




Gestern haben Sie ein wenig über XML und seine Herkunft erfahren. Heute werden Sie die Konstruktionsregeln für ein XML-Dokument kennen lernen.
Sie haben am ersten Tag einige Listings von XML-Dokumenten gesehen. XML- Dokumente umfassen Elemente und Attribute, die Namen verwenden, die Sie erzeugen können. Heute werden Sie diese Konstrukte genauer erforschen und einige XML- Dokumente erstellen. Zunächst erstellen Sie dabei ein so genanntes »wohl geformtes« XML-Dokument.
![]()
Der Begriff XML-Instanz ist ein Synonym für XML-Dokument und kann im gleichen Zusammenhang verwendet werden. Im Buch werden beide Begriffe verwendet. Ein Dokument ist eigentlich eine Instanz der Auszeichnungssprache, die verwendet wird. Der Klarheit wegen wird in Bezug auf HTML-Code der Begriff HTML-Seite anstelle von HTML-Dokument oder HTML-Instanz verwendet.
Damit ein XML-Dokument »wohl geformt« genannt werden kann, muss es allen grundlegenden Syntaxregeln für XML folgen. Einige dieser Regeln haben Sie am ersten Tag kennen gelernt, weitere folgen heute. Wird eine der grundlegenden Syntaxregeln verletzt, ist Ihr Dokument nicht wohl geformt und kann von XML-Prozessoren nicht verwendet werden. Der XML-Prozessor wird sogar eine Fehlermeldung ausgeben, was Ihnen in vielen Fällen dabei helfen wird, das Problem zu berichtigen, weil darin die Richtung aufgezeigt wird, in welcher der Fehler zu suchen ist.
XML-Dokumente sind einfache Textdateien, daher können sie mit fast jedem einfachen Texteditor erstellt und manipuliert werden. Es gibt auch eine Vielzahl ausgefeilter Editoren, welche die Syntax Ihres Dokuments überprüfen, während Sie die Daten eingeben. Einige dieser Editoren können kostenlos aus dem Internet heruntergeladen werden, etwa der Editor Architag X-Ray (http://www.architag.com/xray) und kommerziell erhältliche Produkte, wie der XML-Spy von Altova (http://www.xmlspy.com), oder der Editor XML Authority von Tibco Extensibility (http://www.extensibility.com). Eine ausführliche Liste von Software-Tools finden Sie online unter http://www.oasis-open.org/ cover/publicSW.html. Beinahe alle Betriebssysteme stellen ebenfalls einfache Editoren bereit. Um den Übungen dieses Buchs folgen und sie durchführen zu können, brauchen Sie zumeist nur einen einfachen Texteditor.
Zusätzlich erfordern viele der Übungen, dass Sie Ihre XML-Dokumente in einen Parser einspeisen, um sie auf Fehler zu überprüfen. Ein Parser ist eine Software, welche die Syntaxregeln von XML kennt und Ihnen mitteilt, dass sie auf Fehler gestoßen ist. Wenn noch keine Version auf Ihrem Computer installiert ist, wird empfohlen, dass Sie den Browser Internet Explorer von Microsoft in der Version 5 oder höher herunterladen. Dieser Browser hat einen eingebauten Parser. Den IE-Browser gibt es in Versionen für die Betriebssysteme Macintosh, Unix und Windows. Man kann ihn kostenlos unter http:// www.microsoft.com herunterladen.
