




Sie haben gelernt, dass ein XML-Dokument gültig ist, wenn ihm ein Schema zugeordnet wurde und wenn das Dokument die Beschränkungen, die in diesem Schema ausgedrückt sind, befolgt. Heute werden Sie den Schematyp Document Type Definition oder DTD kennen lernen.
Sie erinnern sich, dass die Zuordnung eines Schemas zu einem XML-Dokument bedeutet, dass das Dokument unabhängig von der Anwendung zur gemeinsamen Benutzung freigegeben wird. Das Schema fügt dem XML-Dokument Beschränkungen hinzu, die den Einschluss der erforderlichen Elemente und Attribute, ihre spezifische Reihenfolge und bis zu einem gewissen Grad ihren gültigen Inhalt sicherstellen. Wenn diese Beschränkungen vorgegeben sind, können Sie Ihre Daten mit Anderen austauschen und ein gemeinsames Schema für die Validierung nutzen. Sie werden sehen, dass das Schema in eine Anwendung eingebaut werden kann, um ein XML-Dokument zu validieren, das für die Bereitstellung von Daten zu anderen Zwecken genutzt wird. Ein Parser ist eine solche Anwendung. Ein Parser validiert ein XML-Dokument, indem er feststellt, dass es wohl geformt ist, und dann die Beschränkungen austestet, die in einem zugeordneten externen (oder internen) Schema vorgegeben sind.
Die DTD ist eine Schemaform, die ihren Ursprung im SGML-Universum hat. Zunächst war XML als eine Art SGML ohne DTDs gedacht. In gewisser Hinsicht trifft dies auch zu, weil man sicherlich wohl geformtes XML schreiben kann, ohne ein Schema zuzuordnen, aber wie Sie bereits wissen, ist das Schema (die DTD) ein machtvolles Mittel, um dem Datenaustausch auf der Grundlage durchgängiger Datenstrukturen wertvolle Beschränkungen hinzuzufügen. Man kann XML ohne eine DTD oder ein Schema schreiben; dann handelt es sich um wohl geformtes XML, aber durch Schemata wird dem Dokumentinhalt und den Betriebsregeln die Gültigkeit hinzugefügt.
![]()
Eine DTD (oder ein anderes XML-Schema) liefert eine Schablone für die Dokumentauszeichnung, die die Präsenz, die Anordnung und die Platzierung von Elementen und ihren Attributen in einem XML-Dokument anzeigt.
Sie haben bereits gelernt, dass ein XML-Dokument als Baum von Elementen angezeigt werden kann, welche Daten, andere Elemente und Attribute enthalten. Man kann sich eine DTD als Struktur vorstellen, die auch einen Baum definiert, aber es gibt einige Unterschiede zwischen einem DTD-Baum und einem XML-Dokumentbaum, auch wenn das XML-Dokument mit der DTD übereinstimmt.
Ein DTD-Baum hat selbst keine Wiederholung von Elementen oder in der Struktur. Seine Strukturen sind aber für die Wiederholung von Elementen in einer konformen und gültigen XML-Instanz geeignet. Betrachten Sie das XML-Dokument in Listing 4.1 (ein ähnliches haben Sie am dritten Tag gesehen).
Listing 4.1: Eine Kursankündigung als wohl geformte XML-Instanz - kurse.xml
1: <?xml version="1.0"?>
2: <!-- listing 4.1 - kurse.xml -->
3:
4: <ankuendigung>
5: <verteiler>Zur sofortigen Veroeffentlichung</verteiler>
6: <an>Alle potenziellen Studenten</an>
7: <von>Devan Shepherd</von>
8: <thema>Oeffentliches Kursangebot im August</thema>
9: <notiz>ACME-Training freut sich, folgende oeffentlichen
10: Kurse anbieten zu koennen, die monatlich in seinem
11: Hauptquartier stattfinden.</notiz>
12: <mehr_info>Weitere Informationen und Einschreibung zu diesen
Kursen unter
13: <website>http://ACMETrain.com/university</website></mehr_info>
14: <kurse>
15: <kurs id="XML111" dozent="Bob Gonzales">XML fuer
Anfaenger</kurs>
16: <kurs id="XML333" dozent="Devan Shepherd">XML fuer
Fortgeschrittene</kurs>
17: <kurs id="XMT222" dozent="Gene Yong">XMetal Core-
Konfiguration</kurs>
18: </kurse>
19: </ankuendigung>
In Zeile 14 findet sich das Element kurse, das weitere kurs-Elemente enthält. Angesichts dessen könnte ein Diagramm zum Dokumentbaum, der diese Instanz anzeigt, wie das in Abbildung 4.1 aussehen.
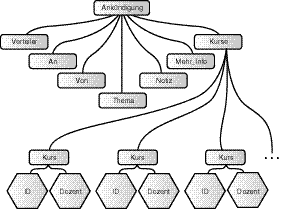
Abbildung 4.1: Dokumentbaum für das Dokument zur Presseankündigung kurse.xml
Der Dokumentbaum in Abbildung 4.1 zeigt mehrere kurs-Elemente, von denen jedes ein id- und ein dozent-Attribut hat. Ein DTD-Baum würde das kurs-Element nur einmal auflisten, aber einen speziellen +-Operator einschließen, der anzeigt, dass mehr als ein Element zulässig ist. Sie werden zu dem Pluszeichen und anderen besonderen DTD- Operatoren später mehr erfahren. Abbildung 4.2 zeigt einen zulässigen DTD-Baum für das Dokument kurse.xml.
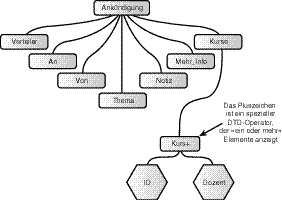
Abbildung 4.2: Ein DTD-Baum für das Dokument zur Presseankündigung kurse.xml
Sie werden heute lernen, wie man einfache DTDs erstellt und liest. Es gibt Tools, die bei diesem Prozess hilfreich sind, einschließlich einiger, die ein oder mehrere wohl geformte XML-Dokumente abfragen und DTDs generieren, die diese Dokumente validieren. (Sie finden etwa unter http://www.pault.com/pault/dtdgenerator/ ein Online-Programm, das dieses tut. Wenn Sie einen DTD-Generator lieber lokal einsetzen, können Sie die freigegebenen Tools von SAXON unter http://users.iclway.co.uk/mhkay/saxon/ herunterladen.)
Aber zunächst sollten wir betrachten, wie man einfache DTDs manuell programmiert.
DTDs behandeln die Elemente in einem XML-Dokument entweder als Containerelemente oder als leere Elemente (also als Platzhalter in der Dokumentstruktur). Die Containerelemente können Daten (etwa Text), abgeleitete Elemente oder eine Kombination aus beiden beherbergen. Die DTD stellt die Syntax für die Beschränkungen bereit, die diese Inhaltsmodelle steuert.
![]()
Die Deklaration von Element- oder Attributsinhalten in einer DTD wird »das Inhaltsmodell« für ein bestimmtes Element oder Attribut genannt.
Die Elemente in einem XML-Dokument sind die fundamentalen Strukturen, die zusammengesetzt werden, um eine Instanz zu erzeugen. Jedes Element in einer DTD muss mit einer Elementtyp-Deklaration deklariert werden.
Elementtyp-Deklarationen haben folgende Form:
<!ELEMENT name ( Inhaltsmodell )>
![]()
Die folgenden Beispiele bauen aufeinander auf. Sie sollten sie jeweils erzeugen, wenn wir sie im Buch vorstellen, indem Sie den entsprechenden Code für jedes Listing mit einem Texteditor schreiben oder von der CD laden. Später an diesem Tag werden Sie einige dieser Beispiele parsen, um nachzuweisen, dass sie gültiges XML darstellen. Speichern Sie jede neue Version Ihres Dokuments als eigene Datei ab und nennen diese nachricht01.xml, nachricht02.xml usw.
Betrachten Sie das kurze XML-Dokument in Listing 4.2 als Beispiel für ein einfaches Element. Es handelt sich dabei wirklich um ein sehr einfaches XML-Dokument, das nur ein einziges Element umfasst, notiz. Erstellen Sie dieses Dokument und speichern Sie es unter nachricht01.xml ab.
Listing 4.2: Eine kurze, wohl geformte XML-Instanz - nachricht01.xml
1: <?xml version = "1.0"?>
2: <notiz>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen</notiz>
Das Element notiz enthält nur Text, nichts weiter. Sie könnten dieses Dokument validieren, indem Sie eine DTD mit einer Elementtyp-Deklaration erzeugen, die festlegt, dass notiz nur #PCDATA enthält, ein von der DTD reserviertes Schlüsselwort für »Parsed Character Data« (ausgewertete Zeichendaten) oder Text. PCDATA sind reine Textdaten, aber es handelt sich dabei um Textdaten, die von einem XML-Parser gelesen und entsprechend verarbeitet werden. Deshalb beeinflussen Auszeichnungen in PCDATA das Parsen des Dokuments. Das kann ein erwünschter oder auch ein unerwünschter Effekt sein. Sie werden später erfahren, wie man verhindert, dass Text von einem Parser interpretiert wird, indem man einen CDATA genannten Datentyp verwendet. CDATA ist reiner Text, aber einer, den der Parser nicht zu verarbeiten versucht; Zeichen für die Auszeichnung, wie etwa spitze Klammern, werden in CDATA-Abschnitten ignoriert, in PCDATA-Segmenten dagegen aufgelöst.
