Art und Weise, wie diese Achsen durchquert werden, um Knoten auszuwählen. In diesem Abschnitt erfahren Sie, wie man absolute Pfadausdrücke erzeugt, die bestimmte Elemente, Attribute und andere Knoten auswählen. Später werden Sie sehen, wie man dies mit einigen der zuvor beschriebenen Beziehungsachsen kombinieren kann. Lernziel für diesen Abschnitt ist es, etwas über die Syntax und eine ausgewählte Teilmenge beliebter Optionen bei XPath zu erfahren, nicht eine umfassende Liste aller möglichen Ausdruckskombinationen kennen zu lernen.
Für die Auswahl bestimmter Knoten arbeiten Sie mit einem richtigen XML-Dokument, das mehrere eingebettete Elemente hat, und durchqueren die Knoten mit den XPath- Ausdrücken, die Sie schreiben. Erzeugen Sie zunächst ein einfaches XML-Dokument. Stellen Sie sich vor, Sie öffnen Ihre Schreibtischschublade und entdecken eine Reihe von Stiften und Bleistiften verschiedener Typen. Einige der Bleistifte sind mit »H« markiert, andere mit »HB«. Sie finden auch einige Schachteln, die gerade groß genug sind, um mehrere Bleistifte aufzunehmen. Eine der Schachteln liegt auf einem Tablett. Diese Beziehungen bilden die Hierarchie des XML-Dokuments, mit abgeleiteten, Stamm-, Vorfahre- und Abkömmlingknoten. Für die Mitarbeit bei den folgenden Beispielen empfehlen wir, ein Dokument zu erzeugen, das genauso aussieht wie das Dokument in Listing 9.3, und es als schublade.xml abzuspeichern.
Listing 9.3: Der Inhalt einer Schreibtisch-Schublade - schublade.xml
1: <?xml version="1.0"?>
2: <!-- Listing 9.3 -schublade01.xml -->
3:
4: <schublade>
5: <bleistift typ="HB"/>
6: <stift/>
7: <bleistift typ="H"/>
8: <bleistift typ="HB"/>
9: <bleistift typ=" HB "/>
10: <schachtel>
11: <bleistift typ="HB"/>
12: </schachtel>
13: <tablett>
14: <schachtel>
15: <bleistift typ="H"/>
16: <bleistift typ="HB"/>
17: </schachtel>
18: </tablett>
19: <stift/>
20: </schublade>
Bleiben wir bei unserem Szenario: der Elementtyp schublade, der in Zeile 4 beginnt, enthält eine Reihe von bleistift-Elementtypen, stift-Elementtypen, schachtel- Elementtypen und einen Elementtyp tablett. In einigen Fällen ist das bleistift-Element in einem schachtel-Element enthalten. Ein schachtel-Element ist in einem tablett- Element enthalten. Die Bleistifte haben typ-Attribute mit dem Wert H oder HB.
Um die XPath-Ausdrücke zu testen, laden Sie ein XPath-Testtool aus dem Web herunter. Nach der Beschreibung auf der Website ist XPath Visualizier, Version 1.4, »ein voll entwickelter visueller XPath-Interpret für die Auswertung aller XPath-Ausdrücke und die visuelle Präsentation des resultierenden Knotensatzes oder Skalawerts«. Um den Übungen in diesem Abschnitt folgen zu können, müssen Sie den XPath Visualizer, Version 1.4, von der Website http://www.vbxml.com/xpathvisualizer/default.asp herunterladen. Sie können mit dieser Anwendung alle Übungen austesten, die in diesem Abschnitt noch kommen. Der XPath Visualizer wurde als Unterrichtstool für XPath entwickelt; man kann ihn aber auch gut verwenden, wenn man komplexe XPath-Ausdrücke für die Verwendung in XSLT oder XPointer erzeugt.