Auch wenn eines der Ziele von XML-Technologien die völlige Unabhängigkeit von Plattformen, Software und dem Betriebssystem ist, stehen viele der einzelnen nützlichen Tools und Prozessoren leider noch nicht allgemein zur Verfügung. Einige der Codebeispiele aus diesem Buch funktionieren zum Beispiel nur auf einer Plattform von Microsoft oder wenn sie mit dem Netscape-Browser verarbeitet werden. Sie können auch von einer speziellen Implementierung eines Parsers auf Java-Grundlage abhängig sein. Das bedeutet, dass Sie eine gewisse Auswahl treffen müssen, wenn Sie bestimmte Lösungen implementieren wollen. Webentwickler sind sich zum Beispiel darüber im Klaren, dass viele Punkte von den Möglichkeiten des jeweiligen Browsers abhängen. Aus diesem Grund müssen sie sich in Bezug auf die Funktionalität, die sie in Websites einbauen, beschränken, damit eine möglichst große Personenanzahl auf die angebotenen Daten zugreifen kann. Wo immer es in diesem Buch möglich schien, wurde auf alternative Lösungen, Plattformen und Optionen verwiesen. Manchmal werden die Beispiele unter Verwendung einer bestimmten Technologiegrundlage wie der Plattform von Microsoft vorgestellt, aber die Konzepte lassen sich normalerweise leicht auf andere Plattformen übertragen. Am 12. Tag lernen Sie etwa, wie JavaScript-Programme erstellt werden, die auf die Implementierung einer Anwender-Programmierschnittstelle von Microsoft namens DOM (Document Object Model) zugreifen. Diese Implementierung von Microsoft wird vielfach unterstützt und hat die breiteste Installationsgrundlage aller DOM-Lösungen. Wenn jedoch Ihre Architektur eine andere Lösung erforderlich macht, finden Sie bei Perl, Java, Python und verschiedenen anderen beliebten Sprachen auch andere DOM- Implementierungen, die viele Plattformen unterstützen. In solchen Fällen werden Links im Web vorgestellt, wo alternative Tools zu finden sind.
In diesem Abschnitt lesen Sie mehr zu einigen Syntaxregeln und erhalten die Gelegenheit zu sehen, wie ein Parser XML-Dokumente handhabt. Um möglichst viel von den Erklärungen zu profitieren, sollten Sie jedes der Beispiele selbst erstellen und parsen.
Starten Sie Ihren Lieblings-Texteditor. Das Dokument, das Sie erzeugen, verwendet XML, um ein Rezept für eine Bohnentunke auszuzeichnen. Zunächst sollten Sie darüber nachdenken, wie man ein typisches Rezept strukturiert. Abbildung 2.1 zeigt ein Rezept auf einer Karteikarte. Die meisten Rezepte haben einen Titel, um sie voneinander zu unterscheiden. Eine Zutatenliste und die Menge dieser Zutaten ist ein wesentlicher Bestandteil, ebenso wie eine Reihe von Anweisungen zur Zubereitung. Außerdem werden Sie wohl einige Serviervorschläge anfügen wollen.

Abbildung 2.1: Das Rezept für eine Bohnentunke auf einer Karteikarte
Wenn Sie eine XML-Datei auf der Grundlage eines vorhandenen Dokuments erzeugen, müssen Sie das Original genau untersuchen, um ein Verständnis von der Konstruktion der Instanz, die ausgezeichnet werden soll, zu erhalten. Das nennt man Dokumentanalyse und ist ein notwendiger Bestandteil des Auszeichnungsprozesses. Zur Auszeichnung des Rezepts für die Bohnentunke können Sie den Analyseschritt recht einfach halten. Zunächst identifizieren Sie die Rezeptkomponenten. Am ersten Tag haben Sie gelernt, dass die grundlegenden Bausteine Elemente genannt werden. Elemente müssen deklariert werden, wie die Substantive in einer Sprache, und sie fungieren als Container für Informationen, die Daten oder andere Elemente enthalten können. Später erfahren Sie, was die Elemente noch enthalten können.
Um die Elemente für das Bohnentunke-Rezept zu verstehen, betrachten Sie, was Sie mit den Element-Tags einschließen wollen. Für jede wichtige Rezeptkomponente müssen Sie die folgenden Dinge festlegen:
Abbildung 2.2 zeigt ein typisches Rezept als Blockdiagramm. Aus dem Diagramm können Sie ersehen, dass das rezept-Element ein Element namens titel sowie je eines namens zutaten, zubereitung und serviervorschlag enthält. Das zutaten-Element enthält abgeleitete posten-Elemente und entsprechende abgeleitete menge-Elemente.
Abbildung 2.3 zeigt eine weitere nützliche Ansicht von XML-Dokumenten. Sie zeigt das Rezept als Baumstruktur, die ein nützliches und bedeutendes Modell für XML darstellt.
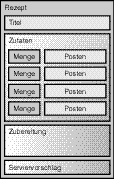
Abbildung 2.2: Ein Blockdiagramm strukturiert das Rezept für eine Bohnentunke.