Da DTDs eine Methode anbieten, die Struktur von Dokumenten zu validieren, enthalten sie die Regeln für den Inhalt. Jedem Element oder Attribut ist in einer DTD ein Inhaltsmodell zugeordnet, das den Inhalt deklariert und definiert. Ein Element kann beispielsweise Textdaten oder andere Elemente enthalten oder es kann leer sein. All diese Inhaltsmodelle werden in einer DTD unterschiedlich programmiert. DTDs können in getrennten Dokumenten bereitgestellt werden und durch eine spezielle Anweisung dem Dokument der XML-Instanz zugeordnet werden oder sie können als Inline-Kodierung eingeschlossen werden. Heute lernen Sie zunächst die Inline-Form kennen, anschließend dann den externen Ansatz.
![]()
Das für die DTD reservierte Schlüsselwort #PCDATA wird immer in Großbuchstaben geschrieben.
Listing 4.3 zeigt das XML-Dokument mit einer eingebetteten DTD. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht02.xml. Zeile 3 ist die Elementtyp- Deklaration und wird noch ausführlich erklärt.
Listing 4.3: Eine kurze, wohl geformte und gültige XML-Instanz - nachricht02.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( #PCDATA)>
4: ]>
5: <notiz>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen</notiz>
![]()
Zeile 1 ist die Standard-Deklaration für XML, von der Arbeitdie Sie in allen anderen Übungen auch verwendet haben. Sie deklariert, dass es sich um ein XML-Dokument der Version 1.0 handelt - also nichts Neues in dieser Zeile.
Zeile 2 ist eine spezielle Dokumenttyp-Deklaration, die im Prolog eines XML-Dokuments platziert wird und die DTD dem XML-Dokument zuweist. Sie werden noch lernen, wie man die Document Type Definition verwendet, um entweder eine Inline-DTD (interne Untermenge genannt) anzuzeigen, oder eine, die in einem eigenen externen DTD-Dokument gespeichert ist (externe Untermenge genannt). Die Syntax der beiden Ansätze ist etwas unterschiedlich und wird heute im Detail vorgestellt. Die Dokumenttyp-Deklaration beginnt immer mit <!DOCTYPE und endet mit einem >-Symbol. Das Wort DOCTYPE muss großgeschrieben sein. Die ersten Zeilen in einem XML-Dokument vor der Zeile, die das Wurzel-Element enthält, werden häufig als Prolog des Dokuments bezeichnet. Der Prolog enthält die Verarbeitungsanweisungen für das Dokument wie die XML-Deklaration (<?xml version="1.0"?>) und eine DOCTYPE-Deklaration, wenn eine DTD verwendet wird. Am 5. und 6. Tag werden Sie sehen, dass es noch weitere Arten von Schemata bei XML-Dokument-Instanzen gibt, die andere Informationen im Prolog oder Attribute im Start-Tag eines Wurzel-Elements verwenden.
Die Dokumenttyp-Deklaration in Zeile 2 teilt dem XML-Prozessor (etwa einem validierenden Parser) mit, dass eine Deklaration namens notiz existiert und alles innerhalb der eckigen Klammern ([]) zur Inline-DTD gehört. Anders gesagt, Zeile 2 beginnt mit der internen DTD-Untermenge namens notiz. In diesem Fall ist notiz das Wurzel-Element.
Zeile 3 liefert die Elementtyp-Deklaration für das Element notiz. Insbesondere wird hier deklariert, dass notiz ein Element ist, das nur Text enthält, oder auch #PCDATA. Der Teil der Deklaration, der in Klammern eingeschlossen ist, ist das Inhaltsmodell oder die Spezifikation für den Inhalt. Im Inhaltsmodell teilen Sie dem XML-Parser mit, was er als Inhalt für alle XML-Elemente in Ihrem Dokument zu erwarten hat. Manchmal werden Sie deklarieren, dass ein Element leer ist. In anderen Fällen werden Sie ein Container-Element deklarieren, das andere Elemente enthält. Einige Elemente enthalten Daten, wieder andere haben einen gemischten Inhalt und schließen Text und andere Elemente ein. Beispiele für alle Arten von Inhaltsmodellen folgen.
Zeile 4 markiert den Abschluss der Inline-DTD und teilt dem XML-Prozessor mit, dass das XML-Dokument folgt.
Zeile 5 enthält das Element notiz mit seinem Textinhalt (#PCDATA).
![]()
Die DTD-Schlüsselwörter DOCTYPE und ELEMENT müssen großgeschrieben werden.
Elemente können Container für andere Elemente sein. Das Wurzel-Element eines XML- Dokuments ist normalerweise ein solches Element. Listing 4.4 zeigt das Element notiz mit einem Element nachricht als Inhalt. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht03.xml.
Listing 4.4: Ein Element mit nur einem abgeleiteten Element - nachricht03.xml
1: <?xml version = "1.0"?>
2: <notiz>
3: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen </nachricht>
4: </notiz>
Diesmal müssen Sie, um eine DTD für dieses XML-Dokument zu erzeugen, angeben, dass das Element notiz einen Elementinhalt hat, nämlich nachricht, und nicht #PCDATA ist. Anschließend müssen Sie allerdings deklarieren, dass das nachricht-Element #PCDATA- Inhalt hat, weil alle Elemente in der Instanz deklariert werden müssen - das ist ein Teil der Bedingungen, die Ihre DTD erzwingt. Listing 4.5 zeigt das vollständige XML-Dokument mit einer internen Untermenge oder Inline-DTD. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht04.xml.
Listing 4.5: Eine DTD-Deklaration für ein Element, das ein abgeleitetes Element enthält - nachricht04.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht )>
4: <!ELEMENT nachricht ( #PCDATA)>
5: ]>
6: <notiz>
7: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen</nachricht>
8: </notiz>
![]()
In Zeile 3 wird deklariert, dass das Element notiz ein nachricht-Element enthält. Zeile 4 deklariert, dass das nachricht-Element #PCDATA enthält. Zeilen 6-8 bilden die wohl geformte und gültige XML-Instanz. Wie in Zeile 7 zu sehen ist, ist das Element nachricht korrekt in das Element notiz eingebettet (das heißt nachricht ist eine Ableitung des notiz-Elements.) Das Einrücken oder der Tab-Leerraum im Element nachricht wird nur der Klarheit halber eingefügt. Das Einrücken des Codes ist guter Programmierstil, der das Lesen des Codes vereinfacht. Das Arbeiten mit solchen Leerräumen ist in XML nicht obligatorisch. Später werden Sie sehen, wie XML-Prozessoren mit zusätzlichen Leerraum-Zeichen umgehen.
Leere Elemente werden normalerweise als Platzhalter verwendet oder auch, um obligatorische Attributswerte bereitzustellen, die andere Elemente nicht korrekt modifizieren. Später werden Sie mehr über Attributs-Deklarationen in DTDs erfahren. In Zeile 3 von Listing 4.6 wurde dem XML-Dokument das leere Element anzahl hinzugefügt. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht05.xml.
Listing 4.6: Ein leeres Element in einem XML-Dokument - nachricht05.xml
1: <?xml version = "1.0"?>
2: <notiz>
3: <anzahl />
4: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen </nachricht>
5: </notiz>
Listing 4.7 zeigt die interne DTD-Untermenge, die das neue leere Element korrekt deklariert. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht06.xml.
Listing 4.7: Eine DTD, die ein leeres anzahl-Element deklariert - nachricht06.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( anzahl, nachricht )>
4: <!ELEMENT anzahl EMPTY>
5: <!ELEMENT nachricht ( #PCDATA)>
6: ]>
7: <notiz>
8: <anzahl />
9: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen</nachricht>
10: </notiz>
![]()
Zeile 3 zeigt an, dass das Element notiz jetzt ein anzahl-Element enthält, dem ein nachricht-Element folgt. Das Komma (,) zwischen den Elementen im Inhaltsmodell weist darauf hin, dass dem Element ein weiteres Element folgt und zwar in der deklarierten Reihenfolge. Der XML-Prozessor interpretiert Zeile 3 so, dass das Element notiz ein anzahl-Element enthält, dem unmittelbar das Element nachricht folgt, in der angegebenen Reihenfolge. Eine XML-Instanz mit dem Element nachricht, das dem anzahl-Element vorausgeht, wäre nach dieser DTD nicht gültig.
Zeile 4 verwendet das Schlüsselwort EMPTY (leer) im Inhaltsmodell für das Element anzahl, um zu deklarieren, dass es sich um ein leeres Element handelt. Laut DTD kann anzahl weder Text noch andere Elemente enthalten.
![]()
Das Schlüsselwort EMPTY in der DTD wird immer großgeschrieben.
Manchmal weiß man vielleicht, dass ein bestimmtes Element nicht leer ist (das heißt Elemente, Text oder beides enthält), aber man ist sich nicht sicher, was das genaue Inhaltsmodell ist. Das DTD-Schlüsselwort ANY kann verwendet werden, um den Inhalt für Elemente zu deklarieren, die so charakterisiert sind. Um zu verstehen, wie ANY die Definition einer XML-Struktur beeinflusst, fügen Sie Elementinhalt hinzu, der die Struktur komplexer macht. Dann programmieren Sie das Inhaltsmodell mit dem Schlüsselwort ANY und entfernen so die Beschränkungen zu diesem Modell.
Betrachten Sie die XML-Instanz in Listing 4.8, in der das abgeleitete Element datum zum Container-Element notiz hinzugefügt wurde. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht07.xml.