Der Visualizer ist als eine Ansammlung einfacher HTML-Seiten programmiert und verwendet ein paar JavaScript-Elemente, um die Knoten zu manipulieren, die XPath lokalisiert. Ein Cascading Stylesheet und ein XML Stylesheet sind auch eingebaut, um ausgewählte Knoten mit einem farbigen Schema anzeigen zu können. Der Microsoft Internet Explorer muss in Version 5.0 oder höher auf Ihrem System installiert sein, denn XPath Visualizer instanziert das MSXML-Objekt, das zusammen mit diesem Browser geliefert wird. Sie haben am 3. Tag etwas über die MSXML-Parser erfahren. Zum Zeitpunkt der Drucklegung dieses Buches ist die Version 4.0 die neueste Ausgabe des MSXML, die als Preview unter http://msdn.microsoft.com/downloads/ erhältlich ist. Version 2.0 ist alles was nötig ist, damit der XPath Visualizer läuft; wenn Sie also den Internet Explorer 5.0 oder höher installiert haben, brauchen Sie MSXML 4.0 nicht herunterzuladen.
Wenn Sie die Dateien für den XPath Visualizer heruntergeladen haben, platzieren Sie sie in einem eigenen Unterverzeichnis auf Ihrem Rechner. Um die Anwendung zu starten, müssen Sie mit dem Internet Explorer auf die XPathMain.htm-Datei in Ihrem XPath- Visualizer-Unterverzeichnis zeigen. Wenn die Seite geladen wird, klicken Sie auf die Schaltfläche Durchsuchen und lokalisieren Ihre Datei schublade.xml. Der Dateipfad wird im Formfeld auf der linken Seite der Schaltfläche angezeigt. Drücken Sie die Schaltfläche Process File. Das sollte zu einer neuen Anzeige im Browserfenster führen, die eine Auflistung des Dokuments schublade.xml enthält und jeden Elementknoten auf der Seite in Gelb hervorhebt. Sie werden sehen, dass abgesehen von der Farbmarkierung durch den XPath Visualizer das Dokument so aussieht, wie es normalerweise aussieht, wenn der Internet Explorer es mit XSLT für die Anzeige umwandelt. Es findet in diesem Fall die gleiche Transformation statt, mit einer Zusatz-Stilisierung, die erforderlich ist, um die ausgewählten Knoten von XPath hervorzuheben. Sie werden mehr über Transformationen erfahren, wenn Sie am 16. Tag XSLT studieren.
Wenn Sie die Schaltfläche Process File im Fenster des XPath Visualizers zum ersten Mal anklicken, gibt er den Ausdruck //* automatisch im Feld unter dem Dateinamen ein. Dieses Feld wird XPath-Ausdrucksfeld genannt. Mit diesem besonderen XPath-Ausdruck werden alle Elementknoten in einem Baum ausgewählt. Mehr zur Verwendung der Sternchen-Wildcard und über die Slash-Notation erfahren Sie später in diesem Abschnitt. Wenn die Anwendung diese XPath-Anweisung auswertet, hebt sie alle Elementknoten in der Anzeige hervor. Sie können die Ausdrücke, die im restlichen Abschnitt besprochen werden, direkt in dieses Feld eingeben, um bestimmte Knoten Ihres XML-Dokuments auszuwählen. Abbildung 9.13 zeigt das Browserfenster des Microsoft Internet Explorers, in das der XSLT-Visualizer geladen ist, der alle Elementknoten des Dokuments schublade.xml gelb hervorhebt.
In den folgenden Abschnitten lernen Sie die Syntax beliebter XPath-Ausdrücke kennen. Sie können den beschriebenen String jedes Mal in das XPath-Ausdrucksfeld der Anwendung Visualizer eingeben, um sich die ausgewählten Knoten anzusehen.
Der Slash (/) wird von XPath für einen Verweis auf den Wurzelknoten im XPath-Baum verwendet. Wenn Sie am 16. Tag anfangen, XSLT-Muster mit XPath-Ausdrücken zu erstellen, werden Sie den einfachen Slash in vielen Programmen verwenden. Heute wollen wir ihn verwenden, um auf den Wurzelknoten zu verweisen und uns durch den Baum hindurchzuarbeiten, um die gewünschten Knoten zu lokalisieren.