![]()
Am 12. Tag werden Sie die Anwender-Programmierschnittstelle (API) kennen lernen, die in XML als Document Object Model (DOM) bekannt ist. Dieses API behandelt alle XML-Instanzen als Knotenbaum und bietet Ihnen als Programmierer eine Methode, Knoten und ihren Inhalt abzufragen, anzufügen, zu löschen und zu modifizieren.
Das Baumdiagramm zeigt das gleiche Verhältnis zwischen den Elementen wie das Blockdiagramm. Es gibt ein einziges Wurzelelement, rezept genannt, das als Container für alle anderen Elemente dient. Sehen Sie sich das Element zutaten genau an - es enthält die abgeleiteten Elemente menge und posten. Damit die XML-Instanz als wohl geformt gelten kann, müssen die abgeleiteten Elemente des Wurzel-Elements sowie alle Unterelemente sequenziell angeordnet oder ineinander eingebettet sein, ohne dass sich irgendwelche Tags überlappen. Später an diesem Tag werden Sie eine einfache Technik erlernen, wie man die korrekte Einbettung verifiziert, aber zunächst erzeugen Sie ein XML-Dokument für das Rezept der Bohnentunke, indem Sie unter Verwendung eines Texteditors den Code, der in den folgenden Schritten beschrieben wird, eingeben.
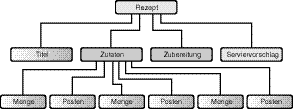
Abbildung 2.3: Ein Baumdiagramm für das Rezept der Bohnentunke
![]()
Eine wohl geformte XML-Instanz muss ein einziges Wurzelelement enthalten, das wiederum alle anderen Elemente enthält. Elemente, die im Wurzelelement enthalten sind, können abgeleitete Elemente haben, aber die Ableitungen müssen korrekt eingebettet sein. Alle Elemente, die das Wurzelelement enthält, sind Ableitungen von diesem.
Listing 2.1: Ein Dokument für ein Rezept in XML - bohnentunke.xml
1: <rezept>
2: <titel>Devans Bohnentunke</titel>
3: <zutaten>
4: <menge>1 Becher</menge>
5: <posten>gebackene Bohnen</posten>
6: <menge>1 Becher</menge>
7: <posten>Burrito-Sauce</posten>
8: <menge>150 gr</menge>
9: <posten>gewuerfelter Jalapeno-Kaese</posten>
10: <menge>1/2 Tasse</menge>
11: <posten>saure Sahne</posten>
12: </zutaten>
13: <zubereitung>Bohnen und Burrito-Sauce in Pfanne mittlerer
14: Groesse anheizen bis sie kochen, gewuerfelten
15: Kaese dazugeben und umruehren, bis er schmilzt.
16: Vom Herd nehmen und saure Sahne einruehren.</zubereitung>
17: <serviervorschlag>Als Tunke zu Tortilla-Chips aus Mais
18: servieren.</serviervorschlag>
19: </rezept>
Abbildung 2.4: Das Rezept für die Bohnentunke als wohl geformtes XML-Dokument, erzeugt mit einem Texteditor und mit dem Internet Explorer angezeigt
Am ersten Tag haben Sie die Teile eines Elements kennen gelernt und erfahren, dass Elemente ein Start- und ein Schluss-Tag umfassen sowie Inhalte haben können. XML-Tags berücksichtigen die Groß- und Kleinschreibung, anders als bei HTML; deshalb müssen Start- und Schluss-Tags hinsichtlich der Schreibweise identisch sein. In manchen Instanzen ist ein Element leer. In diesem Fall hat es keinen Elementinhalt und keine Daten zwischen dem Start- und dem Schluss-Tag. Die eckige Klammer (<) im Start-Tag wird in Auszeichnungssprachen auch als Eröffnung der Auszeichnungs-Deklaration (Markup Declaration Open, MDO) bezeichnet. Die abschließende eckige Klammer (>) im Schluss- Tag wird entsprechend Markup Declaration Close (MDC) genannt. Betrachten Sie das Element
<posten>saure Sahne</posten>.
Die Teile dieses Elements können so beschrieben werden, wie in Tabelle 2.1 angezeigt.