Listing 4.8: Dem notiz-Element wird eine weitere Ableitung hinzugefügt - nachricht07.xml
1: <?xml version = "1.0"?>
2: <notiz>
3: <anzahl />
4: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch einzukaufen</nachricht>
5: <datum />
6: </notiz>
Sie könnten die Deklaration des Elements notiz in Zeile 3 von Listing 4.7 erweitern, sodass sie das neue Element datum einschließt. Das würde dann so aussehen:
3:<!ELEMENT notiz ( anzahl, nachricht, datum )>
Da dies aber keine sehr präzise Angabe ist, die in Hinsicht auf die Gültigkeit wenig bringt, könnten Sie auch das Schlüsselwort ANY verwenden, um anzuzeigen, dass das Element notiz einen beliebigen Inhaltstyp enthalten kann, einschließlich Text oder andere Elemente, ohne Rücksicht auf ihren jeweiligen Namen oder ihre Anordnung. Listing 4.9 zeigt die DTD mit einer solchen Deklaration. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht08.xml.
Listing 4.9: Für das Element notiz ist ANY-Inhalt erlaubt - nachricht08.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ANY>
4: <!ELEMENT anzahl EMPTY>
5: <!ELEMENT nachricht ( #PCDATA)>
6: <!ELEMENT datum EMPTY>
7: ]>
8: <notiz>
9: <anzahl />
10: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen</nachricht>
11: <datum />
12: </notiz>
Zeile 3 liefert die ANY-Deklaration für das Element notiz. Damit das Dokument gültig wird, muss jedoch Zeile 6 hinzugefügt werden, in welcher der EMPTY-Inhalt für das Element datum deklariert wird. Ohne Zeile 6 wäre das XML-Dokument nicht gültig. Zeile 4 liefert die gleichen Beschränkungen für das Element anzahl. Es dürfen in Ihrer XML-Instanz keine Elemente vorkommen, die nicht in der DTD deklariert wurden.
![]()
Das DTD-Schlüsselwort ANY wird immer mit Großbuchstaben geschrieben.
Es kann vorkommen, dass Sie eine Regel aufstellen wollen, die einem Element erlaubt, Text oder andere Elemente in Kombination zu enthalten. Ein gemischtes Inhaltsmodell bietet diese Möglichkeit. Listing 4.10 zeigt eine XML-Instanz mit #PCDATA im Wurzel- Element und den abgeleiteten Elementen, die Sie vorher erstellt haben. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht09.xml.
Listing 4.10: Gemischter Inhalt im Element notiz - nachricht09.xml
1: <?xml version = "1.0"?>
2: <notiz>Dies ist eine wichtige Notiz
3: <anzahl />
4: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen </nachricht>
5: <datum />
6: </notiz>
Das Wurzel-Element in Zeile 2, notiz, enthält den Textstring Dies ist eine wichtige Notiz. Listing 4.11 zeigt eine DTD, die diese Instanz validiert. Erzeugen Sie dieses Dokument und speichern Sie es unter nachricht10.xml.
Listing 4.11: Validierung eines Elements mit einem gemischten Inhaltsmodell - nachricht10.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( #PCDATA | anzahl | nachricht | datum )*>
4: <!ELEMENT anzahl EMPTY>
5: <!ELEMENT nachricht ( #PCDATA )>
6: <!ELEMENT datum EMPTY>
7: ]>
8: <notiz>Dies ist eine wichtige Notiz
9: <anzahl />
10: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen</nachricht>
11: <datum />
12: </notiz>
![]()
In Zeile 3 wird der gemischte Inhalt, der dem Element notiz zugeordnet ist, deklariert. Ein XML-Prozessor würde diese Zeile so interpretieren, dass sie anzeigt, dass das Element notiz eine beliebige Kombination aus Text und den aufgelisteten Elementen enthalten kann. Das ist wirklich eine reichlich komplexe Aussage. Das Zeichen Pipe (|) bedeutet in der DTD-Sprache »oder«. Die Spezifikation zum Inhalt besagt, dass das Element notiz #PCDATA oder anzahl oder nachricht oder datum enthalten kann. Das Sternzeichen (*) am Ende der Inhaltsspezifikation bedeutet, dass die Punkte, die in Klammern stehen, beliebig oft oder überhaupt nicht verwendet werden können. Daher ist unter Verwendung der gleichen DTD auch das XML-Dokument in Listing 4.12 gültig.
Listing 4.12: Eine weitere gültige XML-Instanz, die das gleiche gemischte Inhaltsmodell für das Element notiz verwendet - nachricht11.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz (#PCDATA | anzahl | nachricht | datum)*>
4: <!ELEMENT anzahl EMPTY>
5: <!ELEMENT nachricht ( #PCDATA)>
6: <!ELEMENT datum EMPTY>
7: ]>
8: <notiz>Dies ist eine wichtige Notiz
9: <anzahl />jetzt koennen wir das Vorkommen aller Inhaltstypen
nicht mehr kontrollieren
10: <anzahl />
11: <nachricht>sachen</nachricht>an die man denken soll
12: <nachricht>Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen</nachricht>
13: </notiz>
Wenn Sie die Unterschiede zwischen den Listings 4.11 und 4.12 betrachten, werden Sie feststellen, dass beide die gleiche interne Untermenge oder Inline-DTD enthalten. Aber Listing 4.12 hat kein Element datum; das Dokument wird dennoch als gültig betrachtet, weil das gemischte Inhaltsmodell und der (*)-Operator alle Kombinationen zulassen. Zeile 10 zeigt ein zweites leeres anzahl- und Zeile 11 ein neues nachricht-Element, beide sind durch das gemischte Inhaltsmodell zugelassen. Text (#PCDATA) kommt an verschiedenen Stellen innerhalb des Elements notiz vor (Zeilen 8, 9,11 und 12).
Verwendet man das gemischte Inhaltsmodell, geht viel an Kontrolle über die deklarierte Struktur des Dokuments verloren. Dennoch müssen Sie gelegentlich gemischte Inhaltsmodelle verwenden, aber wenn möglich, sollten Sie sie für den Fall vermeiden, dass das Geschäftsproblem, das zu lösen ist, eine genaue Kontrolle der Datenstruktur Ihres Dokuments erfordert.
Bis jetzt haben Sie gelernt, eine DTD zu verwenden, um verschiedene Inhaltstypen für ein Element zu deklarieren. Tabelle 4.1 fasst diese Inhaltsspezifikationen zusammen und zeigt die Syntax an, die jeweils verwendet wird.
Dieses Element enthält eine Kombination aus Text und untergeordneten Elementen. | ||
Dieses Element kann entweder Text oder Elementinhalt enthalten. |
Tabelle 4.1: DTD-Inhaltsspezifikationen für Elemente
Angenommen, Sie beschließen, dass die leeren Elemente anzahl und datum als Attribute für das Element nachricht sinnvoller einzusetzen sind, weil sie dieses Element modifizieren. Sie erinnern sich, dass Attribute Elemente modifizieren, ähnlich wie Adjektive dies mit Nomina tun. Das nächste Beispiel nimmt die leeren Elemente anzahl und datum aus den Listings 4.8 und 4.9 und wandelt sie in Attribute für das Element nachricht um. Listing 4.13 zeigt dies.
Listing 4.13: Eine XML-Instanz mit Attributen - nachricht12.xml
1: <?xml version = "1.0"?>
2: <notiz>
3: <nachricht anzahl="10" datum="073001">
4: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
5: </nachricht>
6: </notiz>
Zeile 3 enthält jetzt anzahl und datum als Attribute für das Element nachricht. Die DTD benötigt einen besonderen Mechanismus für die Attributs-Deklaration. Das Schlüsselwort ATTLIST wird für diesen Zweck verwendet.
Attributs-Deklarationen haben folgende Form:
<!ATTLIST -Element_name -Attribut_name1 (typ) vorgabe
-Attribut_name2 (typ) vorgabe>
Es gibt drei grundlegende Typen von Attributen, die innerhalb einer DTD deklariert werden. Dies sind:
Standard-Attribute werden deklariert, um Dokumentautoren die Kontrolle über gültige Attributswerte zu erlauben. Sie werden später Beispiele für diese Standard-Deklarationen sehen. Die drei Standardtypen, die von DTDs implementiert werden, sehen Sie in Tabelle 4.2.
Tabelle 4.2: DTD-Standard-Attribute
Das nachfolgende Listing zeigt eine DTD, die die XML-Instanz aus Listing 4.13 validiert.
Listing 4.14: Eine DTD mit einer einfachen ATTLIST-Deklaration - nachricht13.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht ) >
4: <!ELEMENT nachricht ( #PCDATA)>
5: <!ATTLIST nachricht
6: anzahl CDATA #REQUIRED
7: datum CDATA #REQUIRED>
8: ]>
9: <notiz>
10: <nachricht anzahl="10" datum="073001">
11: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
12: </nachricht>
13: </notiz>
![]()
In Zeile 5 wird deklariert, dass das Element nachricht ein Attribut anzahl und ein Attribut datum erfordert. Beide Attribute sind vom Typ CDATA, der erlaubt, dass als Daten ein beliebiger String eingefügt wird. Das Schlüsselwort CDATA erlaubt den Einschluss beliebiger Zeichen in den String, außer <, >, & oder ». Das Schlüsselwort #REQUIRED zeigt an, dass die Attribute anzahl und datum für das nachricht-Element bereitgestellt werden müssen.
Zeile 10 weist dem Attribut anzahl den Wert "10" und dem Attribut datum den Wert "073001" zu, die beide das Element nachricht modifizieren.
Listing 4.15 zeigt das neue Attribut von mit dem Wert "Kathy Shepherd". Wenn man das Schlüsselwort #FIXED verwendet, kann man sicherstellen, dass der Attributswert dem erwarteten entspricht. Zur Übung werden Sie jetzt sicherstellen, dass alle nachrichten von Kathy Shepherd sind.