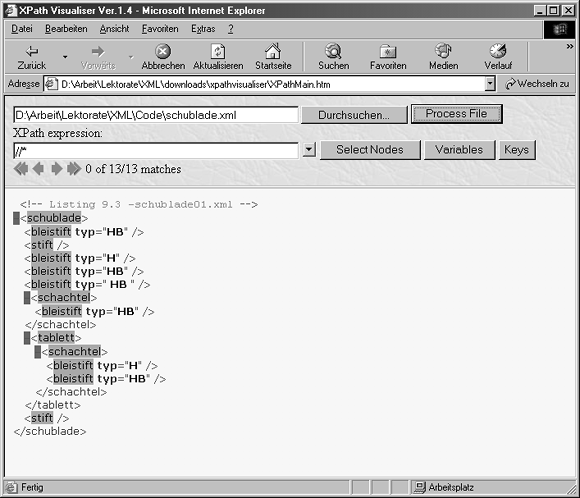
Abbildung 9.13: Der XPath Visualizer zeigt alle Elementknoten der Datei schublade.xml an.
Die grundlegende Syntax eines XPath-Ausdrucks ähnelt stark dem Adressiersystem, das verschiedene Dateisysteme verwenden. In diesem Beispiel geben Sie /schublade in das XPath-Ausdrucksfeld der Visualizer-Anwendung ein, um das Wurzelelement schublade auszuwählen. Wenn Sie den String eingegeben haben, aktivieren Sie die Schaltfläche SelectNodes der Anwendung, woraufhin nur das schublade-Element gelb hervorgehoben wird. Die Anwendung gibt auch die Anzahl der Entsprechungen an, die sie auf Grund Ihrer Eingabe findet. In diesem Fall teilt sie Ihnen mit, dass es nur einen Treffer für einen Wurzelelementknoten in der XML-Dokument-Instanz gibt. Das macht auch Sinn, denn ein XML-Dokument kann nur ein Wurzelelement haben.
Streng genommen wird der Ausdruck so interpretiert, als würde er bedeuten, dass Sie die Elementableitung schublade des Wurzelknotens auswählen. Das funktioniert, wenn Sie ein bekanntes Wurzelelement nach seinem Namen auswählen.
Zur Überprüfung geben Sie nun /stift in das XPath-Ausdrucksfeld ein und aktivieren die Schaltfläche SelectNodes. Wenn der XPath-Ausdruck ausgewertet wird, werden keine Entsprechungen gefunden; das Anzeigefeld teilt Ihnen mit, dass es null Treffer gibt und es wird kein Knoten hervorgehoben. Im nächsten Beispiel sehen Sie, welche Syntax erforderlich ist, um die stift-Knoten in dieser XML-Instanz zu lokalisieren.
Da XPath eine spezifische Beziehung oder Achse braucht, der es folgen kann, um die Knoten zu lokalisieren, müssen Sie einen Ausdruck erzeugen, der den Wurzelknoten einschließt, gefolgt vom Wurzelelement, dem wiederum das Zielelement folgt. Anders gesagt, Sie müssen /schublade/stift eingeben, wenn Sie versuchen, stift-Elemente zu lokalisieren. Versuchen Sie das und sehen Sie sich das Ergebnis an. Sie müssten zwei stift-Elemente sehen, die hervorgehoben sind, und das Anzeigefeld müsste Ihnen mitteilen, dass zwei passende Knoten ausgewählt wurden. Der Ausdruck wird so interpretiert: »Wähle alle stift-Elemente aus, die Ableitungen des Wurzelelements schublade sind.«
Versuchen Sie, mit der gleichen Syntax alle bleistift-Elemente in der Dokument-Instanz auszuwählen. Schreiben Sie den XPath-Ausdruck /schublade/bleistift. Wenn Sie diesen Ausdruck auswerten, zeigt die Anwendung an, dass vier Treffer gefunden wurden, und sie hebt die ersten vier bleistift-Elemente hervor. Die anderen beiden bleistift-Elemente in der Dokument-Instanz wurden nicht ausgewählt, weil es sich bei ihnen nicht um Ableitungen vom Wurzelelement handelt. Der Ausdruck, den Sie erstellt haben, wählt nur die abgeleiteten Elemente der Wurzel aus und nicht die Abkömmlinge dieses Wurzelelements. Sie werden in Kürze erfahren, wie man einen Ausdruck eingibt, der die Abkömmlinge zurückgibt.