Markup Declaration Open (Eröffnung der Auszeichnungs-Deklaration) | |
Markup Declaration Close (Abschluss der Auszeichnungs-Deklaration) |
Tabelle 2.1: Anatomie Ihres posten-Elements
Das Einrücken der Zeilen, das Sie in Listing 2.1 gesehen haben, entspricht gutem Programmierstil. Werden abgeleitete Elemente eingerückt, ist es einfacher zu erkennen, um welche Einbettungsebene in einem XML-Dokument es sich handelt. Der zusätzliche Leerraum wird von den meisten XML-Prozessoren ignoriert und verursacht keine Probleme.
![]()
Leerräume zwischen den Elementen eines XML-Dokuments werden von vielen Parsern nach einem Zeichen normiert oder reduziert. Anders als HTML gibt XML aber Leerzeichen an den XML-Prozessor weiter, wenn welche angetroffen werden. Es ist die Aufgabe des Prozessors zu entscheiden, wie mit ihnen umgegangen werden soll.
Sie konnten am ersten Tag erfahren, dass der Internet Explorer (Version 5.0 oder höher) in der Lage ist, ein XML-Dokument auf dem Bildschirm mit verschiedenen Farben anzuzeigen, die den Elementnamen und dessen Inhalt wiedergeben. Dies ist möglich, weil dem Browser IE ein spezieller XML-Prozessor, der so genannte »Parser«, im Code der Browseranwendung eingebaut ist. Der Parser überprüft Ihr XML-Dokument, um sicherzustellen, dass es wohl geformt ist. Wenn dies der Fall ist, weist er der XML-Instanz ein eingebautes Stylesheet zu und führt dann mit XSLT eine Transformation durch.
Starten Sie den Internet Explorer und öffnen Sie die gespeicherte Version von bohnentunke.xml. Das Resultat sollte wie in Abbildung 2.5 aussehen.

Abbildung 2.5: Das Bohnentunken-Rezept als wohl geformtes XML-Dokument - mit einem Texteditor erstellt und im Internet Explorer betrachtet
Wenn der Internet Explorer auf Ihrem System installiert ist, steht Ihnen die Microsoft- Implementierung eines XML-Parsers zur Verfügung. Ein XML-Parser ist eine Software, welche die Regeln der Syntax für XML in der Version 1.0 kennt, wie sie vom W3C aufgestellt wurden. Der Parser kann ein XML-Dokument verarbeiten und die Übereinstimmung mit diesen Standards feststellen. XML-Parser spüren Ausnahmen auf und beenden die Verarbeitung, wenn eine der Syntaxregeln verletzt wird.
Alle XML-Parser überprüfen ein Dokument auf seine Wohl geformtheit. Morgen werden Sie Parser kennen lernen, die überprüfen, ob ein Dokument nicht nur wohl geformt, sondern auch gültig ist. Die Gültigkeit schließt eine zusätzliche Menge von Beschränkungen ein, die der Programmierer durch die Erstellung eines Schemas erzwingt, das die Struktur eines XML-Dokuments ausdrücklich festlegt. Auf diese Art kann ein Programmierer spezifizieren, welche Reihenfolge die Elemente in einem XML-Dokument haben, er kann die Präsenz erforderlicher Elemente festlegen und in einigen Fällen die Datentypen für den Elementinhalt validieren. Mehr dazu erfahren Sie morgen!
Der Test »Keine überkreuzten Linien« für die korrekte Einbettung stellt sicher, dass die Elemente entweder sequenziell angeordnet oder so eingebettet sind, dass sich Start- und Schluss-Tags nicht überschneiden. Ein XML-Dokument, das diese Regel nicht befolgt, ergibt für einen XML-Prozessor keinen Sinn. Sie wissen vielleicht, dass in HTML solche Einschränkungen nicht bestehen. In HTML geben die folgenden Codebeispiele in der Interpretation durch die meisten Browser genau die gleichen Resultate wieder:
<B><I>Dieser Text erscheint fett und kursiv</I></B>
<B><I>Dieser Text erscheint fett und kursiv</B></I>
Der erste Ausschnitt ist wohl geformt und sein Element für die Kursivschrift <I>...</I> ist als eine passende und vollständige Ableitung des Fettschriftelements <B>...</B> enthalten. Beim zweiten Codeausschnitt geht das Schluss-Tag für das Fettschriftelement </B> dem Schluss-Tag für Kursivschrift </I> voraus, womit es unpassend und nicht wohl geformt ist. Zieht man eine Linie zwischen <B> und </B> und eine zweite zwischen <I> und </I>, dann überschneiden sie sich beim zweiten Codeausschnitt, was ein Anzeichen für eine nicht korrekte Einbettung ist.