Listing 4.15: Ein neues Attribut, von, wird eingeführt, um das Element nachricht zu modifizieren - nachricht14.xml
1: <?xml version = "1.0"?>
2: <notiz>
3: <nachricht anzahl="10" datum="073001" von="Kathy Shepherd">
4: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
5: </nachricht>
6: </notiz>
Die DTD, die den festgesetzten Attributswert deklariert, wird in Listing 4.16 gezeigt.
Listing 4.16: Eine gültige XML-Instanz mit einem Attributswert #FIXED - nachricht15.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht ) >
4: <!ELEMENT nachricht ( #PCDATA)>
5: <!ATTLIST nachricht
6: anzahl CDATA #REQUIRED
7: datum CDATA #REQUIRED
8: von CDATA #FIXED "Kathy Shepherd">
9: ]>
10: <notiz>
11: <nachricht anzahl="10" datum="073001" von="Kathy Shepherd">
12: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
13: </nachricht>
14: </notiz>
In Zeile 8 wird deklariert, dass das Attribut von den Wert Kathy Shepherd enthalten muss und nichts weiter. Würde Zeile 11 etwa so aussehen:
11: <nachricht anzahl="10" datum="073001" von="jemand anders">,
würde das Dokument vom XML-Prozessor als fehlerhaft angesehen und eine Fehlermeldung würde generiert werden, die anzeigt, dass es nicht gültig ist.
Listing 4.17 zeigt ein #IMPLIED-Attribut. Attribute, die impliziert sind, sind optional und die Gültigkeit wird von ihrer Präsenz oder Absenz nicht beeinflusst.
Listing 4.17: Ein gültiges Dokument mit einem #IMPLIED-Attribut - nachricht16.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht ) >
4: <!ELEMENT nachricht ( #PCDATA)>
5: <!ATTLIST nachricht
6: anzahl CDATA #REQUIRED
7: datum CDATA #REQUIRED
8: von CDATA #FIXED "Kathy Shepherd"
9: status CDATA #IMPLIED>
10: ]>
11: <notiz>
12: <nachricht anzahl="10" datum="073001" von="Kathy Shepherd">
13: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
14: </nachricht>
15: </notiz>
Zeile 9 deklariert ein #IMPLIED-Attribut, status, für dieses Dokument. Da es impliziert oder optional ist, ist die Dokument-Instanz gültig, ohne dass das Attribut in das nachricht- Element eingeschlossen wird. Wenn Zeile 12 ein status-Attribut einschlösse, wie
12: <nachricht anzahl="10" datum="073001" von="Kathy Shepherd" status="dringend">,
wäre die Dokument-Instanz immer noch gültig.
Mit Token-Attributen können Sie bestimmte Beschränkungen für Attributswerte auferlegen, aber diese Beschränkungen sind begrenzt, wie Sie sehen werden. Die Token-Optionen bieten eine Methode, die für Attribute erlaubten Werte einzuschränken. So wollen Sie vielleicht für jedes Element eine eindeutige ID haben oder einem Attribut nur gestatten, ein oder zwei verschiedene Werte zu haben. Tabelle 4.3 listet die vier verschiedenen Token- Attributstypen auf, die bei DTDs zur Verfügung stehen.
Der Wert besteht aus Buchstaben, Ziffern, Punkten, Unterstrichen, Bindestrichen und Doppelpunkten, aber keinen Leerzeichen. |
Tabelle 4.3: Token-Attributstypen bei DTDs
Listing 4.18 zeigt ein Beispiel für eine XML-Instanz, die mit den Attributstypen ID und IDREF validiert werden könnte. In diesem Beispiel wurde das XML-Dokument notiz erweitert, sodass es verschiedene neue nachricht-Elemente mit qualifizierenden Attributen aufnimmt, die sicherstellen, dass jedes Element eindeutig durch ein anzahl-Attribut und durch ergebnis-Elemente identifiziert wird, die den Notizen durch das Attribut nchr zugeordnet werden. Die XML-Instanz ist wohl geformt.
Listing 4.18: Das erweiterte XML-Dokument notiz - nachricht17.xml
1: <?xml version = "1.0"?>
2: <notiz>
3: <nachricht anzahl="a1" von="Kathy Shepherd">
4: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
5: </nachricht>
6: <nachricht anzahl="a2" von="Greg Shepherd">
7: Ich brauche Hilfe bei meinen Hausaufgaben
8: </nachricht>
9: <nachricht anzahl="a3" von="Kristen Shepherd">
10: Bitte spiele heute Abend Scribble mit mir
11: </nachricht>
12:
13: <ergebnis nchr="a1">
14: Milch war ueber dem Verfallsdatum
15: </ergebnis>
16: <ergebnis nchr="a1">
17: bin zu einem anderen Laden gegangen
18: </ergebnis>
19: <ergebnis nchr="a2">
20: Hausaufgaben fruehzeitig beendet
21: </ergebnis>
22: </notiz>
Um die Absicht dieses XML-Dokuments zu verdeutlichen, stellen Sie sich ein Szenario vor, bei dem eine Anwendung kurze Nachrichten speichert, die den ganzen Tag über ein Handy, einen Pager oder E-Mail eingegangen sind. Jeder Nachricht wird eine eindeutige ID zugewiesen (zum Beispiel das anzahl-Attribut). Die gleiche Anwendung speichert ergebnis-Elemente, die aufgezeichnet werden oder auch nicht (d.h. sie sind nicht #REQUIRED). Wenn diese optionalen ergebnis-Elemente tatsächlich aufgezeichnet werden, muss ihnen aber eine bestimmte nachricht (durch das Attribut nchr) zugeordnet werden, sodass sie später verarbeitet, vielleicht angepasst werden können.
Das stellt einen vor ein ziemlich komplexes Validierungsproblem, aber eines, das mit einer DTD leicht gehandhabt werden kann, wenn man die Attributstypen ID und IDREF verwendet. Listing 4.19 liefert die DTD-Validierung für dieses Szenario.
Listing 4.19: Validierung mit den Attributstypen ID und IDREF - nachricht18.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht+, ergebnis+ ) >
4: <!ELEMENT nachricht ( #PCDATA)>
5: <!ATTLIST nachricht
6: anzahl ID #REQUIRED
7: von CDATA #REQUIRED>
8: <!ELEMENT ergebnis (#PCDATA)>
9: <!ATTLIST ergebnis
10: nchr IDREF #IMPLIED>
11: ]>
12: <notiz>
13: <nachricht anzahl="a1" von="Kathy Shepherd">
14: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
15: </nachricht>
16: <nachricht anzahl="a2" von="Greg Shepherd">
17: Ich brauche Hilfe bei meinen Hausaufgaben
18: </nachricht>
19: <nachricht anzahl="a3" von="Kristen Shepherd">
20: Bitte spiele heute Abend Scribble mit mir
21: </nachricht>
22:
23: <ergebnis nchr="a1">
24: Milch war ueber dem Verfallsdatum
25: </ergebnis>
26: <ergebnis nchr="a1">
27: bin zu einem anderen Laden gegangen
28: </ergebnis>
29: <ergebnis nchr="a2">
30: Hausaufgaben fruehzeitig beendet
31: </ergebnis>
32: </notiz>
![]()
Zeile 3 enthält ein anderes Inhaltsmodell als die bisher gezeigten. Vor allem gibt es ein Pluszeichen (+) hinter den abgeleiteten Elementen nachricht und ergebnis in der Inhaltsspezifikation für das Element notiz. Das ist ein Frequenzanzeiger, der bedeutet, dass das abgeleitete Element einmal oder mehrmals in dem Container-Element enthalten sein muss. In diesem Fall wird Zeile 3 so interpretiert, dass sie bedeutet, das notiz-Element enthält ein oder mehrere Elemente nachricht, denen ein oder mehrere Elemente ergebnis folgen (Sie erinnern sich, dass das Komma immer die Reihenfolge regelt).
Zeile 4 deklariert, dass das nachricht-Element Text enthält, #PCDATA.
Die Liste der deklarierten Attribute für das Element nachricht beginnt in Zeile 5. In Zeile 6 wird durch die Deklaration festgestellt, dass das obligatorische Attribut anzahl den Typ ID hat. ID heißt, dass jedes anzahl-Attribut einzigartig sein muss. Wird ein Wert für anzahl in einem anderen Element wiederholt, schlägt die Validierung des Dokuments fehl.
![]()
Ein Attribut vom Typ ID muss mit einem Buchstaben, einem Doppelpunkt (:) oder einem Unterstrich (_) beginnen. Nur ein Attribut vom Typ ID kann pro Element eingeschlossen sein.
![]()
Zeile 7 wird von den vorhergehenden Beispielen übernommen und zeigt an, dass das Element nachricht ein Attribut von haben muss, das einen String umfasst.
Zeile 8 deklariert, dass ergebnis Text einschließt.
In Zeile 10 wird das nchr-Attribut für das Element ergebnis als Attribut vom Typ IDREF deklariert. Das heißt, dass der Wert des Attributs nchr im Element ergebnis dem Wert des entsprechenden anzahl-Attributs im Element nachricht zugeordnet ist. Im Beispiel ist "a1", Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen den Resultaten Milch war über dem Verfallsdatum und ging in einen anderen Laden zugeordnet. In ähnlicher Weise ist das Element ergebnis, Hausaufgaben frühzeitig beendet mit dem Attribut "a2", dem nachricht-Element, das den Attributswert "a2", Ich brauche Hilfe bei meinen Hausaufgaben für anzahl hat, zugeordnet. Sie werden bemerken, dass kein ergebnis mit nachricht anzahl="a3" verbunden ist. Das ist deshalb akzeptabel, weil nchr in Zeile 10 als #IMPLIED oder optional deklariert wurde.