Wenn Sie der gleichen Logik folgen wie vorher, müssten Sie in der Lage sein, alle bleistift-Elemente auszuwählen, die abgeleitete Elemente des schachtel-Elements sind, bei dem es sich um eine Ableitung von tablett in der Dokument-Instanz handelt. Erstellen Sie dafür einen XPath-Ausdruck, der den genauen Pfad in der Dokumentanordnung durchquert, der nötig ist, um das gewünschte Element zu erreichen. Geben Sie also / schublade/tablett/schachtel/bleistift ein und aktivieren Sie die Schaltfläche SelectNodes.
Das Resultat ist die Auswahl der beiden bleistift-Elemente, die abgeleitete Elemente des schachtel-Elements sind, das im Element tablett enthalten ist.
Angenommen, Sie müssen alle bleistift-Elemente unabhängig von ihrer Aufreihung auswählen. XPath stellt den doppelten Slash (//) zur Verfügung, um dies zu erreichen. Der Doppelslash kann wie folgt interpretiert werden: »Wähle alle Elemente aus, die einem Kriterium entsprechen, das aufgestellt wird.« Um alle bleistift-Elemente auszuwählen, geben Sie den Ausdruck //bleistift ein und werten das Ergebnis aus. XPath lokalisiert alle sieben bleistift-Elementknoten, unabhängig von ihrer Abstammung.
Sie können den Doppelslash-Operator bei einer Stamm-/Ableitungs-Beziehung einsetzen, um alle abgeleiteten Elemente eines bestimmten Stamms auszuwählen. In diesem Fall ist die Anordnung der Elemente von entscheidender Bedeutung und der Stamm muss der Ableitung im Ausdruck vorausgehen. Probieren Sie diese Syntax aus, indem Sie einen Ausdruck erzeugen, der als »Wähle alle bleistift-Elemente aus, die abgeleitete Elemente von schachtel-Elementen sind« interpretiert wird. Wenn Sie sich die XML-Dokument- Instanz ansehen, werden Sie feststellen, dass es drei solcher bleistift-Elemente gibt. Das erste befindet sich in Zeile 11 von Listing 9.3; die beiden anderen sind jeweils in den Zeilen 15 und 16.
Der XPath-Ausdruck, der diese Elemente auswählt, ist //schachtel/bleistift. Wie vorhin beschrieben heißt dies »Wähle alle bleistift-Elemente aus, die abgeleitete Elemente von schachtel-Elementen sind«.
Die Wildcard-Notation bei XPath wird mit einem Sternchen programmiert. Das Sternchen funktioniert ähnlich wie in Dateisystem-Notationen als alles einschließender Operand. Damit Sie verstehen, wie die Wildcard mit anderen Ausdrücken kombiniert werden kann, zeigt Tabelle 9.2 einige Beispiele auf der Grundlage des Dokuments schublade.xml und die jeweils zu erwartende Auswertung. Probieren Sie diese Beispiele mit dem XPath Visualizer aus und versuchen Sie dann, einige eigene Kombinationen zu erzeugen.
Tabelle 9.2: Beispiele mit Wildcards
Mit eckigen Klammern wird bei XPath eine dem Ausdruck integrale Berechnung oder Funktionsauswertung eingeschlossen. Angenommen, Sie wollen das dritte bleistift- Element lokalisieren, das eine Ableitung des Wurzelelements ist: Sie könnten dann die Notation mit eckigen Klammern verwenden, um bis zum dritten dieser Elemente zu zählen, die in der Dokumentanordnung durchquert werden. Die Syntax für diesen Ausdruck lautet:
Pfad[berechnung oder funktion]
Der XPath-Ausdruck, um das dritte abgeleitete bleistift-Element der Wurzel zu finden, würde so aussehen:
/schublade/bleistift[3]
Versuchen Sie das und probieren Sie dann aus, verschiedene numerische Werte in die eckigen Klammern einzusetzen und den Pfad vor den Klammern zu verändern.