![]()
Wenn Sie für eine XML-Instanz eine Linie von den Start-Tags aller Elemente zu ihren entsprechenden Schluss-Tags ziehen, dürfen sich die Linien niemals überschneiden.
Abbildung 2.6 zeigt die Instanz bohnentunke.xml mit Linien, die zwischen den Start- und Schluss-Tags aller Elemente gezogen wurden. Keine dieser Linien überschneidet sich mit einer anderen, was eine korrekte Einbettung anzeigt.
Abbildung 2.6: Der Test »Keine überkreuzten Linien« für die korrekte Einbettung, angewendet auf das Dokument bohnentunke.xml
Die Namen, die Sie für das Rezeptdokument verwendet haben, waren einfach und beschreibend. Auch wenn XML von Computern gelesen wird, können Menschen es doch verstehen. Sie müssen einige Regeln für die Elementnamen in XML einhalten, etwa:
Sie haben mehrere einfache XML-Dokumente erstellt, die wohl geformt sind und vom Internet Explorer 5.0 geparst werden können. Auch wenn IE das XML so akzeptiert, entspricht es einem sauberen Programmierstil, eine Deklaration einzufügen, damit es sich bei dem Dokument um XML handelt. Einige Parser erfordern diese Verarbeitungsanweisung, die so genannte XML-Deklaration, sogar.
Fügen Sie Ihrem Dokument bohnentunke.xml eine XML-Deklaration vor dem Start-Tag für das Wurzelelement <rezept> an. Sie sieht folgendermaßen aus:
<?xml version="1.0">
Der vollständige Code für das Listing von bohnentunke.xml sieht nun so aus wie der Code in Listing 2.2. Beachten Sie, dass die XML-Deklaration in der ersten Zeile des Dokuments steht. Bearbeiten Sie Ihre Auszeichnungen für das Rezept und speichern das neue Dokument unter bohnentunke2.xml ab.
Listing 2.2: Die XML-Deklaration - bohnentunke2.xml
1<?xml version="1.0">
2: <rezept>
3: <titel>Devans Bohnentunke</titel>
4: <zutaten>
5: <menge>1 Becher</menge>
6: <posten>gebackene Bohnen</posten>
7: <menge>1 Becher</menge>
8: <posten>Burrito-Sauce</posten>
9: <menge>150 gr</menge>
10: <posten>gewuerfelter Jalapeno-Kaese</posten>
11: <menge>1/2 Tasse</menge>
12: <posten>saure Sahne</posten>
13: </zutaten>
14: <zubereitung>Bohnen und Burrito-Sauce in Pfanne mittlerer
15: Groesse anheizen bis sie kochen, gewuerfelten
16: Kaese dazugeben und umruehren, bis er schmilzt.
17: Vom Herd nehmen und saure Sahne einruehren.</zubereitung>
18: <serviervorschlag>Als Tunke zu Tortilla-Chips aus Mais
19: servieren.</serviervorschlag>
20: </rezept>
Die XML-Deklaration in Zeile 1 teilt einem XML-Prozessor mit, dass das Dokument, das geparst wird, ein XML-Dokument ist. Auch wenn einige Prozessoren diese Deklaration nicht verlangen, ist es ein guter Programmierstil, sie in Ihre XML-Dokumente einzuschließen.
Die Syntax einer XML-Deklaration unterscheidet sich ein wenig von der eines Elements. Diese Deklaration ist eine Verarbeitungsanweisung (Processing Instruction, PI), die spezielle Informationen für den XML-Parser bereitstellt und ihn darüber informiert, dass das folgende Dokument ein in der XML-Version 1.0 programmiertes Dokument der Extensible Markup Language ist. Die XML-Deklaration-PI befindet sich immer als erste Zeile im Prolog eines XML-Dokuments - wenn sie vorhanden ist. Sie werden an den folgenden Tagen noch weitere Verarbeitungsanweisungen kennen lernen. Tabelle 2.2 zeigt die Teilkomponenten der Anweisung für die XML-Deklaration.