Elemente bei der Auszeichnung werden als Container betrachtet. Entities sind Ersetzungsstrings, die sich in eine andere Form auflösen. Die Leser, die sich mit HTML auskennen, werden wohl einige der Entities kennen, die man gewöhnlich in dieser Sprache verwendet. Zum Beispiel die Entity , die im Browser durch den Einschluss eines einzelnen Leerzeichens aufgelöst wird, das einen Umbruch verhindert. XML verwendet verschiedene Entity-Typen. Die erste, die wir betrachten, gestattet die Substitution eines Strings in einem XML-Dokument. Die Deklaration und die Definition der Entity finden in einem Schema statt. Trifft ein XML-Prozessor auf eine Entity, löst er sie auf, indem er sie durch das ersetzt, was für sie definiert ist. Der Prozessor erkennt, dass er auf eine Zeichen-Entity trifft, wenn das Zeichen & gefunden wird. Alle Zeichen-Entities haben diese Form:
&entity;
Das vorangestellte Ampersand-Zeichen (das kaufmännische Und-Zeichen) und der nachfolgende Strichpunkt grenzen die Entity-Referenz ab.
Am siebten Tag werden Sie die Verwendung von Entities bei XML im Detail untersuchen. Entities kann man auf verschiedene Weise verwenden. Sie werden sehen, wie man Entities verwendet, um auf eine in einer DTD gespeicherte Variable zu verweisen. Listing 4.20 zeigt eine Entity-Deklaration, die zur Darstellung eines Datenstrings verwendet wird.
Listing 4.20: Die Ersetzung der Entity in XML unter Verwendung einer DTD - nachricht19.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht+, ergebnis+ ) >
4: <!ELEMENT nachricht ( #PCDATA)>
5: <!ATTLIST nachricht
6: anzahl ID #REQUIRED
7: von CDATA #REQUIRED>
8: <!ELEMENT ergebnis (#PCDATA)>
9: <!ATTLIST ergebnis
10: nchr IDREF #IMPLIED>
11: <!ENTITY heute "073001">
12: ]>
13: <notiz>
14: <nachricht anzahl="a1" von="Kathy Shepherd">
15: &heute; - Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
16: </nachricht>
17: <nachricht anzahl="a2" von="Greg Shepherd">
18: &heute; - Ich brauche Hilfe bei meinen Hausaufgaben
19: </nachricht>
20: <nachricht anzahl="a3" von="Kristen Shepherd">
21: &heute; - Bitte spiele heute Abend Scribble mit mir
22: </nachricht>
23: <ergebnis nchr="a1">
24: Milch war ueber dem Verfallsdatum
25: </ergebnis>
26: <ergebnis nchr="a1">
27: bin zu einem anderen Laden gegangen
28: </ergebnis>
29: <ergebnis nchr="a2">
30: Hausaufgaben fruehzeitig beendet
31: </ergebnis>
32: </notiz>
![]()
Zeile 11 zeigt die Entity-Deklaration für die Entity heute, die den String "073001" enthält. Trifft ein Parser auf die Entity-Referenz &heute; in den Zeilen 15, 18 und 21, dann ersetzt er den String.
Abbildung 4.3 zeigt die Ersetzung der Entity, wobei der Internet Explorer zum Parsen des Dokuments verwendet wird.
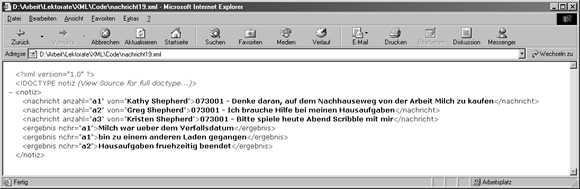
Abbildung 4.3: Ein geparstes Dokument mit einer Entity-Ersetzung
Es gibt in XML wenig Beschränkungen für Typen. Mit nmtoken sind einige Einschränkungen hinsichtlich der zulässigen Zeichen im XML-Inhalt möglich. Insbesondere beschränkt nmtoken die Daten auf dieselben Regeln, die für die Konventionen der Elementnamen in XML gelten, was eigentlich keine Einschränkung darstellt. Dennoch beschränkt der Attributstyp Namenstoken oder nmtoken die Werte auf Buchstaben, Ziffern, Punkte, Bindestriche, Doppelpunkte und Unterstrich. Listing 4.21 zeigt die Verwendung des Attributstyps nmtoken.
Listing 4.21: Der Attributstyp NMTOKEN in einer DTD - nachricht20.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht+, ergebnis+ ) >
4: <!ELEMENT nachricht ( #PCDATA)>
5: <!ATTLIST nachricht
6: anzahl ID #REQUIRED
7: von CDATA #REQUIRED
8: Telefon NMTOKEN #REQUIRED>
9: <!ELEMENT ergebnis (#PCDATA)>
10: <!ATTLIST ergebnis
11: nchr IDREF #IMPLIED>
12: <!ENTITY heute "073001">
13: ]>
14: <notiz>
15: <nachricht anzahl="a1" von="Kathy Shepherd" phone="720-555-6382">
16: &heute; - Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
17: </nachricht>
18: <nachricht anzahl="a2" von="Greg Shepherd" Telefon="720-555-1234">
19: &heute; - Ich brauche ein wenig Hilfe bei den Hausaufgaben
20: </nachricht>
21: <nachricht anzahl="a3" von="Kristen Shepherd" phone="720-555-4321">
22: &heute; - Bitte spiele heute Abend Scribble mit mir
23: </nachricht>
24: <ergebnis nchr="a1">
25: Die Milch lag ueber dem Verfallsdatum
26: </ergebnis>
27: <ergebnis nchr="a1">
28: bin in einen anderen Laden gegangen
29: </ergebnis>
30: <ergebnis nchr="a2">
31: Hausaufgaben fruehzeitig beendet
32: </ergebnis>
33: </notiz>
In Zeile 8 wird das Attribut telefon des Elements nachricht als Attribut vom Typ nmtoken deklariert. So, wie es gezeigt wird, ist das Dokument gültig; würde man den Wert des Attributs telefon in Zeile 15 jedoch auf
15: <nachricht anzahl="a1" von="Kathy Shepherd" telefon="720 555 6382">
ändern, wäre das Dokument nicht mehr gültig, weil bei einer nmtoken-Deklaration keine Leerzeichen erlaubt sind.
Aufzählungs-Attribute beschreiben eine Liste potenzieller Werte für die Attribute, die ausgewertet werden. Damit der Gültigkeit genüge getan wird, muss die Liste einen Wert für das Attribut einschließen; Alles andere ist nicht gültig. Aufzählungswerte werden durch das »Pipe«-Zeichen (|) getrennt, das der XML-Prozessor als logisches »oder« interpretiert. Listing 4.22 zeigt in Zeile 8 das Aufzählungs-Attribut wichtigkeit und deklariert drei mögliche Werte (gering, normal und dringend) sowie einen Standardwert (normal).
Listing 4.22: Ein Attribut vom Aufzählungstyp - nachricht21.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht+, ergebnis+ ) >
4: <!ELEMENT nachricht ( #PCDATA)>
5: <!ATTLIST nachricht
6: anzahl ID #REQUIRED
7: von CDATA #REQUIRED
8: wichtigkeit ( gering | normal | dringend) "normal">
9: <!ELEMENT ergebnis (#PCDATA)>
10: <!ATTLIST ergebnis
11: nchr IDREF #IMPLIED>
12: <!ENTITY heute "073001">
13: ]>
14: <notiz>
15: <nachricht anzahl="a1" von="Kathy Shepherd" wichtigkeit="gering">
16: &heute; - Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
17: </nachricht>
18: <nachricht anzahl="a2" von="Greg Shepherd" wichtigkeit="dringend">
19: &heute; - Ich brauche ein wenig Hilfe bei den Hausaufgaben
20: </nachricht>
21: <nachricht anzahl="a3" von="Kristen Shepherd">
22: &heute; - Bitte spiele heute Abend Scribble mit mir
23: </nachricht>
24: <ergebnis nchr="a1">
25: Milch lag ueber dem Verfallsdatum
26: </ergebnis>
27: <ergebnis nchr="a1">
28: bin in einen anderen Laden gegangen
29: </ergebnis>
30: <ergebnis nchr="a2">
31: Hausaufgaben fruehzeitig beendet
32: </ergebnis>
33: </notiz>
![]()
In den Zeilen 15 und 18 werden die jeweiligen Werte gering und dringend für das Attribut wichtigkeit deklariert. Man kann sich vorstellen, dass eine Anwendung so gestaltet ist, dass sie die nachricht-Elemente unterschiedlich behandelt, je nachdem, welcher Wert für das wichtigkeit-Attribut deklariert wird. Das nachricht-Element in Zeile 21 wird von einer Anwendung so verarbeitet, als hätte es den wichtigkeit-Wert normal, was der Standardwert für dieses Attribut ist.
Zeile 8 kann so verändert werden, dass der Standardwert ausgeschlossen und durch ein #implied-Schlüsselwort ersetzt wird:
15: wichtigkeit (gering | normal | dringend) #IMPLIEDIn diesem Fall wird von der Anwendung kein wichtigkeit-Attribut verlangt und wenn keines vorhanden ist, wird kein Standardwert angenommen.