Die Funktion last() kann in dem Ausdruck anstelle einer numerischen Zählung verwendet werden, um den letzten qualifizierten Knoten, der in der Achse programmiert ist, auszuwählen. Sie können daher /schublade/stift[last()] verwenden, um das letzte stift-Element auszuwählen, das im Wurzelelement enthalten ist.
Wenn bleistift mehrfach auftritt, wie kann man dann den letzten bleistift jedes Stamms auswählen, der bleistift-Elemente enthält? Die Lösung besteht in einer Kombination aus mehreren der Achsen-Deklarationen, die Sie bislang kennen gelernt haben. Zunächst müssen Sie eine Achse verwenden, die die Elemente unabhängig von ihrer Abstammung auswählt. Das erreichen Sie mit dem Doppelslash. Dann müssen Sie die interessierenden Elemente spezifizieren, also in diesem Fall bleistift. Schließlich müssen Sie mit der last()-Funktion nur den letzten aus jedem Satz auswählen. Wenn Sie all dies in einem String zusammenfassen, sieht der Ausdruck so aus:
//bleistift[last()],
was in der Auswahl des letzten bleistift-Elements resultiert, das in jedem Stammelement enthalten ist. Es gibt drei davon und sie treten in den Zeilen 9, 11 und 16 von Listing 9.3 auf. Versuchen Sie es selbst.
Im Dokument schublade.xml haben die bleistift-Elemente typ-Attribute. Sie können eine Reihe verschiedener Ansätze verwenden, um in XPath Attribute und Attributswerte auszuwählen, und die Funktionen und die Syntax, die Sie erlernt haben, mit Attributsauswertungen kombinieren, um die spezifizierte Auswahl einzugrenzen. Das Symbol für ein Attribut (@) wird verwendet, um den Einschluss der Logik für die Attributsauswahl bei einem XPath-Ausdruck anzuzeigen.
Um alle Attribute in der Instanz auszuwählen, können Sie den Doppelslash mit dem Attributssymbol und einer Wildcard kombinieren, also //@*. Versuchen Sie das im XPath Visualizer durchzuführen. Es sollten alle sieben Attribute im XML-Dokument zurückgegeben werden. Sie können auch bloß die Attribute auswählen, die einen vorgegebenen Namen haben, wenn Sie diesen Namen spezifizieren. Um zum Beispiel alle typ-Attribute auszuwählen, können Sie im Ausdrucksfeld //@typ eingeben. Natürlich bekommen Sie auch hier sieben Treffer, genau wie oben, als Sie alle Attribute auswählten, weil schublade.xml nur typ-Attribute enthält.
Eine weitere Funktion bei XPath ist not(), die einen ausgewählten Ausschluss von Knoten erlaubt. Wenn Sie zum Beispiel alle Elemente im Dokument schublade.xml auswählen wollen, die kein Attribut haben, können Sie folgenden XPath-Ausdruck schreiben:
//*[not(@*)]
Dieser Ausdruck wird als »Wähle alle Elemente aus, die vom Wurzelknoten abstammen und die keine Attribute einschließen« angezeigt. Im Dokument schublade.xml werden damit das Wurzelelement schublade sowie die Elemente stift, tablett und schachtel eingeschlossen.