Tabelle 2.2: Anatomie einer XML-Deklaration
Im Eröffnungssatz der XML-Verarbeitungsanweisung muss XML kleingeschrieben sein, damit die PI von XML-Parsern akzeptiert wird. Sie werden sehen, dass alle XML- Deklarationen derzeit die Version 1.0 angeben. Das ist so, weil es nur eine XML-Version gibt. Wahrscheinlich ändert sich das in Zukunft und daher ist die Versionsangabe ein erforderliches Attribut für die XML-Deklaration. Das encoding-Attribut wird verwendet, um Zeichencodes anzuzeigen, die weder UTF-8 noch UTF-16 sind.
![]()
UTF-8 und UTF-16 sind standardisierte Zeichencode-Schemata für Daten. UTF-16 ist auch als »Unicode« mit Auszeichnungen in Byte-Anordnung bekannt. Eine Besprechung der verschiedenen Zeichencode-Schemata würde den Rahmen dieser Lektion sprengen, aber Sie finden ausgezeichnete Informationen zu den Codes auf der Website des W3C (http://www.w3.org) oder unter http://msdn.microsoft.com/xml/articles/xmlencodings.asp.
Das Attribut standalone zeigt dem XML-Prozessor an, ob eine externe Document Type Definition (DTD) für die Validierung der Instanz zugewiesen werden soll oder nicht. Sie werden die XML-Validierung am dritten Tag kennen lernen. Meistens braucht XML, das nur wohl geformt sein soll, keine standalone-Dokument-Deklaration zu verwenden. Diese Deklarationen gibt es, um bestimmte, wenn auch geringfügige, Verarbeitungsvorteile zu erlangen.
Wie dies meistens bei der Programmierung der Fall ist, hat XML eine Vorrichtung für das Einfügen von Kommentaren in die Auszeichnungen. Anders als Kommentare in anderen Sprachen können XML-Kommentare auch XML-Prozessoren übergeben werden. Anders gesagt, wie Sie am 12. Tag sehen werden, an dem Sie das Document Object Model entdecken, können Sie Kommentare in einem XML-Dokument programmgesteuert abfragen und bearbeiten oder sie als Teil Ihrer Verarbeitungsprozedur verwenden.
Kommentare in einer XML-Instanz nehmen die gleiche Form wie in HTML an, etwa:
<!--Dies ist ein Kommentar-->
Verwenden Sie Ihren Editor dazu, einen Kommentar in Ihr Dokument bohnentunke2.xml zu platzieren, der Sie daran erinnern soll, dass man der Bohnentunke eine scharfe Soße beifügen kann. Platzieren Sie den Kommentar vor das Element serviervorschlag und zeigen Sie das Resultat dann mit dem Internet Explorer 5.0 an. Fügen Sie den folgenden Kommentar genau vor dem Element serviervorschlag in Ihren Code ein:
<!--Fuer eine besonders scharfe Bohnentunke fuegen Sie der Mischung Ihre bevorzugte scharfe Sosse hinzu-->
Abbildung 2.7 zeigt das Resultat, die Anzeige Ihres Codes mit dem Internet Explorer. Beachten Sie, dass der XML-Parser in IE5 den eigentlichen Kommentartext als anders eingefärbten Typ anzeigt, nachdem er die XSL-Transformation für Sie durchgeführt hat. Am 3. und 12. Tag werden Sie lernen, dass der Kommentartext in einem Kommentar- Knoten als Teil der XML-Instanz abgelegt ist.
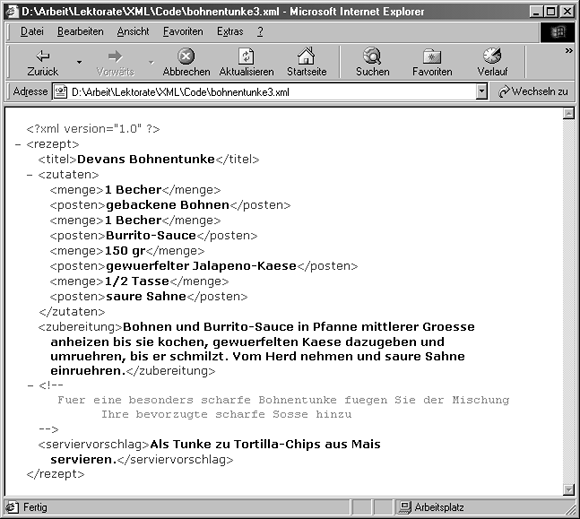
Abbildung 2.7: Dem Dokument bohnentunke2.xml wird ein Kommentar beigefügt.
Sie haben am ersten Tag erfahren, dass sich Attribute wie die Adjektive in einer gesprochenen Sprache verhalten und Elemente modifizieren, die wiederum den Nomina entsprechen. In XML werden Attribute immer im Start-Tag des Elements platziert, zu dem sie zusätzliche Informationen liefern.
Mit einem Editor modifizieren Sie Ihr Dokument bohnentunke.xml so, dass der Titel ein Attribut des Wurzel-Elements rezept wird und jede der Mengen ein Attribut des Postens, den sie modifizieren. Wenn Sie damit fertig sind, sollte es sich immer noch um ein wohl geformtes Dokument handeln. Die Syntax für ein Attribut zu einem Element lautet
<element_name -Attribut_name="wert">elementinhalt</element_name>.
Attribute werden immer im Start-Tag des Elements, das genauer bestimmt wird, deklariert. Es ist eine beliebige Anzahl von Attributen für ein Element erlaubt und jedes davon wird im Start-Tag abgelegt, zum Beispiel:
1: <element_name
2: -Attribut_name1="wert"
3: -Attribut_name2="wert"
4: -Attribut_name3="wert">elementinhalt</element_name>
Manchmal, wenn die Auszeichnung lang wird, kann Ihr Code einfacher zu lesen sein, wenn Zeilenumschaltungen verwendet werden und ähnliche Elemente mit Einrückungen ausgerichtet werden. Alle vier Zeilen des Beispiels mit mehreren Attributen sind immer noch genau einem Element zugeordnet, auch wenn sie vier Zeilen eines Dokuments umfassen. In XML werden die zusätzlichen »Leerraum«-Zeichen nach dem ersten normiert. Das bedeutet, sie werden von dem Prozessor, der über die zusätzlichen Leerräume hinwegläuft, weggelassen oder ignoriert.
![]()
Denken Sie daran, dass Sie verifizieren können, ob Ihr Dokument wohl geformt ist, wenn Sie es mit dem Internet Explorer 5.0 parsen.
Listing 2.3: Wohl geformte Attribute in einer XML-Instanz:
bohnen_tunke3.xml
1: <?xml version="1.0"?>
2: <rezept titel="Devans Bohnentunke">
3: <zutaten>
4: <posten menge="1 Tasse">gebratene Bohnen</posten>
5: <posten menge="1 Tasse">Burrito-Sauce</posten>
6: <posten menge="150 gr">gewuerfelter Jalapeno-Kaese</posten>
7: <posten menge="1/2 Tasse">saure Sahne</posten>
8: </zutaten>
9: <zubereitung>Bohnen und Burrito-Sauce in Pfanne mittlerer
15: Groesse anheizen bis sie kochen, gewuerfelten
16: Kaese dazugeben und umruehren, bis er schmilzt.
17: Vom Herd nehmen und saure Sahne einruehren.</zubereitung>
13: <!--Fuer eine besonders scharfe Bohnentunke fuegen Sie der
14: Mischung Ihre bevorzugte scharfe Sosse zu -->
15: <serviervorschlag>Als Tunke mit Tortilla-Chips
16: aus Mais servieren</serviervorschlag>
17: </rezept>
Beachten Sie, dass jedes der Attribute sich tatsächlich im Start-Tag des Elements befindet, das es modifiziert. Beachten Sie auch, dass die Attributswerte in Anführungszeichen eingeschlossen sind. Einfache oder doppelte Anführungszeichen können dafür verwendet werden, aber damit die Instanz wohl geformt ist, müssen alle Attributswerte in Anführungszeichen stehen.