Auch wenn nicht direkt auf sie Bezug genommen wurde, haben Sie schon einige der Frequenz-Indikatoren und Sequenz-Deklarationen kennen gelernt, die Bestandteil der DTD-Grammatik in den heute vorgestellten Beispielen sind. Wenn Sie die Übungen immer eingegeben haben, dann haben Sie sich schon ein wenig mit ihrer Platzierung und ihrem syntaktischen Verhältnis zu anderen DTD-Komponenten vertraut gemacht. Sie haben zum Beispiel die Auswirkungen von Pluszeichen (+), Sternchen (*), vertikalen Trenn- oder »Pipe«-Zeichen (|) und Kommata (,) in den Beschreibungen zu den Inhaltsmodellen gesehen. Tabelle 4.4 zeigt alle besonderen DTD-Indikatoren.
Tabelle 4.4: Sequenz- und Frequenz-Indikatoren einer DTD:
Sequenz-Indikatoren werden manchmal als Verbindungszeichen bezeichnet, weil sie dazu dienen, zwei oder mehr Elemente zu verbinden oder einen direkten Bezug zwischen ihnen herzustellen. Listing 4.23 zeigt eine XML-Instanz mit einer DTD, die von allen Sequenz- und Frequenz-Indikatoren Gebrauch macht.
Listing 4.23: Eine DTD, die alle Sequenz- und Auftritts-Indikatoren verwendet - nachricht22.xml
1: <?xml version="1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht, absender?, ergebnis)+>
4: <!ELEMENT nachricht (#PCDATA)>
5: <!ELEMENT absender EMPTY>
6: <!ELEMENT ergebnis (aktion*)>
7: <!ELEMENT aktion (#PCDATA)>
8: <!ATTLIST nachricht
9: anzahl ID #REQUIRED
10: von CDATA #REQUIRED>
11: <!ATTLIST absender
12: zustellung (telefonisch | persoenlich | email) "email">
13: ]>
14: <notiz>
15: <nachricht anzahl="call_01" von="Kathy Shepherd">
16: fuer die Verabredung zum Mittagessen eingetroffen
17: </nachricht>
18: <absender zustellung="persoenlich"/>
19: <ergebnis>
20: <aktion>zum Restaurant gegangen</aktion>
21: <aktion>fuhr mit dem Auto</aktion>
22: </ergebnis>
23: <nachricht anzahl="call_02" von="Kristen Shepherd">
24: </nachricht>
25: <absender zustellung="telefonisch"/>
26: <ergebnis>
27: <aktion>Anruf beantwortet</aktion>
28: </ergebnis>
29: <nachricht anzahl="call_03" von="Kathy Shepherd">
30: </nachricht>
31: <absender />
32: <ergebnis>
33: <aktion>Antwort per E-Mail</aktion>
34: </ergebnis>
35: <nachricht anzahl="call_04" von="Greg Shepherd">
36: nicht vergessen Angelausflug zu buchen
37: </nachricht>
38: <ergebnis>
39: </ergebnis>
40: </notiz>
![]()
Zeile 3 legt fest, dass der Inhalt für notiz ein oder mehr Elementsätze von nachricht, absender und ergebnis ist und zwar in dieser Reihenfolge. Der Elementsatz darf dann jedoch nicht das Element absender enthalten. Ist das Element absender vorhanden, dann kann es nur eines davon geben. Es gilt für jeden Elementsatz, dass nachricht, absender und ergebnis nur einmal vorkommen können. In der Instanz muss ein Elementsatz vorhanden sein, darüber hinaus können es aber auch beliebig viele sein.
Zeile 4 zeigt an, dass nachricht nur ein geparstes Zeichen enthält. Zeile 16 zeigt ein Beispiel für #pcdata in einem dieser nachricht-Elemente.
Zeile 5 deklariert, dass absender ein leeres Element ist. In den Zeilen 18, 25 und 31 sehen Sie, dass dies tatsächlich der Fall ist.
In Zeile 6 sehen Sie, dass das Element ergebnis eine beliebige Anzahl von aktion-Elementen enthalten kann oder auch keines.
Das aktion-Element in Zeile 7 umfasst Textdaten entsprechend der #pcdata-Deklaration.
Zeile 8 beginnt mit der Deklaration von Attributen für das nachricht-Element. Es gibt zwei davon: anzahl und von. In Zeile 9 wird deklariert, dass anzahl erforderlich und ein Attribut des Typs id ist, was bedeutet, dass alle anzahl-Elemente einmalig sein müssen. Zeile 10 deklariert, dass das von-Attribut einen erforderlichen Wert hat und zwar ungeparste Zeichendaten.
Die Deklaration des Attributs zustellung für das Element absender beginnt in Zeile 11. Zeile 12 zeigt an, dass der gültige Wert für jedes zustellung-Attribut entweder telefonisch oder persoenlich oder email ist. Ist kein zustellung-Attribut für ein absender-Element programmiert, nimmt die verarbeitende Anwendung als Standardwert email an.
Die Zeilen 14 bis 40 umfassen eine gültige XML-Instanz, die allen von der DTD auferlegten Beschränkungen entspricht. Sie sehen, dass die Elemente nachricht, absender und ergebnis über das ganze Dokument hinweg wiederholt werden, außer im letzten Elementsatz, der kein ergebnis-Element enthält. Diese Abwesenheit ist zulässig, weil hinter absender in Zeile 3 ein Fragezeichen (?) steht.
In den Zeilen 18 und 25 werden die zustellung-Attribute des jeweiligen absender-Elements als persoenlich bzw. telefonisch deklariert. Für das absender-Element in Zeile 31 ist kein zustellung-Attribut deklariert, also wird die Anwendung annehmen, dass das Attribut zustellung in diesem Fall den Standardwert email hat.
Ab dem zweiten Tag haben Sie Ihre wohl geformten Dokumente geparst, indem Sie sie im Browser Internet Explorer in der Version 5.0 oder höher anzeigten (IE5). Das hat funktioniert, weil IE5 einen eingebauten Parser hat. Als Nächstes werden Sie mehrere der heute erzeugten Dokumente in den IE5 laden und sich die Resultate ansehen. Beginnen Sie mit dem Dokument, das Sie als nachricht19.xml abgespeichert haben (Listing 4.20) und vergleichen Sie das Ergebnis mit Abbildung 4.3. Sie erinnern sich sicher, dass dieses Beispiel eine Entity-Ersetzung vorführte. Wenn Ihr Ergebnis nicht genau das gleiche ist, das in der Abbildung gezeigt wird, überprüfen Sie Ihren Code und vergleichen ihn Zeile für Zeile mit dem Listing, um zu sehen, ob Sie das Problem erkennen und korrigieren können. Wenn Sie mit dem Ergebnis der Browseranzeige von nachricht19.xml zufrieden sind, sollten Sie es mit einigen weiteren der Dateien versuchen, die Sie heute erzeugt haben.
Am zweiten Tag sahen Sie die Resultate des Versuchs, mit dem IE5 ein Dokument zu parsen, das nicht wohl geformt ist. Im Einzelnen erzeugte der IE5 Fehlermeldungen, die die Art des Problems angaben, etwa nicht passende Start- und Schluss-Tags, eine fehlende Klammer oder ein nicht korrekt geformtes Element. Alle Beispiele, die Sie heute erstellt haben und die DTDs enthalten, sind sowohl wohl geformt als auch gültig. Erzeugen Sie deshalb eine ungültige XML-Instanz, um die Resultate im IE5 anzusehen. Laden Sie das von Ihnen gespeicherte Dokument nachricht15.xml in einen Editor und modifizieren Sie es so, dass es der Instanz gleicht, die Listing 4.24 vorstellt. Haben Sie nachricht15.xml nicht gespeichert, dann kopieren Sie jetzt den Code von Listing 4.24 in Ihren Editor.
Listing 4.24: Ein ungültiges XML-Dokument - nachricht23.xml
1: <?xml version = "1.0"?>
2: <!DOCTYPE notiz [
3: <!ELEMENT notiz ( nachricht ) >
4: <!ELEMENT nachricht ( #PCDATA)>
5: <!ATTLIST nachricht
6: zahl CDATA #REQUIRED
7: datum CDATA #REQUIRED
8: von CDATA #FIXED "Kathy Shepherd">
9: ]>
10: <notiz>
11: <!-- fester Wert für ein Attribut s/b "Kathy Shepherd" -->
12: <nachricht zahl="10" datum="073001" von="jemand anderem">
13: Denke daran, auf dem Nachhauseweg von der Arbeit Milch zu kaufen
14: </nachricht>
15: </notiz>
Die Veränderungen, die Sie an nachricht15.xml durchführen, schließen die Modifizierung des Werts für das von-Attribut im nachricht-Element in Zeile 12 ein, sodass es keinen #fixed- Wert für Kathy Shepherd mehr hat, wie die DTD das vorschreibt. Ändern Sie den Wert auf jemand anders oder einen beliebigen Wert Ihrer Wahl. Es kommt nicht darauf an, wichtig ist nur, dass es sich nicht mehr um genau den Wert handelt, der in Zeile 8 deklariert wird.
Fügen Sie den Kommentar aus Zeile 11 ein, sodass Sie die Veränderungen leicht nachvollziehen können, wenn Sie sich das Resultat im IE5 ansehen. Wenn Sie fertig sind, speichern Sie das Dokument unter nachricht23.xml und parsen es mit dem IE5. Wenn Sie Ihr Dokument in den IE5 laden, sollten Sie etwas Ähnliches sehen wie das Bild in Abbildung 4.4.