XPath bietet eine Methode, wie man Attributswerte bei Ausdrücken als Auswahlkriterien verwendet, ähnlich dem Programmieren einer SQL where-Anweisung. Um zum Beispiel alle bleistift-Elemente auszuwählen, die ein typ-Attribut mit dem Wert "HB" haben, geben Sie //bleistift[@typ="HB"] ein. Dieser Ausdruck gibt vier Treffer zurück, wenn Sie Ihr schublade.xml-Dokument genau wie im Beispiel aus Listing 9.3 erstellt haben. Schauen Sie sich die Zeilen 8 und 9 im Listing genau an:
8: <bleistift typ="HB"/>
9: <bleistift typ=" HB "/>
Sie werden feststellen, dass die Zeilen sich unterscheiden. Der Attributswert in Zeile 9 hat Leerzeichen zwischen den Anführungszeichen und dem Wert. Deshalb gibt der XPath- Ausdruck nur vier Treffer zurück: das Attribut in Zeile 9 entspricht nicht den Auswahlkriterien. Da XPath eine so leistungsstarke Sprache ist, stellt es Ihnen eine Methode zur Verfügung, zusätzliche Leerzeichen in Attributswerten zu normieren. Der Ausdruck //bleistift[normalize-space (@typ)="HB"] gibt fünf Knoten zurück, die Attribute enthalten, weil der Normierprozess aus " HB " ein Äquivalent von "HB" macht.
Tabelle 9.3 listet Beispiele für mehrere zusätzliche Funktionen auf, die bei XPath-Ausdrücken verwendet werden können. Für jeden Fall wird ein Beispiel gezeigt, aber Sie können Elementnamen, Zahlen und Buchstaben für Ihre eigenen Ausdrücke nach Belieben verändern.
Tabelle 9.3: Zusätzliche Funktionen zur Verwendung bei XPath-Ausdrücken
Sie können mehrere XPath-Ausdrücke miteinander kombinieren, indem Sie die Strings zusammenfügen und mit einem Pipe-Zeichen, dem vertikalen Strich (|), voneinander trennen. Wenn Sie zum Beispiel alle schachtel- und alle stift-Elemente auswählen wollen, können Sie einen XPath-Ausdruck erzeugen, der so aussieht: //schachtel|//stift. Die Anzahl der Kombinationen, die Sie zusammenfügen können, ist unbegrenzt; bedenken Sie nur, dass das einen Kumuliereffekt ergibt.
Sie haben gelernt, dass Sie das Wurzelelement auswählen können, wenn Sie das abgeleitete Element (Ableitung = child) des Wurzelknotens auswählen. Die Syntax hierfür lautet:
/element_name
In Wahrheit ist das eine Kurzform für eine voll qualifizierte Version des gleichen Ausdrucks, die so aussieht:
/child::element_name
Deshalb lautet der voll qualifizierte Ausdruck, der erforderlich ist, um das Wurzelelement für die Datei schublade.xml zurückzugeben wie folgt: /child::schublade.
Die abgeleitete Achse ist die Standardachse in einem XPath-Ausdruck und es ist sicher, wenn man sie auslässt; diese Auslassung führt zur Version in Kurzform. Die voll qualifizierte Form und die Kurzform können im gleichen XPath-Ausdruck kombiniert werden, wenn man das will. So gibt /child::schublade/bleistift alle abgeleiteten bleistift-Elemente des schublade-Elements zurück, das wiederum eine Ableitung vom Wurzelknoten ist.
Die anderen benannten Beziehungen, die Sie heute kennen gelernt haben, können auch in einem XPath-Ausdruck eingeschlossen werden, indem man ihre Achsen, gefolgt von zwei Doppelpunkten, einfügt. Um alle Abkömmlinge (=descendants) des Elements tablett auszuwählen, kann man zum Beispiel einen Ausdruck eingeben, der so aussieht:
/schublade/tablett/descendant::*
Dieser Ausdruck wird als alle Abkömmlinge des Elements tablett interpretiert, das eine Ableitung des Elements schublade ist, das selbst wiederum vom Wurzelknoten abgeleitet ist.
Angenommen, Sie wollen nur diejenigen bleistift-Elemente lokalisieren, die irgendwo unter ihren Vorfahren ein tablett-Element haben, dann können Sie mit dem Ausdruck //tablett/descendant::bleistift alle Abkömmlinge von tablett lokalisieren, die bleistift heißen.
Wenn der Kontextknoten einen Stamm (=parent) hat, residiert dieser in der Stammachse. Der Ausdruck //schachtel/parent::* lokalisiert die Stammknoten aller schachtel- Elemente.