XML-Parser kennen kein Pardon, wenn Verletzungen der Syntaxregeln vorliegen. Zum Beweis müssen Sie nur das erste Anführungszeichen von einem der Attributswerte im Dokument bohnentunke.xml entfernen. Nach dieser Veränderung parsen Sie das Dokument, indem Sie es in den Internet Explorer laden. Wenn Sie zum Beispiel das erste Anführungszeichen des menge-Werts für das posten-Element in Zeile 4 von Listing 2.3 entfernen, wird eine Fehlermeldung vom Internet Explorer zurückgegeben, die folgendermaßen aussieht:
A string literal was expected, but no opening quote character was found. Line 4, Position 23
<posten menge=1 Tasse">gebratene Bohnen</posten>
----------------------^
Als nächstes enfernen Sie das erste Anführungszeichen um den Attributswert sowie sein Schlusszeichen. In diesem Fall gibt der IE eine andere Meldung zurück. Der Parser erkennt ein Problem mit dem Attributswert, weil er dessen abschließendes Anführungszeichen nicht findet, bevor er zum nächsten Markup-Zeichen, das die Deklaration eröffnet (<), kommt. Um den Bedingungen der Wohlgeformtheit zu entsprechen, müsste die Zeile, in der das Problem auftritt, so aussehen:
<posten menge="1 Tasse">gebratene Bohnen</posten>
Heute haben Sie die Syntaxregeln kennen gelernt, die wohl geformtes XML charakterisieren. Sie haben entdeckt, dass der Browser Internet Explorer von Microsoft 5.0 und höher über einen eingebauten XML-Parser verfügt, der überprüfen kann, ob Ihre Dokumente wohl geformt sind.
Morgen werden Sie lernen, wie gültiges XML aussieht und wie Sie als Programmierer die Struktur eines XML-Dokuments über die Beschränkungen der Wohlgeformtheit hinaus bestimmen können.
Frage:
Wie unterscheiden sich XML und HTML hinsichtlich der grundlegenden Syntaxregeln?
Antwort:
Damit ein XML-Dokument wohl geformt ist, muss es allen Syntaxregeln, die vom
W3C als Teil der Spezifikation von XML, Version 1.0, aufgestellt wurden,
entsprechen. Ein XML-Dokument, das nicht wohl geformt ist, wird als beschädigt
betrachtet und kann von einem Parser oder Browser nicht vollständig verarbeitet
werden. In HTML gibt es zwar Syntaxregeln, aber die Browser setzen sie nicht
immer rigoros durch.
Frage:
Welche Werkzeuge braucht man zum Erzeugen wohl geformter XML-Dokumente?
Antwort:
Alles was erforderlich ist, ist ein Texteditor und ein Parser, der die Einhaltung der
Beschränkungen durch die Wohlgeformtheit sicherstellt.
Frage:
Warum ist der Analyseschritt für XML-Entwickler wichtig?
Antwort:
Es ist äußerst wichtig, die Elemente einer Dokumentstruktur zu verstehen, um
sicherzugehen, dass sie korrekt ausgezeichnet werden können. Der Entwickler
muss wissen, wo jedes Element beginnt und wo es endet, welchen Zweck es hat,
welcher Inhalt in einem Element enthalten ist und welche Beziehung zwischen
allen Elementen einer XML-Instanz bestehen.
Frage:
Welches sind die grundlegenden Syntaxregeln, die wohl geformtes XML charakterisieren?
Antwort:
Die wichtigsten Regeln sind:
Frage:
Wie lautet die Syntax für einen Kommentar in einem XML-Dokument?
Antwort:
<!--Dies ist ein Kommentar-->
Die Übung soll Ihre Kenntnis dessen, was Sie heute gelernt haben, überprüfen. Die Lösung finden Sie in Anhang A.
Listing 2.4 zeigt eine schlecht geformte XML-Instanz. Die Absicht hinter diesem Dokument ist es, zwei Musikalben und Details zu jedem Titel aufzulisten. Korrigieren Sie dieses Dokument unter Verwendung eines Editors auf Grundlage all der Dinge, die Sie über die XML-Syntax gelernt haben. Testen Sie Ihre Korrekturen, indem Sie das Dokument mit dem Internet Explorer 5.0 von Microsoft parsen.
Listing 2.4: Ein schlecht geformtes XML-Dokument
<?XML version=1.0?>
<cd nummer="432>
<titel>Das Beste von Van Morrison</Titel>
<kuenstler>Van Morrison</kuenstler
<stuecke gesamt=20">
<cd nummer=97>
<titel>HeartBreaker</titel>
<Untertitel>Sixteen Classic Performances</untertitel>
<kuenstler>Pat Benatar</Kuenstler>
<stuecke gesamt=16>
</CD>