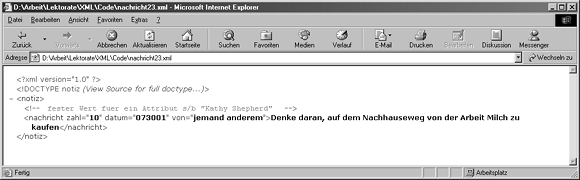
Abbildung 4.4: Ein ungültiges XML-Dokument (nachricht23.xml), wiedergegeben im IE5
Angesichts Ihres Wissens, dass es einen Gültigkeitsfehler in Ihrem Dokument gibt, ist dies das Resultat, das Sie erwarteten? Wahrscheinlich nicht! Nachdem Sie wissen, dass der Wert für das von-Attribut des nachricht-Elements in Zeile 12 ungültig ist, haben Sie nicht eine Fehlermeldung durch den IE5 in dieser Hinsicht erwartet? Solch eine Fehlermeldung haben Sie nicht bekommen. Eigentlich sieht das Resultat so aus, als wäre das Dokument, das Sie geparst haben, in Ordnung. Der Kommentar, den Sie der Instanz hinzugefügt haben, bietet den einzigen Hinweis darauf, dass irgendetwas nicht stimmt.
Was sagt Ihnen das über den Parser, der dem IE5 eingebaut ist?
Diese Übung beweist, dass der IE5 einen Parser enthält, der nicht in der Lage ist, alle Schemata zu validieren. Der IE validiert XML nicht mit einer DTD, sondern ignoriert diese. Die Version des MSXML-Parsers, der dem IE5 und dem IE6 beigefügt ist, hat bestätigt, dass Ihr Dokument in Ordnung ist, indem er eine Baumansicht Ihres Dokuments anzeigte. Ihr Dokument ist tatsächlich wohl geformt, aber laut der DTD, die ihm eingebettet ist, ist es nicht gültig. IE5 hat das Dokument nicht mit der DTD validiert; er hat nur zurückgegeben, dass das Dokument wohl geformt ist.
Um die Gültigkeit zu überprüfen, wenn Sie DTDs für Ihre XML-Dokumente verwenden, müssen Sie sich deshalb einen validierenden Parser besorgen. Ein solcher Parser ist als COM-Objekt im IE5-Paket eingeschlossen, auch wenn der Browser ihn nicht verwendet. Um auf diesen validierenden Parser zugreifen zu können, müssen Sie das Parser-Objekt in einer Anwendung oder durch einfaches Scripting (etwa mit JavaScript oder VBScript) - Instanzieren. Am 12. Tag werden Sie lernen, wie man Scripts schreibt, um auf den MSXML-Parser zugreifen zu können. Inzwischen können Sie eine HTML-Seite herunterladen, die entweder JavaScript oder VBScript enthält und diese Aufgabe für Sie übernimmt. Zu diesem Zweck laden Sie in Ihrem Browser die Microsoft Developers Network-Website unter http://msdn.microsoft.com/downloads/samples/internet/xml/ xml_validator/ und folgen Sie den Anweisungen für den Download und die Installation einer Version des XML-Validierer-Scripts. Der Download beinhaltet sowohl eine Version von JavaScript als auch von VBScript des XML-Validierers. IE5 kann beide starten. Wenn Sie im Browser eines der Scripts laden (validate_js.htm oder validate_vbs.htm), sollten Sie auf dem Bildschirm die Ansicht haben, die Abbildung 4.5 zeigt.
Bevor Sie versuchen, eine der Instanzen zu validieren, die Sie heute erstellt haben, legen Sie die Scriptdatei validate_js.htm oder validate_vbs.htm im gleichen Verzeichnis ab, in dem Sie Ihre heutige Arbeit gespeichert haben. Damit können Sie einfach den Namen der jeweiligen Datei angeben und sich auf den relativen Pfad zu nahe gelegenen Dokumenten verlassen, ohne ausdrücklich den ganzen qualifizierten Pfad angeben zu müssen, um Ihre Dateien im Computer aufzuspüren.
Wenn die .htm-Datei für Ihr Validator-Script im gleichen Verzeichnis abgelegt wurde wie Ihre heutigen XML-Instanzen, können Sie einige davon parsen, um sich die Resultate anzusehen. Abbildung 4.6 zeigt die Resultate für das Parsen der Datei nachricht19.xml, die mit Listing 4.20 erzeugt wird. Für eine solche detaillierte Wiedergabe wie in Abbildung 4.6 müssen Sie jeden Knoten des Dokuments erweitern, indem Sie ihn anklicken. Die Erweiterung zeigt den Inhalt abgeleiteter Elemente und Textdaten. Wenn die gesamte Instanz expandiert ist, entspricht die Struktur auf dem Bildschirm in etwa der Baumstruktur, die das Dokument beschreibt.
Abbildung 4.5: Das XML-Validator-Script von Microsoft, angezeigt im IE6

Abbildung 4.6: Eine durch das XML-Validator-Script erfolgreich geparste, gültige XML-Instanz (nachricht19.xml)
Nachdem Sie nun die Resultate des Parsens von Dokumenten gesehen haben, die bekanntermaßen wohl geformt und gültig sind, versuchen Sie jetzt, das Dokument mit dem Fehler zu parsen (nachricht23.xml), das vom Listing 4.24 gezeigt wird. Abbildung 4.7 zeigt das Resultat dieses Versuchs.
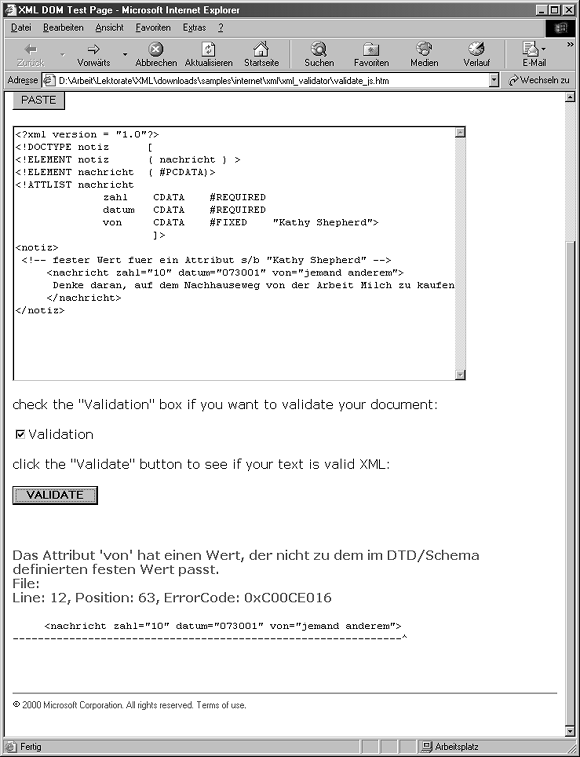
Abbildung 4.7: Ein ungültiges XML-Dokument (nachricht23.xml), geparst durch das Validierer-Script von Microsoft.
Die Fehlermeldung, die dieser validierende Parser hervorbringt, zeigt an, dass das Attribut von einen Wert hat, der dem festgelegten Wert (»Kathy Shepherd«), den Sie in der DTD deklariert haben, nicht entspricht. Sie wissen bereits, dass genau dieser Fehler in die Instanz programmiert wurde. Das Dokument ist immer noch wohl geformt, aber gemäß den Beschränkungen, die die DTD erzwingt, ist es nicht mehr gültig.
Führen Sie dieses Experiment mit einigen anderen der Dokumente durch, die Sie heute erstellt haben, und bauen Sie in einige davon Fehler ein, um zu sehen, wie der Parser Sie davon unterrichtet.
Heute haben Sie gesehen, wie man mit internen DTDs einige mächtige Einschränkungen erzeugen kann. Heute werden Sie noch die Veränderungen kennen lernen, die bei der Dokumenttyp-Deklaration erforderlich sind, um einem XML-Dokument eine externe DTD zuzuordnen. Die DTD kann mit den heute erzeugten nahezu identisch sein. Der Hauptunterschied ist, dass sie in einer eigenen, von der XML-Instanz separaten Datei gespeichert wird. Ein validierender Parser, der den Bezug der Dateien des XML- Dokuments zu denen der DTD herstellen kann, kann feststellen, ob den Beschränkungen, die das Schema auferlegt, entsprochen wird. Um die Dinge zu vereinfachen, sollten Sie die XML-Dokumente, DTDs und die Parser-Scripts im selben Verzeichnis auf Ihrem Computer speichern.
Die Dokumenttyp-Deklaration, die Sie bislang heute verwendet haben, folgt dieser Syntax:
<!DOCTYPE wurzel_element [
<!ELEMENT wurzel_element ( Inhaltsmodell )>
]>
Alles, was innerhalb der eckigen Klammern ([...]) steht, macht die interne DTD- Untermenge aus. Eine externe DTD-Untermenge ist normalerweise in einer getrennten Datei mit der Erweiterung .DTD abgelegt. Als Gesamt-DTD einer Instanz betrachtet man die Kombination aus interner Untermenge und externer Untermenge, soweit beide existieren. Anders gesagt, wenn der XML-Dokument-Instanz sowohl eine Inline-DTD als auch ein externes DTD-Dokument zugeordnet sind, dann gründet die Gültigkeit auf der Kombination beider DTD-Untermengen.
Um auf eine externe DTD zu verweisen, muss die Dokumenttyp-Deklaration so modifiziert werden, dass sie eines der Schlüsselwörter Public oder System einschließt, denen dann die URL für das DTD-Dokument folgt. Das Schlüsselwort public wählt man normalerweise nur dann, wenn die DTD breit zugänglich oder öffentlich ist und eine große Anzahl von Anwendern sie gemeinsam nutzen. Public-DTDs haben normalerweise einen Namen und sind in einer DTD-Bibliothek oder einer Datenbank gespeichert. Wenn Sie an einem bestimmten XML-Projekt arbeiten, sollten Sie in einer Datenbank nachsehen, ob es schon eine public-DTD gibt, die Sie verwenden können. System-DTDs sind bei diesen Datenbanken in der Regel nicht erhältlich. Wenn Sie Ihre eigenen DTDs schreiben, verweisen Sie normalerweise mit dem Schlüsselwort System auf sie und verwenden dabei folgende Syntax:
<!DOCTYPE wurzel_element SYSTEM "meineregeln.DTD">
Sie haben heute bereits das Dokument mit der Ankündigung für die Kurslisten betrachtet, das am dritten Tag erstellt wurde. Wenn Sie die Anweisungen befolgt haben, haben Sie das Dokument aus Listing 4.1 in einer Datei namens kurse.xml gespeichert. Sie müssen die Instanz modifizieren, um eine Dokumenttyp-Deklaration einzufügen, die zu einer DTD passt. Listing 4.25 zeigt kurse.xml mit einer zusätzlichen Doctype-Deklaration in Zeile 2.
Listing 4.25: Das Dokument kurse.xml wird modifiziert, um eine doctype-Deklaration einzufügen.
1: <?xml version="1.0"?>
2: <!DOCTYPE ankuendigung SYSTEM "kurse.dtd">
3
4: <ankuendigung>
5: <verteiler>Zur sofortigen Veroeffentlichung</verteiler>
6: <an>Alle potenziellen Studenten</an>
7: <von>Devan Shepherd </von>
8: <thema>Oeffentliches Kursangebot im August</thema>
9: <notiz>ACME-Training freut sich, die folgenden Kurse
10: ankuendigen zu koennen, die monatlich in seinem
11: Hauptquartier stattfinden.</notiz>
12: <mehr_info>Weitere Informationen und Einschreibung zu
13: diesen Kursen unter <website>http://acme-train.com/university </website></mehr_info>
14: <kurse>
15: <kurs id="XML111" dozent="Bob Gonzales">
XML fuer Anfaenger</kurs>
16: <kurs id="XML333" dozent="Devan Shepherd">
XML fuer Fortgeschrittene</kurs>
17: <kurs id="XMT222" dozent="Gene Yong">
XMetal Core Konfiguration</kurs>
18: </kurse>
19: </ankuendigung>
Wenn Sie diese notwendige Einfügung gemacht haben, speichern Sie die Datei unter kurse_2.xml.
In der nächsten Übung werden Sie eine externe DTD mit dem Namen kurse.dtd erstellen, wie in Zeile 2 angegeben, und das Resultat dann parsen, um zu zeigen, dass das Dokument gültig ist. Sie erinnern sich, dass Abbildung 4.2 einen DTD-Baum zeigt, der die Vorgaben für diese Instanz angibt. Erzeugen Sie mit einem Texteditor die in Listing 4.26 gezeigte DTD und speichern Sie sie unter kurse.dtd.
Listing 4.26: Eine DTD zum Validieren von kurse_2.xml - kurse.dtd
1: <!ELEMENT ankuendigung ( verteiler, an, von, thema,
notiz, mehr_info, kurse ) >
2: <!ELEMENT verteiler ( #PCDATA ) >
3: <!ELEMENT an ( #PCDATA ) >
4: <!ELEMENT von ( #PCDATA ) >
5: <!ELEMENT thema ( #PCDATA ) >
6: <!ELEMENT notiz ( #PCDATA ) >
7: <!ELEMENT mehr_info ( #PCDATA | website )* >
8: <!ELEMENT website ( #PCDATA ) >
9: <!ELEMENT kurse ( kurs+ ) >
10: <!ELEMENT kurs ( #PCDATA ) >
11: <!ATTLIST kurs
12: id CDATA #REQUIRED
13: dozent CDATA #REQUIRED >
![]()
Zeile 1 definiert das Element ankuendigung als Container-Element, das verteiler, an, von, thema, notiz, mehr_info und kurse als abgeleitete Elemente enthält. Für jedes dieser Elemente wird wiederum deklariert, dass es Textdaten (#pcdata) enthält. In den Zeilen 12 und 13 werden die Attribute id und dozent für das Element kurs deklariert.
Parsen Sie nun kurse_2.xml mit einem der XML-Validierer-Scripts, um ein Resultat ähnlich dem in Abbildung 4.8 gezeigten zu erzeugen. Im Resultat sind alle Knoten expandiert.

Abbildung 4.8: Ein gültiges XML-Dokument (kurse_2.xml) mit einer externen DTD (kurse.dtd), geparst von einem XML-Validator-Script
Sie haben nun Beispiele für interne und externe DTDs gesehen. Welche davon man verwenden soll, liegt zum großen Teil im Entscheidungsbereich des Dokumentautors. Manchmal ist es vorteilhaft, eine externe DTD zu verwenden, wenn diese eine Dokumentenklasse definiert und mehrmals wiederverwendet werden kann. Wenn Sie eine Ansammlung von Dokumenten haben, die mit einer Reihe von DTDs validiert werden, ist es sinnvoll, die DTDs in getrennten Dateien abzulegen - vielleicht in einem bestimmten DTD-Verzeichnis auf Ihrem Server. Andererseits stellt die Verwendung einer internen DTD vor allem in einem kleinen, zum einmaligen Gebrauch gedachten XML- Instanzdokument sicher, dass Sie die DTD im Blick haben, wenn Sie das Dokument in einem Editor öffnen. Sie müssen diese Alternative abwägen und entscheiden, welcher Ansatz Ihren Bedürfnissen am ehesten entspricht.
Sie haben heute gelernt, wie man interne und externe Document Type Definition (DTD)- Schemata erstellt. Sie beherrschen jetzt die Element- und Attributs-Deklarationen und haben viele Beispiele für immer komplexer werdende Anwendungen der DTD- Beschränkungen gesehen. Sie haben den Unterschied zwischen validierenden und nicht validierenden Parsern kennen gelernt und wissen, wann man sie jeweils verwenden kann.
Um die Übungen für heute durchzuführen, mussten Sie eine völlig neue Sprache erlernen, die nur eine oberflächliche Ähnlichkeit mit XML hat. Die Konstruktionen und Grammatikregeln hat sie mit XML gemeinsam, verwendet aber eine völlig andere Syntax.
Am 5. und 6. Tag werden Sie zwei andere Schemasprachen verwenden, um XML- Dokumente zu validieren. Diese haben bedeutende Vorteile gegenüber DTDs. Einmal verwendet jede von ihnen die gleiche Syntax wie XML; die Schema-Dokumente selbst sind eigentlich XML-Instanzen. Sie werden auch eine ausgefeiltere Möglichkeit der Steuerung kennen lernen einschließlich der Beschränkungen für die Datentyp-Validierung und andere Möglichkeiten, die DTDs nicht haben.
Frage:
Wo lag der Ursprung für den Ansatz der Document Type Definition?
Antwort:
DTDs kommen aus dem SGML-Universum, wo man sie jahrelang erfolgreich
einsetzte.
Frage:
Was genau macht eine DTD bei XML?
Antwort:
Eine DTD (oder auch jedes andere XML-Schema) stellt eine Schablone für die
Dokumentauszeichnung bereit, welche das Vorkommen, die Reihenfolge und die
Platzierung von Elementen und deren Attributen in einem XML-Dokument
festlegt.
Frage:
Welche Unterschiede gibt es zwischen einem Dokumentbaum und einem DTD-Baum?
Antwort:
Ein DTD-Baum hat selbst keinerlei Wiederholungen von Elementen oder der
Struktur. Seine Beschränkungen ermöglichen aber die Wiederholung von
Elementen in einer konformen, gültigen XML-Instanz.
Frage:
Was liefert eine Dokumenttyp-Deklaration einer XML-Instanz?
Antwort:
Eine Dokumenttyp-Deklaration, die in den Prolog eines XML-Dokuments platziert
wird, ordnet dem XML-Dokument eine Document Type Definition (DTD) zu.
Sobald ein XML-Prozessor auf diese Deklaration trifft, liest er die DTD und
validiert die XML-Instanz auf der Grundlage der Einschränkungen, die in der DTD
festgelegt sind.
Verwechseln Sie nicht die Begriffe Dokumenttyp-Deklaration und Document Type
Definition (DTD). Sie klingen ähnlich, meinen aber etwas völlig unterschiedliches.
Frage:
Welches sind einige der DTD-Schlüsselwörter, die man verwenden kann, um in XML
verschiedene Typen von Elementinhalten zu definieren?
Antwort:
Any lässt einen beliebigen Elementinhalt zu, Daten oder andere Elemente.
Gemischter Inhalt erlaubt den Elementen, geparste Zeichendaten (Text) oder
eine Kombination aus abgeleiteten Elementen und Text zu enthalten. Das
Schlüsselwort Empty deklariert, dass das Element keinen Inhalt enthält.
Frage:
Welche zwei Typen von Parsern werden bei XML verwendet?
Antwort:
Validierend und nicht validierend sind zwei übliche Unterschiede, die bei XML-
Parsern gelten. Ein nicht validierender Parser kann nur bestimmen, ob ein
XML Dokument wohl geformt ist, also ob es den grundlegenden Syntaxregeln von
XML folgt. Ein validierender Parser geht einen Schritt weiter und stellt sicher, dass
ein Dokument nicht nur wohl geformt ist, sondern auch den Beschränkungen
entspricht, die ihm ein zugeordnetes Schema auferlegt.
Die Übung soll Ihre Kenntnisse dessen, was Sie heute gelernt haben, überprüfen. Die Lösungen finden Sie in Anhang A.
Gestern haben Sie ein Baumstruktur-Diagramm erstellt und einige der Gültigkeitsregeln für Ihre Music Collection Markup Language (MCML) aufgezählt. Erzeugen Sie nun eine DTD auf der Grundlage des heute Gelernten, um die MCML-Dateien zu validieren.