Sie erinnern sich sicher, dass die Nachfolger-Geschwister-Beziehung (=following-sibling) gleichrangige Verwandte des Kontextknotens zurückgab. Daher lokalisiert //schachtel/ following-sibling::* das Element tablett und das nächste stift-Element in der Dokumentanordnung; dies sind die nächsten gleichrangigen Verwandten von schachtel in der Dokumentanordnung. Vergleichen Sie diesen Ausdruck mit //schachtel/ following::*, was alle Knoten zurückgibt, die in der Dokumentanordnung auf den Kontextknoten (schachtel) folgen.
Es gibt viele weitere Möglichkeiten bei Ausdrücken, einige davon sind recht komplex. Der
Ausdruck
//bleistift[position()=floor(last()div 2 + 0.5)]
oder
//bleistift[position()=ceiling(last()div 2 + 0.5)]
lokalisiert nur die mittleren bleistift-Elemente in der Dokument-Instanz. Das sprengt den
Rahmen unserer heutigen Untersuchungen, aber Sie werden in den folgenden Tagen mehr
darüber erfahren.
Dieses Kapitel hat Sie mit einigen grundlegenden Konzepten der XML Path Language bekannt gemacht. XPath ist eine Sprache, die auf der Grundlage von Ausdrücken beruht, kein Dialekt von XML, und sie wurde so gestaltet, dass sie knapp und effektiv ist. Man verwendet XPath, um Teile eines XML-Dokuments anzusteuern, die man Knoten nennt. Sie werden mehr über XPath erfahren, wenn Sie die Technologien untersuchen, die es unterstützen soll, vor allem XPointer und XSLT. Sie werden von XPointer am 11. und von XSLT am 16. Tag hören. Heute haben Sie die sieben Knoten kennen gelernt, die den XPath-Baum ausmachen: Wurzel, Element, Attribut, Namensraum, Verarbeitungsanweisung, Text und Kommentar. Sie haben gesehen, dass alle Knoten dem Wurzelknoten untergeordnet sind, und Sie haben erfahren, dass der Wurzelknoten etwas anderes ist als das Wurzelelement in einer XML-Dokument-Instanz. Sie haben elf benannte Knotenbeziehungen kennen gelernt, mit denen man in XPath Knoten und Knotensätze auswählt. Dann haben Sie XPath-Ausdrücke erzeugt und getestet, mit denen Elemente und Attribute in zahlreichen Kombinationen ausgewählt wurden, und außerdem haben Sie Funktionen und Auswertungsmuster verwendet.
Frage:
Was ist die Natur des Datenobjekts, das aus XPath-Ausdrücken resultiert?
Antwort:
Wenn XPath-Ausdrücke ausgewertet werden, resultieren sie in einem der
folgenden Datenobjekte:
Frage:
Welche Knotentypen können mit XPath lokalisiert werden?
Antwort:
XPath kennt die folgenden sieben Knotentypen: Wurzel, Element, Attribut,
Kommentar, Text, Verarbeitungsanweisung und Namensraum.
Frage:
In welchem Bezug steht das Konzept der Dokumentanordnung zu XPath?
Antwort:
XPath-Ausdrücke veranlassen einen Prozessor, den Knotenbaum in der Richtung
zu durchqueren, in der sich die Knoten eines Dokuments befinden. Aus diesem
Grund haben Beziehungsachsen wie vorangehende und nachfolgende bei XPath
eine Bedeutung, weil sie sich auf den Kontextknoten oder Ausgangspunkt der
Durchquerung beziehen. Vorangehende Knoten sind diejenigen, die in der durch
die Dokumentstruktur vorgeschriebenen Reihenfolge vor dem Kontextknoten
kommen. Die nachfolgenden Knoten kommen folgerichtig in der
Dokumentanordnung nach dem Kontextknoten.
Verarbeiten Sie Ihre Datei cd.xml mit dem XPath Visualizer und erzeugen Sie Ausdrücke, um die folgenden Knotenresultate auszuwählen:
